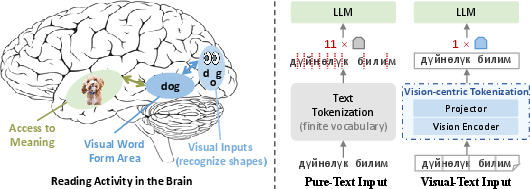
See the Text: From Tokenization to Visual Reading
Abstract: People see text. Humans read by recognizing words as visual objects, including their shapes, layouts, and patterns, before connecting them to meaning, which enables us to handle typos, distorted fonts, and various scripts effectively. Modern LLMs, however, rely on subword tokenization, fragmenting text into pieces from a fixed vocabulary. While effective for high-resource languages, this approach over-segments low-resource languages, yielding long, linguistically meaningless sequences and inflating computation. In this work, we challenge this entrenched paradigm and move toward a vision-centric alternative. Our method, SeeTok, renders text as images (visual-text) and leverages pretrained multimodal LLMs to interpret them, reusing strong OCR and text-vision alignment abilities learned from large-scale multimodal training. Across three different language tasks, SeeTok matches or surpasses subword tokenizers while requiring 4.43 times fewer tokens and reducing FLOPs by 70.5%, with additional gains in cross-lingual generalization, robustness to typographic noise, and linguistic hierarchy. SeeTok signals a shift from symbolic tokenization to human-like visual reading, and takes a step toward more natural and cognitively inspired LLMs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way for AI models to read text called SeeTok. Instead of breaking text into tiny pieces called “tokens,” it turns the text into an image and has the model “see” the words like a human does. This helps the model handle different languages better, be more robust to typos, and use fewer computational resources.
Goals and Questions
The paper asks simple but important questions:
- Can AI models read text visually (as images) instead of splitting it into many small text tokens?
- Will this make them more efficient, especially for languages with fewer training data?
- Can visual reading make models more robust to typos, strange fonts, or visual noise?
- Does this help models understand language structure (like how letters form words) more naturally?
How Did They Do It?
The researchers built SeeTok, which changes how text is fed into a model:
- First, the text is rendered as an image, like a screenshot of the words. Think of it as writing the sentence on digital “paper.”
- A vision encoder (a part of a multimodal AI model trained to understand images) looks at this picture and extracts features from small chunks of it, like cutting the image into small squares and understanding each one. This is similar to how you might scan a page with your eyes, noticing letter shapes and word patterns.
- A small neural network (called an MLP projector) then combines nearby image squares and converts them into a format the LLM can understand. You can think of this projector as a translator that turns visual features into “language features.”
- Because the model wasn’t originally trained to follow instructions shown as images, the researchers lightly fine-tuned it using LoRA adapters. LoRA is a way to add small, efficient “tuning knobs” to a big model without retraining it from scratch.
- The model they used is a multimodal LLM (MLLM), which means it can handle both images and text. It already has strong OCR abilities, which is the skill of reading text from images.
Key terms explained in everyday language:
- Tokenization: Splitting text into smaller pieces (tokens) before feeding it to a model.
- Subword tokenization: Breaking words into parts like “com-”, “put-”, “er” to handle rare words. This can over-split words in some languages.
- OCR: Optical Character Recognition. The ability to read text from images, like scanning a document.
- Multimodal: A model that can process more than one type of input, such as text and images.
- LoRA: A lightweight way to fine-tune big models by adding small, trainable layers.
- FLOPs: A measure of how much computation a model needs. Fewer FLOPs mean faster and cheaper processing.
- Fertility: The average number of tokens used per word. Lower fertility means fewer tokens and more efficiency.
