- The paper introduces Agent Market Arena, a dynamic benchmark that evaluates LLM-based trading agents in live multi-market settings.
- It integrates real-time verified market data, standardized agent inputs, and rigorous metrics like Sharpe ratio and cumulative return for performance analysis.
- Findings reveal that agent architecture drives profitability more than LLM backbone choice, emphasizing the need for runtime adaptability.
Agent Market Arena: A Lifelong, Real-Time Benchmark for LLM-Based Trading Agents
Introduction and Motivation
The paper "When Agents Trade: Live Multi-Market Trading Benchmark for LLM Agents" (2510.11695) introduces Agent Market Arena (AMA), a comprehensive, continuously updating benchmark for evaluating the real-time trading capabilities of LLM-based agents across multiple financial markets. AMA addresses critical limitations in prior work: static evaluation periods, unverified and inconsistent data sources, and a focus on model-centric rather than agent-centric assessment. By integrating verified market data, expert-reviewed news, and diverse agent architectures, AMA enables rigorous, reproducible, and dynamic evaluation of financial reasoning and trading intelligence in LLM-driven agents.
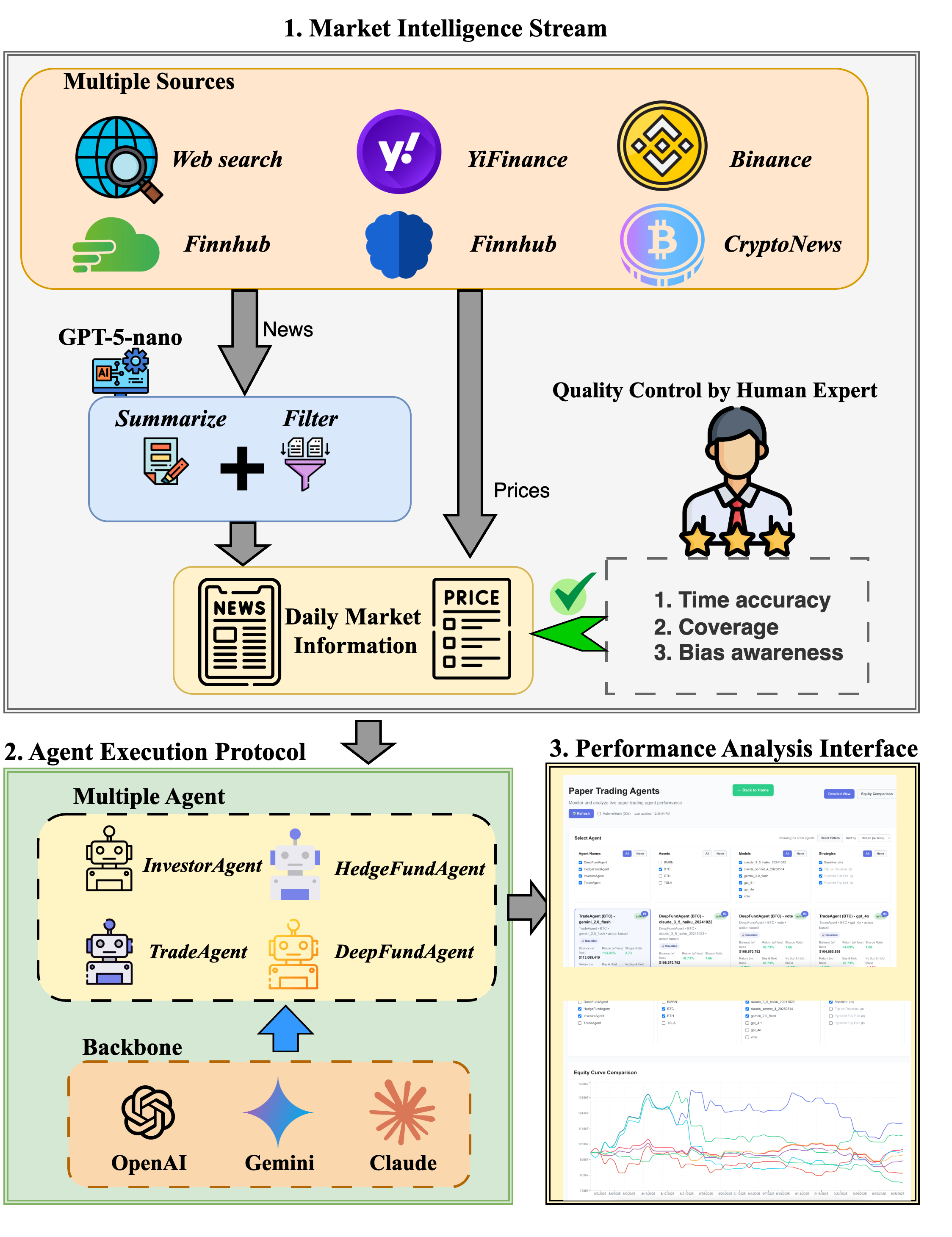
Figure 1: Overall framework of Agent Market Arena, illustrating the integration of market intelligence, agent execution, and performance analytics.
