- The paper introduces iLRM, an iterative refinement model that decouples scene representation from input images to reduce computational costs in 3D reconstruction.
- It employs a two-stage attention mechanism with token uplifting and mini-batch strategies to integrate high-resolution cues effectively.
- Empirical results demonstrate improvements of 3–4 dB in PSNR and reduced computation time compared to state-of-the-art methods.
Iterative Large 3D Reconstruction Model (iLRM): Architecture, Scalability, and Empirical Analysis
Introduction and Motivation
The iLRM framework addresses critical limitations in feed-forward 3D Gaussian Splatting (3D-GS) models, particularly their scalability and representational efficiency. Existing transformer-based approaches for generalizable 3D reconstruction suffer from quadratic computational complexity with respect to the number of input views and image resolution, primarily due to full attention across all image tokens. Moreover, pixel-aligned Gaussian generation leads to excessive redundancy, as the number of Gaussians is tightly coupled to image resolution, often far exceeding the minimal set required for accurate scene representation.
iLRM introduces an iterative refinement mechanism, decoupling the scene representation from input images and decomposing multi-view interactions into a two-stage attention scheme. This design enables efficient utilization of high-resolution image cues while maintaining a compact set of 3D Gaussians, facilitating both high-fidelity reconstruction and superior scalability.
Figure 1: The overall architecture and qualitative results of the proposed iLRM.
Architectural Design
Decoupling and Tokenization
iLRM initializes scene representation using viewpoint-centric embeddings derived from Plücker ray coordinates, which encode spatial and directional information for each camera pose. These embeddings are partitioned into non-overlapping patches and linearly projected to form viewpoint tokens. Multi-view images are similarly tokenized by concatenating RGB patches with corresponding Plücker ray patches, followed by linear projection.
Scalable Multi-View Context Modeling
The core architectural innovation lies in the two-stage attention mechanism:
- Per-View Cross-Attention: Each viewpoint token interacts only with its corresponding image tokens, drastically reducing the computational cost compared to full multi-view attention.
- Global Self-Attention: Viewpoint tokens are refined via self-attention, enabling global information exchange across views. Operating in a low-resolution embedding space ensures tractability even with many input views.
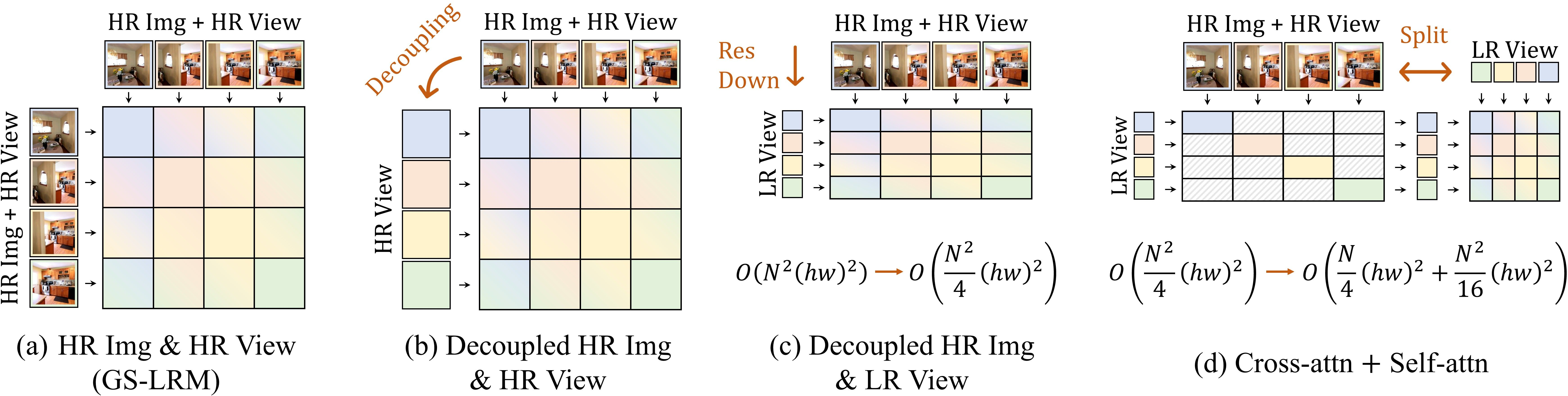
Figure 2: The proposed scalable architectural designs by decoupling viewpoint and image tokens, and modeling the global interactions via cross- and self-attentions (N: number of views, h=H/p, w=W/p).
Token Uplifting and Mini-Batch Cross-Attention
To bridge the resolution gap between low-resolution viewpoint tokens and high-resolution image tokens, iLRM employs a token uplifting strategy: each viewpoint token is expanded into multiple finer-grained queries before cross-attention, then compressed back post-attention. This mechanism preserves spatial correspondence and enables effective integration of high-resolution cues.
Mini-batch cross-attention schemes further enhance scalability by sampling subsets of tokens during cross-attention, analogous to mini-batch gradient descent. Structured sampling strategies are adopted for efficient implementation without significant performance degradation.
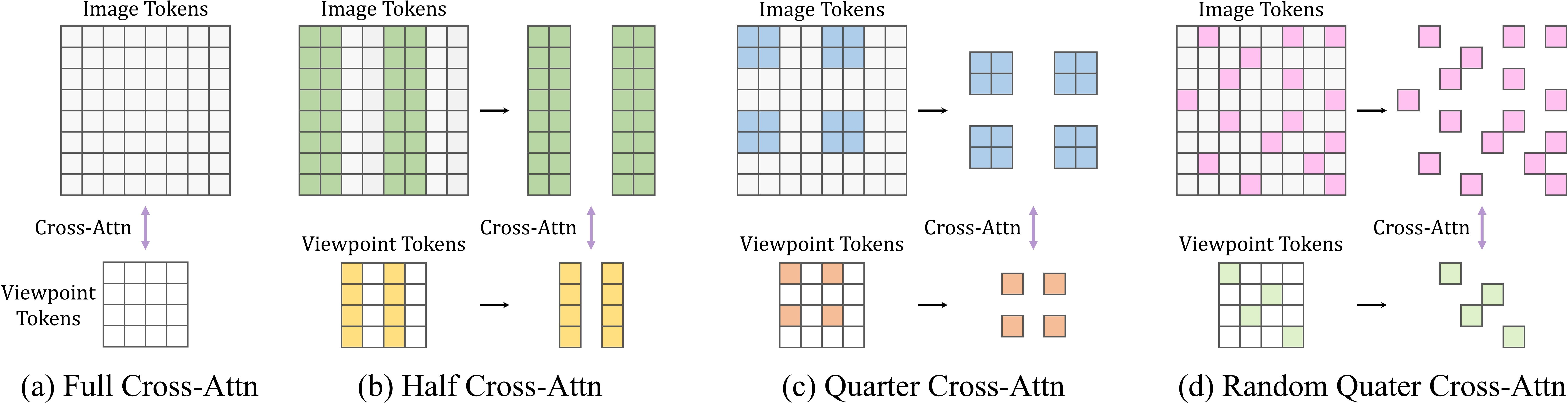
Figure 3: Various mini-batch cross-attention schemes.
Iterative Refinement
The network stacks multiple update blocks, each comprising a cross-attention layer followed by a self-attention layer. At each layer, viewpoint tokens are iteratively refined, mimicking the feedback-driven optimization process of per-scene methods. The final viewpoint tokens are decoded into Gaussian parameters via a linear layer.
Training Objectives and Implementation
iLRM is trained using a combination of MSE and perceptual loss (VGG-based), supervising rendered images against ground-truth targets. The architecture leverages FlashAttention-2 for efficient attention computation, gradient checkpointing for memory savings, and mixed-precision training (BFloat16). Camera pose normalization ensures consistent scene alignment.
Empirical Results
On the RE10K dataset, iLRM achieves a PSNR improvement of approximately 3 dB over state-of-the-art baselines (GS-LRM, DepthSplat) when leveraging more views (8 vs. 2) at less than half the computation time (0.028s vs. 0.065s). On DL3DV, iLRM improves PSNR by ~4 dB under comparable computational budgets, efficiently utilizing up to four times more views.
Qualitative Analysis
iLRM consistently produces sharper novel view synthesis with fewer artifacts compared to baselines, as demonstrated on both RE10K and DL3DV datasets.

