- The paper introduces a novel RL-based framework that enables LLMs to autonomously decide when and which external tools to invoke, effectively balancing intrinsic capabilities with augmented reasoning.
- It employs a dual reward mechanism—action and output rewards via Group Relative Policy Optimization—to optimize both tool-use efficiency and final answer accuracy.
- Evaluation demonstrates significant gains in tool selection accuracy and reasoning performance across diverse tasks, validating the framework's scalability and practical impact.
Introduction
AutoTIR introduces an autonomous framework for enhancing reasoning in LLMs by integrating external tools through reinforcement learning. This methodology diverges from the conventional static tool-use templates, providing a dynamic system that judiciously selects tools based on task demands, thereby maintaining the core capabilities of LLMs while extending their reasoning capabilities.
Overall Framework of AutoTIR
The AutoTIR framework operates by allowing LLMs to autonomously determine when and which tools to invoke, significantly differing from prior approaches with fixed tool invocation strategies (Figure 1). This framework incorporates a hybrid reward mechanism focused on optimizing task-specific correctness and tool-use efficiency. The reward system is bifurcated into:
- Action Reward: This component guides the model in deciding whether a tool invocation is necessary, promoting correct tool selection while penalizing unnecessary or incorrect invocations.
- Output Reward: This element encourages the model to achieve high accuracy in the final output through effective integration of tool-derived results.
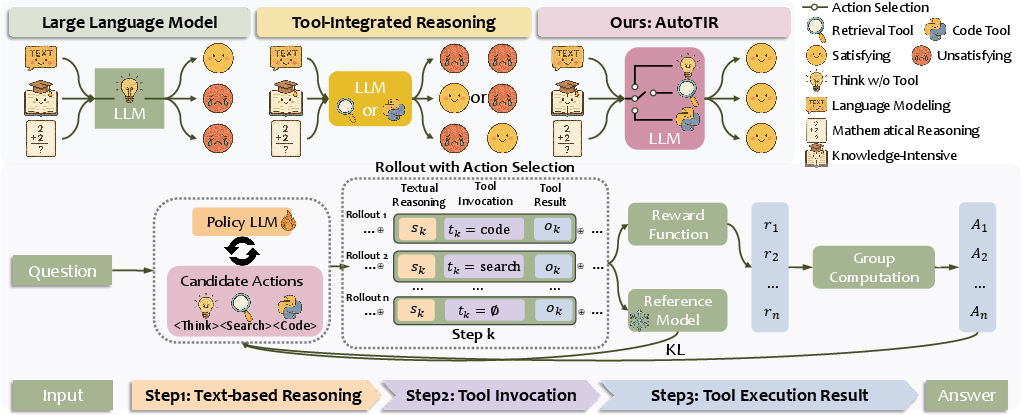
Figure 1: Overall framework of AutoTIR. Top: Comparison between AutoTIR and existing paradigms (fixed reasoning strategy vs.\ autonomous decision). Bottom: GRPO training pipeline that incorporates multiple reasoning actions.
Methodology
AutoTIR employs a reinforcement learning approach where LLMs explore tool-use strategies across diverse tasks. The action space involves deciding on tool invocation dynamically, adapting to the complexity of each task. This flexibility enables a balance between maintaining core linguistic capabilities and leveraging tools for enhanced reasoning.
The RL agent is trained via Group Relative Policy Optimization (GRPO), optimizing decisions by evaluating rewards derived from both tool effectiveness and final answer accuracy. This strategy enables AutoTIR to generalize across multiple task domains, outperforming static tool-use methods.
AutoTIR has been evaluated across various datasets, demonstrating significant improvements over baselines in both knowledge-intensive and mathematical domains. Metrics include Exact Match (EM) for QA tasks, standard Accuracy for logical reasoning, and Soft Accuracy (SAcc) for instruction adherence tasks. The results highlight AutoTIR's ability to effectively utilize tools when beneficial, without compromising fundamental language skills, as shown by maintaining high SAcc scores.
In dissecting tool utilization efficiency, AutoTIR exhibits superior performance in both tool selection accuracy (TS) and tool productivity (TP), particularly in complex reasoning tasks. This efficacy stems from its ability to minimize unnecessary tool usage while maximizing the contribution of invoked tools to problem solving.
(Table 1 and Figure 2)
Figure 2: Model Performance and Tool Advantage Across Reasoning Task Types.
Scalability and Training Dynamics
The training process demonstrates a consistent increase in both action and output rewards, indicating the model's growing proficiency in integrating tools and generating solutions. As training progresses, the response length increases, suggesting more complex reasoning trajectories are being explored (Figure 3).
Figure 3: Avg. reward score and response length during training.
Conclusion
AutoTIR represents a substantial advancement in tool-integrated reasoning for LLMs, offering a flexible, adaptive strategy that respects the model's intrinsic capabilities while enhancing its reasoning power. This method not only improves performance across diverse tasks but also lays the groundwork for future developments in scalable, adaptive AI systems capable of sophisticated, real-time problem-solving across a wide array of domains. By utilizing reinforcement learning, AutoTIR ensures that tool-use strategies evolve organically, optimizing both efficiency and effectiveness in reasoning tasks.