Main Findings and Why They Matter
The authors tested SeeTok on question answering, general knowledge tests, sentiment analysis, and translation across many languages. Here are the key results:
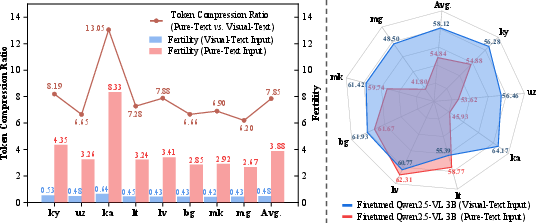
- Efficiency: SeeTok used about 4.43 times fewer tokens and reduced computation by around 70.5%. It also lowered latency (response time) by about a third. This is great for faster and cheaper AI.
- Accuracy: On several language tasks, SeeTok matched or beat the standard text-based approach. It did especially well on tasks where details like spelling and punctuation matter.
- Multilingual strength:
- For high-resource languages (like German, Chinese, Russian), SeeTok improved translation quality while using far fewer tokens per word.
- For low-resource languages (like Kyrgyz and Georgian), SeeTok was much more efficient and delivered better translations than normal text tokenization, which often over-splits words into many tiny pieces.
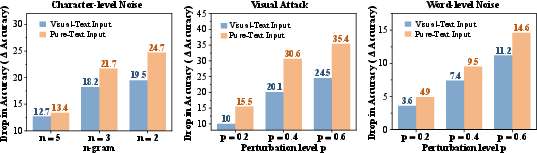
- Robustness to noise: SeeTok was more stable when the input had typos, scrambled letters, look-alike characters, or word-level changes. Because it looks at the overall shape of words, small changes don’t break the representation as badly.
- Understanding structure: SeeTok’s visual embeddings captured how sub-parts of words combine into whole words more naturally than text tokenization. This suggests it “gets” the hierarchy from letters to words better.
Implications and Potential Impact
This work suggests a shift in how AI models could read text—from symbol-based splitting to human-like visual reading. The benefits include:
- Fairness across languages: Visual reading doesn’t depend on having a giant token vocabulary that favors popular languages.
- Better robustness: Typos, fonts, and unusual scripts are less damaging when the model sees the overall word shape.
- Higher efficiency: Fewer tokens and lower computation make models faster and cheaper to run.
- More natural understanding: Capturing word shapes and layouts can help models learn language structure in a human-like way.
In short, SeeTok shows that treating text as something you “see” rather than something you “chop up” can make AI LLMs more efficient, more reliable, and better across many languages. This could inspire future models to unify text and vision processing for more natural and powerful reading and reasoning.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of missing pieces and unresolved questions that future work could address:
- Scaling and pretraining
- How does large-scale pretraining on visual-text corpora (beyond small LoRA tuning) affect knowledge-intensive tasks (e.g., MMLU), scaling laws, and cross-domain generalization?
- What is the minimal data/compute needed to close the “world-knowledge” gap observed when inputs are routed through the vision pathway?
- Rendering pipeline sensitivity
- Sensitivity to font family, size, weight (bold/italic), kerning, ligatures, anti-aliasing, and color schemes is not quantified; does performance degrade under substantial font variation?
- Robustness to complex scripts requiring shaping and contextual forms (Arabic, Urdu), diacritics (Vietnamese), abugidas (Devanagari), scripts without whitespace (Thai), right-to-left and vertical writing, and mixed-script text remains untested.
- Generalization from synthetic rendering to real-world text in the wild (camera-captured, print–scan, noise, blur, compression artifacts, backgrounds) is not evaluated.
- Long-context handling and streaming
- The method fixes M=1 during training and relies on variable resolution; how does it scale to long documents requiring multiple panels (M>1), line breaks, pagination, and paragraph layout?
- How to support streaming/interactive prompting (incremental input) with image-based tokenization, where token-by-token arrival is natural for text but not for images?
- Tokenization granularity and projector design
- The projector aggregates 4 neighboring patches; are there better adaptive/learned pooling schemes that align with linguistic boundaries (characters/morphemes/words) across scripts?