AMA Framework and Data Pipeline
AMA is structured around three core components:
- Market Intelligence Stream (MIS): Aggregates real-time data from heterogeneous sources (APIs, news aggregators, social media) and produces daily, expert-verified summaries. Redundancy and bias are mitigated via LLM-based summarization and multi-annotator quality control, ensuring high-fidelity, unbiased market context for agent decision-making.
- Agent Execution Protocol (AEP): Standardizes agent interaction with the market, enforcing identical inputs, outputs, and configuration across agents. Each agent receives unified prompts containing asset identifiers, historical prices, and contextual news, and outputs discrete daily actions (BUY, SELL, HOLD) executed synchronously.
- Performance Analytics Interface (PAI): Provides a real-time dashboard for monitoring, comparing, and analyzing agent performance across assets, models, and strategies. Metrics include cumulative return (CR), annualized return (AR), annualized volatility (AV), Sharpe ratio (SR), and maximum drawdown (MDD).
Agent Architectures and LLM Backbones
AMA implements four agent frameworks:
- InvestorAgent: Single-agent baseline with memory module for historical reasoning.
- TradeAgent: Multi-agent system with specialized analyst roles and hierarchical decision aggregation.
- HedgeFundAgent: Hierarchical team of character-driven sub-agents coordinated by portfolio and risk managers.
- DeepFundAgent: Memory-adaptive agent leveraging streaming inputs and historical portfolio updates.
Each agent is evaluated with five LLM backbones: GPT-4o, GPT-4.1, Claude-3.5-haiku, Claude-sonnet-4, and Gemini-2.0-flash. This design enables disentanglement of agent architecture and model backbone effects under identical trading conditions.
Experimental Setup
Agents are deployed in live trading on two equities (TSLA, BMRN) and two cryptocurrencies (BTC, ETH), spanning both structured and highly volatile market regimes. Initialization uses historical data (2025-05-01 to 2025-07-31), followed by real-time trading from 2025-08-01 onward. All trading activities are logged, and performance metrics are updated daily.
Results: Agent vs. Model Effects
Live trading results demonstrate that LLM-based agents can consistently make profitable decisions, often outperforming buy-and-hold baselines. DeepFundAgent achieves balanced returns (e.g., 8.61% CR on TSLA, 9.45% on BMRN), while InvestorAgent (GPT-4.1) attains a Sharpe ratio of 6.47 on TSLA. TradeAgent and HedgeFundAgent exhibit more aggressive risk profiles, with higher volatility and drawdowns.
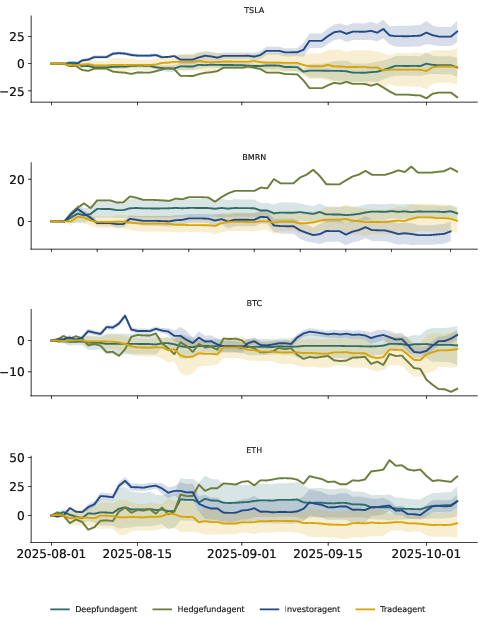
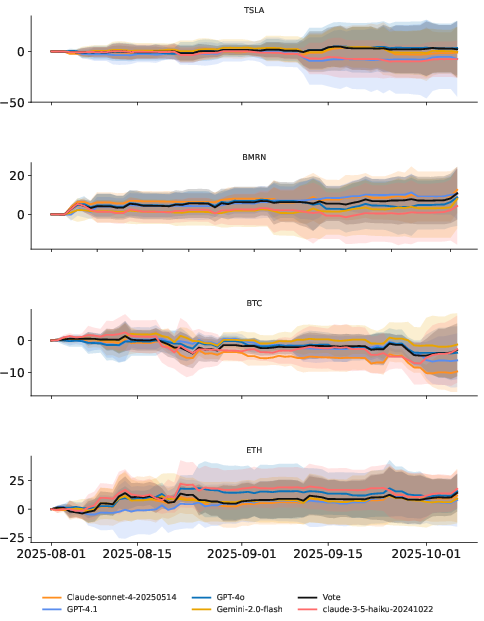
Figure 2: Aggregated performance of different agents across four assets, highlighting the dominant effect of agent architecture on outcome variance.