Figure 4: Qualitative comparison of novel view synthesis on the RE10K dataset.

Figure 5: Qualitative comparison of novel view synthesis on the DL3DV dataset.

Figure 6: Qualitative comparison of novel view synthesis on the high-resolution (512×960) DL3DV dataset.
Scalability and Efficiency
The decoupling of viewpoint and image tokens allows iLRM to generate compact Gaussian sets while leveraging high-resolution images, outperforming baselines under identical output density and requiring less computational resources. Mini-batch cross-attention reduces training FLOPs by up to 4.7× with only marginal drops in reconstruction quality.
Ablation Studies
Increasing the number of update layers yields consistent performance gains, confirming the efficacy of iterative refinement. Token uplifting and self-attention are critical for capturing fine-grained spatial correspondences and global dependencies, respectively. Group-attention variants incur higher computational cost without performance benefits, validating the two-stage attention design.
Limitations
While iLRM significantly reduces computational overhead, self-attention across many views remains a bottleneck as input size grows. The requirement for known camera poses limits applicability to raw video datasets; extending iLRM to pose-free settings is a promising direction. Hierarchical or sparse attention mechanisms may further enhance scalability.
Implications and Future Directions
iLRM demonstrates that iterative refinement and decoupled representations are essential for scalable, high-quality feed-forward 3D reconstruction. The architecture is well-suited for large-scale, real-time applications and generalizes robustly across diverse scenes and viewpoint configurations. Future work should explore pose-free reconstruction, efficient attention alternatives, and integration with foundation models for further generalization.
Conclusion
iLRM establishes a new paradigm for feed-forward 3D reconstruction by combining iterative refinement, decoupled scene representation, and scalable attention mechanisms. The empirical results substantiate its superiority in both reconstruction quality and computational efficiency. The framework provides a solid foundation for future research in scalable, generalizable 3D scene modeling.