- When and how should the projector be tuned vs. frozen? Can regularization or architectural alternatives enable safe finetuning without disrupting alignment?
- How does patch size affect fertility, accuracy, and compositionality across languages and tasks?
- Efficiency accounting and deployment realism
- End-to-end efficiency omits CPU-side rendering overhead, memory footprint, batching behavior, and energy usage; how do these compare across GPUs/CPUs/edge devices?
- How do latency and throughput scale for very long contexts and multi-image inputs, and how does batching multiple visual-text prompts impact performance?
- Baselines and comparisons
- No head-to-head with strong tokenizer-free/text-centric baselines (e.g., byte/char models like ByT5/MEGABYTE, learned compression approaches) or vision-text models trained for pixels (e.g., PIXEL/CLIPPO) under compute-matched settings.
- Comparisons are limited to MLLMs; how does SeeTok fare against a similarly sized text-only LLM with state-of-the-art tokenizers on the same tasks/compute?
- Output-side considerations
- The method only visualizes inputs; could outputs also be generated via a visual pathway for further compression/robustness, and what are the trade-offs for decoding speed and usability?
- Robustness scope
- Perturbation tests cover character/word-level noise and Latin glyph substitutions but not font shifts, color inversions, background clutter, blur, JPEG artifacts, low DPI, or more realistic visual attacks common in OCR.
- Sensitivity to Unicode edge cases (emoji, combining marks, rare code points) and fallback behavior when glyphs are missing is not studied.
- Multilingual coverage and fairness
- Evaluation covers 13 languages; broader coverage (Arabic/Hebrew, Hindi/Marathi, Thai, Japanese/Korean, African scripts, Mongolian vertical) and code-mixed text remains an open question.
- Fertility comparisons rely on word segmentation heuristics (e.g., Jieba for Chinese); how robust are conclusions under alternative segmenters and languages without canonical word boundaries?
- Alignment analysis
- Procrustes alignment shows reduced residuals, but does linear alignment correlate with functional equivalence across tasks and languages? Are nonlinear mismatches present deeper in the network?
- Layer-wise alignment is reported on 1k OOD samples; robustness to sample choice and statistical significance is not provided.
- Compute-matched training controls
- Visual-text finetuning benefits from lower token counts, allowing more examples; compute-matched comparisons (same GPU-hours/updates) with pure-text finetuning are not provided to cleanly attribute gains.
- Task breadth
- No evaluation on code, math (equations/LaTeX), formal proofs, NER/sequence labeling, document QA, or table-heavy tasks where layout and monospacing are critical.
- Impact on chain-of-thought, calibration, and hallucination rates is not examined.
- Safety and content moderation
- Image-based prompts could evade text filters; the paper does not assess moderation, watermarking, jailbreak risks, or susceptibility to adversarial image perturbations targeted at OCR.
- Usability and tooling
- Authoring and debugging visual-text prompts, accessibility concerns (screen readers), and integration with standard NLP pipelines (span selection, token-level masking, retrieval) are open engineering questions.
- Mapping between visual spans and textual substrings for downstream operations (e.g., copy, highlight, span-level supervision) is unspecified.
- Reproducibility details
- Some rendering/resolution details are ambiguous (e.g., the mapping from H×W to 224×224); seeds, variance, and significance tests are omitted.
- Bandwidth and privacy
- Transmitting rendered images can increase payload size relative to text; bandwidth, caching, and privacy implications (image logs vs. text logs) are not discussed.
- Resource footprint
- Despite FLOP reductions, the absolute parameter and memory overhead of the vision encoder vs. a text-only stack is not benchmarked across model sizes.
- Error analysis
- Little qualitative analysis of when SeeTok fails (e.g., rare symbols, dense math, narrow kerning) or when text tokenization remains superior, which could guide targeted improvements.
Practical Applications
Immediate Applications
Based on the paper’s findings, the following applications can be realized with current models and infrastructure by adopting SeeTok’s vision-centric tokenization and lightweight LoRA instruction tuning.
