- The paper demonstrates that integrating tool usage into DRL improves interpretability and enhances decision-making in stock trading.
- It presents a multi-stage framework that mimics human reasoning, optimizing both information acquisition and action execution.
- Backtesting shows an ARR improvement of 18.45% for the AlphaQuanter-7B model, outperforming prompt-based baseline methods.
Introduction
The paper "AlphaQuanter: An End-to-End Tool-Orchestrated Agentic Reinforcement Learning Framework for Stock Trading" presents a novel approach to addressing the challenges faced by existing LLM agents in automated trading. Traditional machine learning methods, while useful, simplify market dynamics and lack the capability to integrate multi-source trading signals effectively. Deep Reinforcement Learning (DRL) approaches, although powerful, suffer from a black-box nature that undermines decision transparency. AlphaQuanter aims to bridge these gaps by introducing a tool-augmented RL framework that empowers a single agent with enhanced decision-making capabilities, ensuring both interpretability and strategic coherence.
Framework Architecture
AlphaQuanter's architecture (Figure 1) is designed to mimic the human cognitive process of reasoning and action, divided into discrete stages of planning, information acquisition, reasoning, and action-taking. The framework employs a ReAct approach, where the agent begins with an initial plan and iteratively refines its strategy through a combination of tool usage and analytical reasoning. Importantly, AlphaQuanter actively orchestrates external tools to fill information gaps, thereby maintaining a transparent and auditable decision process.
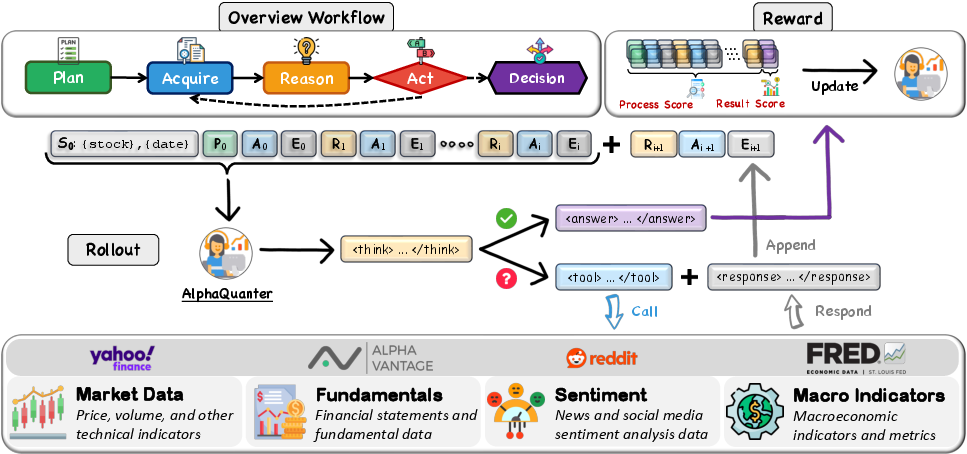
Figure 1: The overall architecture and workflow of AlphaQuanter. The central panel shows the agent's iterative rollout process. Starting from an initial state (S0), the agent first forms an initial plan (P0) before generating further reasoning traces (Ri+1) with > tag. In each step, it decides whether to continue acquiring information by executing a tool-based action (Ai+1) and receiving its environmental feedback (Ei+1), or to conclude by outputting a final decision with an <answer> tag. Throughout this process, the agent can query multi-dimensional financial data sources (bottom panel, Section~\ref{sec:info_sources}). Once a decision is made, the entire trajectory will be evaluated to compute a reward (top-right panel, Section~\ref{sec:score}), which updates the agent's policy. The overall workflow (top-left panel, Section~\ref{sec:cognitive_workflow}) is designed to mimic a human trader's cognitive process of reasoning and acquiring data on demand.
Reinforcement Learning Optimization
AlphaQuanter leverages reinforcement learning not only to optimize decisions around long-term portfolio returns but also to refine the agent's reasoning and information-gathering process. The reward function is carefully curated to encourage strategic action and accurate market state classification. This includes both outcome-based rewards, which focus on profitable decision-making, and process-oriented rewards, which penalize inefficient or malformed tool usage.
Comprehensive backtesting demonstrates AlphaQuanter's superiority in terms of both interpretability and financial performance over existing multi-agent and prompt-based methods. Notably, AlphaQuanter-7B shows consistently strong performance across key financial metrics: achieving an average ARR improvement of 18.45% over the strongest baseline. These results indicate that the model effectively learns to sequence information acquisition and develop sophisticated trading strategies that are robust to market noise.
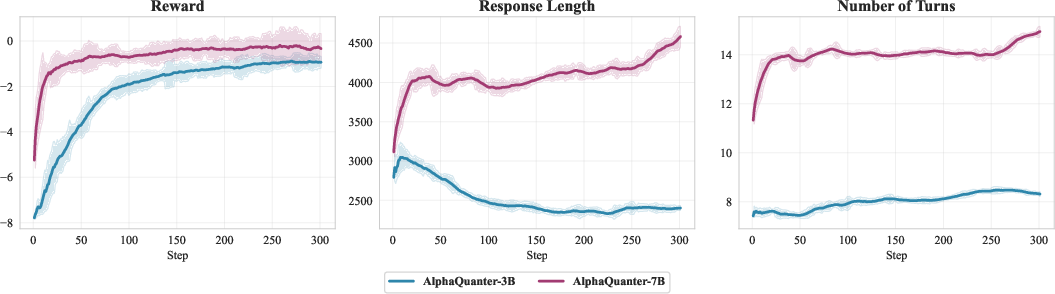
Figure 2: Comparison of training dynamics for the AlphaQuanter-3B and -7B models.
Training Dynamics and Insights
The training dynamics (Figure 2) reveal significant differences in learning behaviors between the 3B and 7B model variants. The 7B model exhibits a more thorough exploration phase and achieves a stable exploitation regime earlier, leading to refined strategies and enhanced performance. Analysis of tool usage patterns suggests that AlphaQuanter agents dynamically refine their information-seeking behaviors, confirming their ability to autonomously learn effective trading strategies.
Conclusion
AlphaQuanter represents a significant advancement in the design of automated trading systems by integrating reinforcement learning with a tool-augmented workflow. This empowers LLMs to act strategically and reason effectively in uncertain market environments. Future work will focus on extending AlphaQuanter's capabilities to dynamically adapt to real-time market information and explore its potential in high-frequency trading scenarios.

