- The paper introduces a novel evaluation taxonomy combining perplexity and prompt engineering to assess LLMs' quality judgments.
- It compares multiple models and prompt settings using metrics like Pearson correlations, highlighting GPT-4’s superior alignment with human annotations.
- The findings inform automated evaluation and training optimizations to enhance task-specific reliability and unbiased performance in LLMs.
Evaluating the Evaluator: Measuring LLMs' Adherence to Task Evaluation Instructions
Introduction
The paper explores the methodology of LLMs-as-a-judge, substituting human involvement in task evaluations with LLM-based automated assessments. LLMs such as GPT-4 and Llama3, trained through RLHF, are expected to emulate human judgement when evaluating quality tasks like text coherence. This research scrutinizes whether LLMs adhere to task-specific prompts or mirror their biases rooted in their high-quality fine-tuned data. It introduces a novel taxonomy of qualitative evaluation criteria and positions perplexity as a benchmark alongside explicit prompts for quality judgement.
Evaluating LLMs-as-a-judge
To critically assess LLMs-as-a-judge, multiple prompt settings are evaluated:
- Perplexity-Based Evaluation: Relies on LLM perplexity without explicit prompting, measuring the alignment of task solutions with the model's training data.
- Generic Prompt: Basic quality assessment with minimal instruction.
- Specific Criteria Prompt: Judgment based on named criteria, counting on the model's intrinsic knowledge of these criteria.
- Full Rubric Prompt: Includes comprehensive criteria with detailed guidance on scoring.
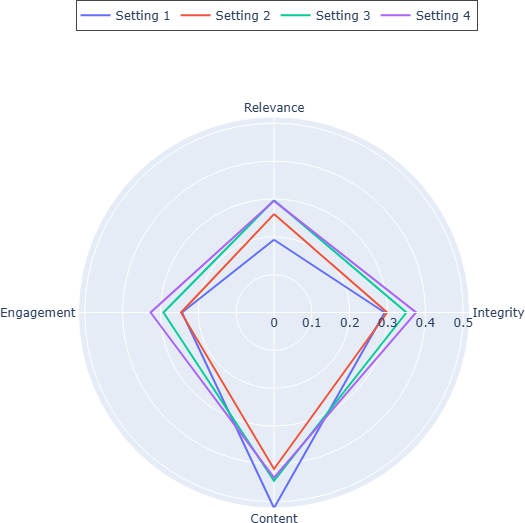
Figure 1: Radar chart of average Pearson correlations for the quality criteria groups for each of different settings of prompting (1 - Perplexity / No Prompting, 2 - Generic prompt, 3 - Specific prompt, 4 - Full rubric) over all models.
Model Selection
The research encompasses a range of LLMs, including prominent models like GPT-4, Llama3, Mistral, and Phi3. These models were evaluated across various quality metrics and prompt setups using benchmark datasets, including SummEval and TopicalChat, emphasizing diverse aspects like fluency, coherence, and task relevance.
Results and Analysis
Results indicate that larger models like GPT-4 exhibit superior alignment with human annotations across all prompt settings, demonstrating a minimal performance variance when detailed rubrics are provided. In contrast, smaller models benefit more significantly from comprehensive instructions.
Dataset Level Insights
Perplexity notably correlates highly with text quality assessments, outperforming minimal prompting in simpler quality judgment scenarios. However, complex tasks necessitate explicit instruction enrichment, as evidenced in datasets like OpinSummEval where nuanced criteria such as sentiment and aspect extraction demand a structured prompt setup.
Criteria Level Analysis
The taxonomy-driven analysis reveals:
- Content-Based Criteria: Structural text quality (e.g., fluency) aligns robustly with perplexity, while nuanced attributes like naturalness benefit from detailed instructions.
- Engagement-Based Criteria: Intrinsically subjective, these criteria (e.g., empathy) are less influenced by instruction detail, reflecting high variability and lower correlation with human judgments.
- Relevance and Integrity Criteria: Instruction enrichment significantly enhances assessments, particularly when model capability aligns with task-specific accuracy needs.
Conclusion
The empirical analysis underscores nuanced prompt engineering's limited impact on LLM performance in judgment tasks, with perplexity providing a compelling benchmark for certain textual evaluations. These findings inform the practical deployment of LLMs in automatic evaluation contexts, guiding future optimizations in training and task-specific model assessment to improve fidelity in human-LLM alignment.