- Cost-efficient multilingual chatbots and customer support
- Sector: software, telecom, customer service
- What: Deploy SeeTok as a drop-in preprocessing layer for existing MLLMs (e.g., Qwen2.5-VL, JanusPro) to handle user inputs rendered as visual-text, cutting average token count by ~4.43× and reducing FLOPs by ~70.5% while maintaining or improving task accuracy.
- Tools/workflows: A “Visual-Text Adapter” microservice that renders incoming text to images, routes through the model’s vision encoder + projector, and returns generation from the LLM; LoRA-tuned weights for visual-text instruction following; observability dashboards tracking compression ratio and latency.
- Assumptions/dependencies: Access to pretrained MLLMs with strong OCR; minimal LoRA fine-tuning on visual-text instructions; acceptance of potential gaps on knowledge-heavy tasks unless further pretraining.
- Robust OCR-driven document automation (forms, invoices, claims, KYC)
- Sector: finance, insurance, healthcare, enterprise IT
- What: Replace brittle text tokenizers in document AI with SeeTok to improve robustness to typos, distorted fonts, scans, and mixed scripts; preserve character-level fidelity for names, codes, and entities.
- Tools/workflows: Pipeline that renders extracted text or page regions to images, encodes via vision encoder + projector, and runs downstream extraction/classification; integration with existing OCR and RPA tools.
- Assumptions/dependencies: Reliable text rendering from PDFs/scans; LoRA-tuned models for instruction-style prompts; adequate font coverage (e.g., Noto Sans) for target scripts.
- Low-resource language access in public services and NGOs
- Sector: policy, government, international development
- What: Improve translation quality and fairness for underserved languages using visual-text fine-tuning (e.g., ALMA/X-ALMA) and SeeTok’s lower token fertility, enabling more samples per compute budget and better COMET scores.
- Tools/workflows: Translation management system plug-ins that switch tokenization to visual-text for source-side inputs; QA loops using COMET-22 and FLORES; triage workflows for languages with highest over-segmentation risk.
- Assumptions/dependencies: Availability of bilingual corpora; basic segmentation (e.g., Jieba for Chinese) for evaluation; policy alignment for data use and model auditing.
- On-device typing aids, autocorrect, and translation
- Sector: consumer mobile, keyboards, messaging
- What: Use SeeTok to enable robust typo-tolerant reading and efficient inference on mobile NPUs/CPUs, supporting on-device autocorrect, translation, and summarization with lower latency and energy.
- Tools/workflows: Embedded rendering + vision encoding for user keystream; small-footprint LoRA-tuned models; caching strategies for repeated phrases.
- Assumptions/dependencies: Hardware acceleration for vision encoders; careful memory budgeting; privacy constraints for local processing.
- Anti-obfuscation moderation and fraud detection
- Sector: trust & safety, ad tech, email security
- What: Detect spam, scams, and policy violations when bad actors replace characters with lookalikes or intentionally scramble text; SeeTok’s robustness to visual attacks reduces false negatives.
- Tools/workflows: Moderation filters that render text snippets and overlays to images; comparison to standard text-tokenizers; adversarial testing suites (character-, visual-, word-level noise).
- Assumptions/dependencies: Access to labeled adversarial datasets; tuning to minimize false positives; governance for automated moderation decisions.
- Screenshot/UI understanding for QA and analytics
- Sector: software engineering, UX research
- What: Read app or web UI screenshots reliably across fonts, themes, and localization; enables bug triage, UI diffing, and content extraction without brittle OCR-tokenizer handoffs.
- Tools/workflows: CI pipelines that render UI text and pass through SeeTok for semantic checks; integration with screenshot capture tools and issue trackers.
- Assumptions/dependencies: Standardized rendering for test assets; LoRA-tuned instruction-following; baseline OCR available for fallback.
