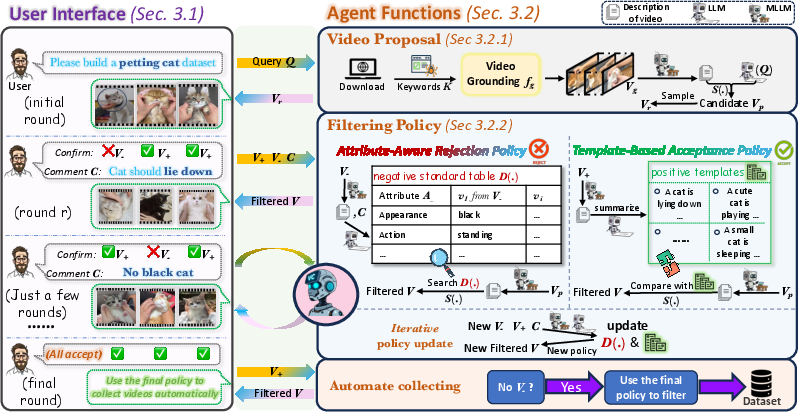
- The paper introduces a dual-policy interactive framework that leverages MLLM and iterative user feedback to refine video dataset collection.
- The system employs attribute-aware rejection and template-based acceptance policies to filter and rank video clips, achieving superior IoU scores compared to traditional methods.
- Experimental results show that VC-Agent accelerates dataset curation, enhances downstream tasks like text-to-video generation, and scales efficiently with minimal user input.
VC-Agent: An Interactive Agent for Customized Video Dataset Collection
Introduction and Motivation
The VC-Agent framework addresses the escalating demand for scalable, high-quality, and domain-specific video datasets, which are essential for advancing video understanding, generation, and related tasks. Manual curation of such datasets is prohibitively labor-intensive, especially when requirements are complex or highly personalized. VC-Agent introduces an interactive, multimodal LLM (MLLM)-based agent that iteratively refines user requirements and automates the retrieval and filtering of relevant video clips from web-scale sources, minimizing user effort while maximizing dataset quality and specificity.
System Architecture
VC-Agent is architected as a two-part system: a user-facing interface and a backend agent function module.
User Interface and Interaction Design
The web-based UI is designed for accessibility and efficiency, allowing untrained users to operate the system with minimal friction. Users input queries, review returned video samples, and provide feedback through simple retain/discard actions and optional comments. The system tracks all interactions and updates filtering policies accordingly.
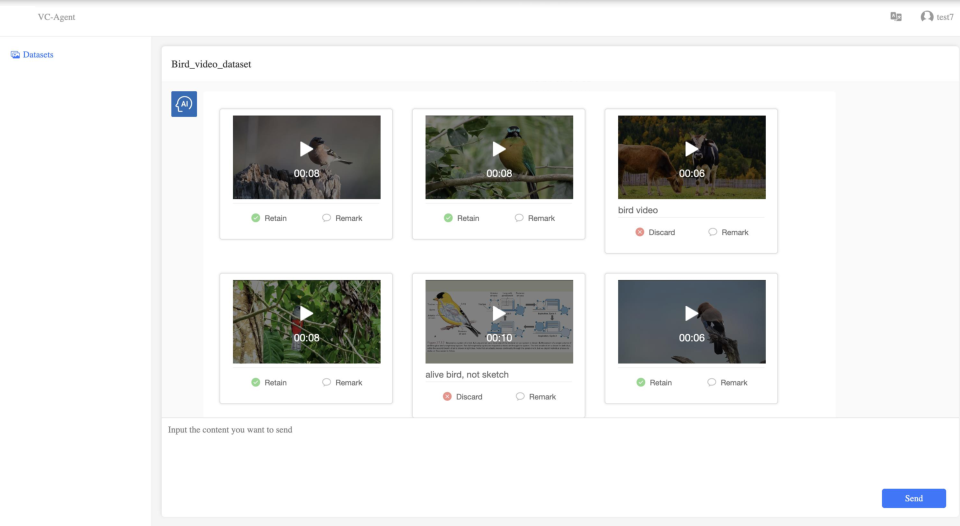
Figure 2: The web-based user interface, enabling users to submit queries, review video samples, and provide feedback for iterative refinement.
Video Retrieval and Grounding
Upon receiving a user query, VC-Agent generates search keywords via LLM prompting and employs a web crawler to retrieve candidate videos. To address the prevalence of irrelevant content, the system applies temporal and spatial grounding models (TFVTG and Grounding DINO) to extract segments most relevant to the query. Candidate videos are then ranked by similarity to the user’s requirements using MLLM-based descriptors.
Iterative Filtering Policies
Attribute-Aware Rejection Policy
User comments on rejected videos are parsed to extract attribute-specific rejection criteria (e.g., "no black cat", "cat should lie down"). These are summarized into a negative standard table. For each candidate video, the agent uses MLLM to generate attribute-specific descriptions and compares them against the table, discarding videos that match any negative criteria.
Template-Based Acceptance Policy
Accepted videos are described by MLLM and aggregated into positive criterion templates. Candidate videos passing the rejection filter are compared against these templates, and those with high similarity are retained.
Policy Update and Double-Check Strategy
Policies are updated in each interaction round, incorporating new confirmations and comments. To enhance robustness, a double-check strategy is employed: videos with low confidence scores are buffered and periodically presented to the user for additional review, focusing attention on ambiguous attributes.