- Accessibility: robust reading of stylized or noisy text
- Sector: accessibility tech, education
- What: Improve screen-readers and educational apps for users encountering nonstandard or noisy text (e.g., stylized fonts, minor spelling errors), leveraging SeeTok’s shape- and layout-aware processing.
- Tools/workflows: Assistive apps that render input strings and run comprehension/summarization; configurable font packs; evaluation with real user cohorts.
- Assumptions/dependencies: Further validation with accessibility stakeholders; scope limited to typographic robustness (not clinical claims).
- Compliance and e-discovery on image-embedded text
- Sector: legal, enterprise compliance, digital archiving
- What: Index and analyze social posts, ads, or scans that contain text overlays; SeeTok improves robustness to image-text variability and reduces compute cost for large corpora.
- Tools/workflows: Batch rendering of text regions; scalable inference with compression-aware scheduling; search and classification services.
- Assumptions/dependencies: High-quality region detection/segmentation; font/script coverage; data governance and audit trails.
Long-Term Applications
These applications require further research, scaling, or development—such as larger visual-text pretraining, broader font/script coverage, or architectural changes.
- Unifying text and image processing in general LLMs
- Sector: foundational AI, software platforms
- What: Replace subword tokenization with vision-centric interfaces as the default, aligning text and image streams and reducing multilingual bias and token overhead across the board.
- Tools/products: “Visual Tokenizer SDK” integrated into major LLM stacks; standardized adapters, renderers, and projectors; training toolchains that natively support visual-text.
- Dependencies: Large-scale visual-text pretraining; ecosystem shift in tokenizer standards; benchmarking across knowledge-heavy tasks.
- Extreme-long-context via visual packing
- Sector: productivity, legal, research
- What: Pack long documents (reports, codebases, contracts) as visual-text to expand effective context windows without exploding token counts.
- Tools/products: Visual packing libraries; layout-aware rendering; retrieval-augmented readers that chunk images and aggregate projector outputs.
- Dependencies: Stability at very long sequences; layout fidelity for complex documents; deeper instruction tuning for cross-modal coherence.
- Endangered and minority language documentation
- Sector: cultural heritage, NGOs, academia
- What: Use SeeTok to bootstrap NLP for languages with sparse data, leveraging lower fertility and cross-lingual transfer to make better use of limited corpora and community-collected texts.
- Tools/workflows: Community data capture pipelines; visual-text fine-tuning hubs; multilingual evaluation suites adapted to unique orthographies.
- Dependencies: Ethical data collection; font/rendering support for diverse scripts; sustained funding and policy backing.
- Robustness certification and AI compliance
- Sector: regulatory technology, assurance services
- What: Establish standards and tests for orthographic and visual robustness (character-, visual-, word-level), offering certifications aligned with AI governance frameworks.
- Tools/products: Robustness benchmarking services; reporting APIs; compliance dashboards for model audits.
- Dependencies: Accepted benchmarks and thresholds; standardized reporting formats; alignment with laws (e.g., EU AI Act).
- AR translation and signage reading in the wild
- Sector: robotics, AR/VR, travel tech
- What: Real-time multilingual reading and translation of signage and displays in variable fonts and lighting, leveraging shape-aware visual reading.
- Tools/products: On-device AR apps; embedded SeeTok models in smart glasses; edge deployment toolchains with low-latency rendering.
- Dependencies: Hardware acceleration; domain-adapted training for noisy scenes; latency guarantees and energy constraints.
- Personalized handwriting and font reading
- Sector: productivity, education, creative tools
- What: Train user-specific adapters to read personal handwriting or custom typefaces reliably, enabling seamless note digitization and learning aids.
- Tools/products: Handwriting LoRA kits; privacy-preserving on-device training; UI for collecting calibration samples.
- Dependencies: Sufficient user data; robust generalization across writing conditions; secure storage and processing.
- Multimodal search and retrieval over text-in-images
- Sector: search, knowledge management, media platforms
- What: Build retrieval systems that index both native text and text rendered within images/screenshots, unified under visual-text embeddings.
- Tools/products: Hybrid search engines; embedding services that accept visual-text; analytics over ad creatives and social media posts.
- Dependencies: Scalable visual-text embedding stores; efficient index structures; domain-specific evaluation.
- Creative and brand-safe prompt design
- Sector: marketing, design tools
- What: Treat prompts as visual assets (fonts, layouts), enabling stylized instructions without losing semantics, and enforcing brand-safe typography guidelines for model interactions.
- Tools/products: Prompt rendering toolkits; brand typography validators; A/B testing frameworks for visual prompts.
- Dependencies: Strong cross-modal alignment (as improved via instruction tuning); UX standards for prompt design; content safety policies.
Notes on feasibility across applications:
- Keeping the projector frozen during instruction tuning is critical for stable performance; updating it may degrade cross-modal alignment.
- MLLMs with strong OCR and visual–text alignment (e.g., Qwen2.5-VL family) are preferred backbones; generalization to other models may require additional tuning.
- Knowledge-intensive tasks may still favor traditional text tokenization unless visual-text pretraining is scaled to comparable data volumes.
- Font/script coverage and rendering fidelity affect performance, especially in complex layouts and less-studied orthographies.
- The reported efficiency gains (token compression ~4.43×, FLOPs reduction ~70.5%) depend on model architecture, image resolution, and patch aggregation design; results may vary with different configurations and languages.
Glossary
- ALMA: A small, high-quality bilingual corpus used to finetune models for multilingual instruction following. "we finetune it on ALMA~\citep{xuparadigm}, a small but high-quality bilingual corpus"
- Autoregressive generation loss: The standard next-token prediction objective optimized by summing negative log-likelihood over output tokens. "we optimize the standard autoregressive generation loss:"
- Byte-level BPE: A subword tokenization method operating at the byte level to handle multilingual text and rare tokens. "such as Byte-level BPE~\citep{wang2020neural}"
- COMET-22: A reference-free machine translation evaluation metric that assesses translation quality. "We report the COMET-22 score (COM) for the translation from each of these languages to English~\citep{rei2022comet}"
- Compositionality: The property of representations to generalize by combining parts (e.g., subwords) into whole-word meanings. "resulting in stronger compositionality (cf. Figure~\ref{fig:composition})"
- DeepSpeed ZeRO stage-2: An optimization strategy that partitions optimizer states to reduce memory during distributed training. "we employ DeepSpeed with ZeRO stage-2~\citep{rasley2020deepspeed} and float16 precision"
- ECES: A visual attack protocol that replaces characters with visually similar glyphs to test robustness. "we follow ECES~\citep{eger2019text}, substituting Latin letters with visually similar glyphs"
- Exact Match (EM): A strict evaluation metric for QA tasks measuring whether predicted answers exactly match references. "We report Exact Match (EM) for QA"
- Fertility (FET): The average number of tokens per word, used to assess tokenization efficiency and fairness. "We also calculate Fertility (FET), a metric for assessing tokenizatino performance~\citep{rust2021good}, defined as the average number of tokens per word."
- FLOPs: The number of floating-point operations required, reflecting computational cost. "reducing FLOPs by 70.5\%"
- FLORES: A multilingual benchmark dataset used to evaluate machine translation. "and we use the FLORES test set~\citep{costa2022no} for evaluation."
- Instruction tuning: Finetuning models to better follow and respond to instructions, here using rendered text images. "we introduce vision-centric instruction tuning"
- Jieba: A Chinese word segmentation tool used to compute tokens-per-word metrics. "For word segmentation, we use Jieba for zh and whitespace splitting for other languages~\citep{ali2024tokenizer}."