Figure 3: Overview of the user-assisted double-check strategy, which improves robustness by soliciting user feedback on low-confidence samples.
Benchmarking and Experimental Results
VC-Agent is evaluated on a newly proposed Personalized Video Collection Benchmark (PVB), comprising 10,000 annotated videos across three domains, each with five distinct requirements. The benchmark is designed to test the agent’s ability to handle complex, multi-attribute queries beyond the scope of traditional video retrieval tasks.
Quantitative results demonstrate that VC-Agent consistently outperforms state-of-the-art video retrieval and MLLM baselines (e.g., InternVideo-L, VAST, GRAM, LLAVA-OneVision-7B), especially as the number and specificity of requirements increase. The agent maintains high IoU scores even under stringent multi-attribute constraints, whereas baseline methods degrade rapidly.

Figure 4: Progressive filtering results as requirements are incrementally added, showing VC-Agent’s superior performance compared to MLLM and video retrieval baselines.
Ablation Studies
Ablation experiments confirm the necessity of each module. Removing either the rejection or acceptance policy, attribute-aware or template-based mechanisms, or iterative updates results in significant performance drops, especially under complex requirements. The double-check strategy further improves accuracy and robustness.
Real-World User Studies
Eight participants constructed over 335,000 video samples across diverse domains using VC-Agent, with high satisfaction rates and substantial reductions in manual collection time. Typically, 10 interaction rounds (including 1–3 double-check rounds) suffice for high-quality dataset construction. System Usability Scale (SUS) scores indicate strong usability and user satisfaction.
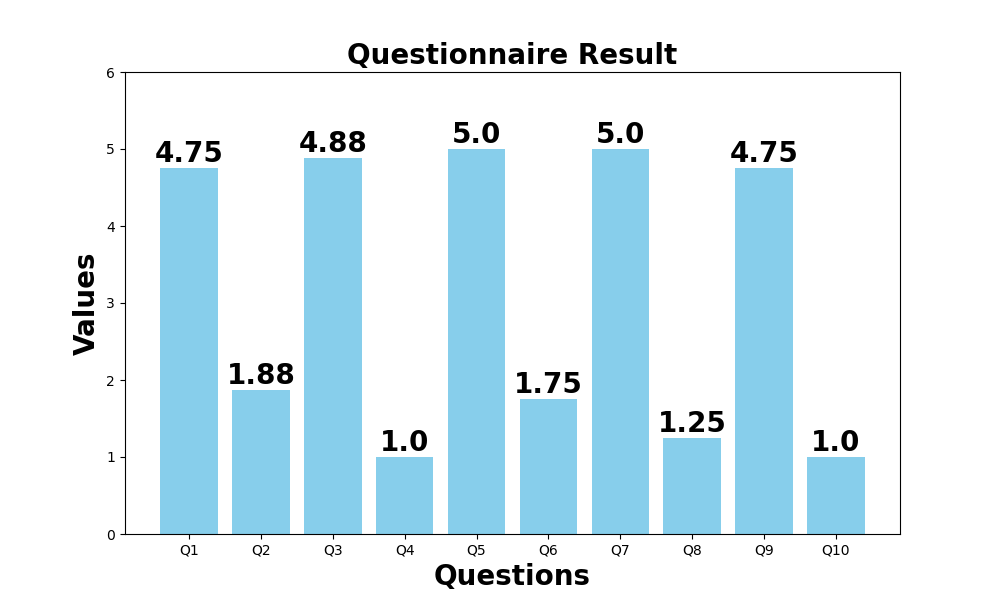
Figure 5: SUS questionnaire results, indicating high user satisfaction with VC-Agent’s effectiveness and efficiency.
Downstream Task Impact
Finetuning state-of-the-art models on datasets collected by VC-Agent yields measurable improvements in specialized tasks:
- Text-to-Video Generation: Finetuning CogVideoX with VC-Agent data improves metrics such as CLIPScore, HPSv2, temporal flickering, and subject consistency compared to both baseline and LLAVA-OneVision-7B-collected data.


Figure 6: Qualitative results for text-to-video generation, showing improved realism and detail when finetuned on VC-Agent data.
Scalability, Efficiency, and Limitations
VC-Agent achieves high-quality dataset construction with minimal user input and scales efficiently to large datasets (up to 80k samples). The system incurs higher computational cost per video (1.53s) compared to traditional retrieval (0.42s), but this is offset by superior generalization and specificity. Limitations include reduced performance on highly complex or ambiguous requirements (e.g., multi-view shots, transient object movements), which are primarily constrained by current MLLM capabilities.

Figure 8: Failure cases observed during user studies, highlighting challenges in distinguishing highly realistic virtual scenes and transient object movements.
Implications and Future Directions
VC-Agent demonstrates that interactive, MLLM-driven agents can dramatically accelerate the construction of customized video datasets, enabling rapid adaptation to specialized domains and tasks. The dual-policy filtering mechanism and iterative user feedback loop are effective for capturing nuanced requirements. Future work may focus on improving MLLM grounding for complex attributes, optimizing computational efficiency, and extending the framework to additional modalities and annotation types.
Conclusion
VC-Agent establishes a robust paradigm for interactive, scalable, and high-quality video dataset collection. By integrating multimodal reasoning, iterative policy refinement, and user-centric design, it enables efficient construction of domain-specific datasets that directly benefit downstream model performance. The framework’s extensibility and empirical results suggest broad applicability across video-centric AI research and industry applications.