- LoRA: Low-Rank Adaptation; a parameter-efficient finetuning method that injects trainable low-rank matrices. "we integrate LoRA adapters~\citep{hu2022lora} into both the vision encoder and the LLM."
- Masked patch prediction: A self-supervised objective where masked image patches are predicted from visible context. "applies a VIT-MAE~\citep{he2022masked} with masked patch prediction on rendered text images"
- MMLU: A benchmark for multi-domain knowledge and reasoning used to evaluate LLMs. "MMLU~\citep{hendrycksmeasuring}"
- Multilingual fairness: Ensuring tokenization and modeling treat high- and low-resource languages equitably. "This method promotes multilingual fairness, achieving low token fertility even for low-resource languages."
- NQ: Natural Questions; a QA dataset used for evaluating open-domain question answering. "(TriviaQA~\citep{joshi2017triviaqa}, NQ~\citep{kwiatkowski2019natural}, and PopQA~\citep{mallen2023not})"
- OCR: Optical Character Recognition; the capability to read text from images. "exhibit strong OCR ability and robust textâvision alignment"
- Orthographic perturbations: Spelling- or form-level noise (character, visual, word-level) applied to test robustness. "under different orthographic perturbations (character-, visual-, and word-level noise)."
- Orthogonal Procrustes analysis: A method to align two vector spaces via an orthogonal transformation minimizing Frobenius distance. "we apply Orthogonal Procrustes analysis~\citep{schonemann1966generalized}"
- PopQA: A popular-knowledge QA dataset for evaluating factual question answering. "(TriviaQA~\citep{joshi2017triviaqa}, NQ~\citep{kwiatkowski2019natural}, and PopQA~\citep{mallen2023not})"
- Residual norm: The Frobenius norm of alignment error after Procrustes mapping, indicating cross-modal similarity. "We quantify alignment using the residual norm, i.e., the Frobenius distance between the transformed visual-text embeddings and the corresponding pure-text embeddings."
- SeeTok: A vision-centric tokenization approach that renders text as images and encodes them via vision encoders. "we introduce SeeTok, a simple yet powerful vision-centric tokenization method for LLMs."
- SST5: A five-class sentiment classification benchmark. "and sentiment classification (SST5~\citep{socher2013recursive})"
- Subword tokenization: Segmenting text into smaller units (subwords) to balance vocabulary size and coverage. "subword tokenization techniques, such as Byte-level BPE~\citep{wang2020neural}"
- Typoglycemia: The phenomenon where humans can read jumbled words by relying on overall shape and familiar patterns. "commonly referred to as typoglycemia~\citep{johnson2007transposed}, highlights the profound robustness of human reading."
- VIT-MAE: Vision Transformer Masked Autoencoder; a self-supervised vision model trained via masked patch reconstruction. "applies a VIT-MAE~\citep{he2022masked} with masked patch prediction on rendered text images"
- Visual Word Form Area (VWFA): A brain region specialized for recognizing familiar word forms from visual inputs. "Visual Word Form Area (VWFA), a brain region that identifies familiar words from visual word shapes~\citep{dehaene2011unique,mccandliss2003visual,wimmer2016visual}."
- Visual-text: Text rendered as images to be processed by vision encoders in multimodal models. "instructions are rendered as images (i.e., visual-text instructions)"
- WordPiece: A subword tokenization algorithm that builds words from learned subword units. "WordPiece~\citep{devlin2019bert}"
- WMT22: A machine translation benchmark/test set used for evaluating translation quality. "we test on WMT22 test data~\citep{freitag2022results}"
- X-ALMA: A multilingual parallel data resource used for low-resource language finetuning. "The training parallel data is provided by X-ALMA~\citep{citation-0}"
- Zero-shot setting: Evaluation without task-specific finetuning on the test distribution. "under three perturbation types in a zero-shot setting (i.e., without any dataset-specific fine-tuning)"
Collections
Sign up for free to add this paper to one or more collections.