Agent Architecture Dominates Over LLM Backbone
Switching agent frameworks produces significantly greater performance divergence than changing LLM backbones. For example, InvestorAgent's results on TSLA are tightly clustered across LLMs, while GPT-4.1's performance varies widely across agent designs. This indicates that decision logic, coordination strategy, and risk control mechanisms are more influential than backbone reasoning capability.
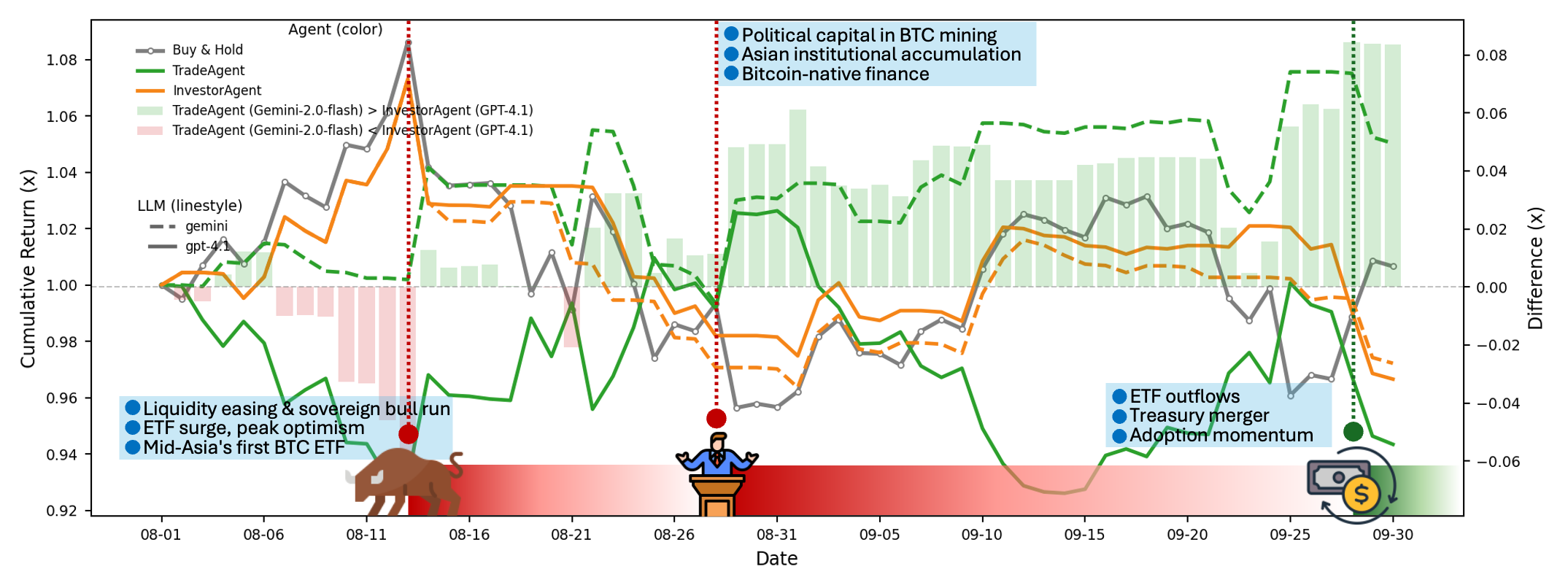
Figure 3: Agent performance on BTC under different market events, showing profit gap between TradeAgent (Gemini-2.0-flash) and InvestorAgent (GPT-4.1).
Decision-Making Under Volatility
Analysis of BTC trading episodes reveals that agents capable of exploiting volatility (e.g., TradeAgent) outperform those following long-term trends. TradeAgent correctly hedges risk during bullish rallies and anticipates short-term corrections, while InvestorAgent captures early rallies but misses later turning points. All agents struggle with abrupt macro reversals, underscoring the challenge of real-time adaptation.
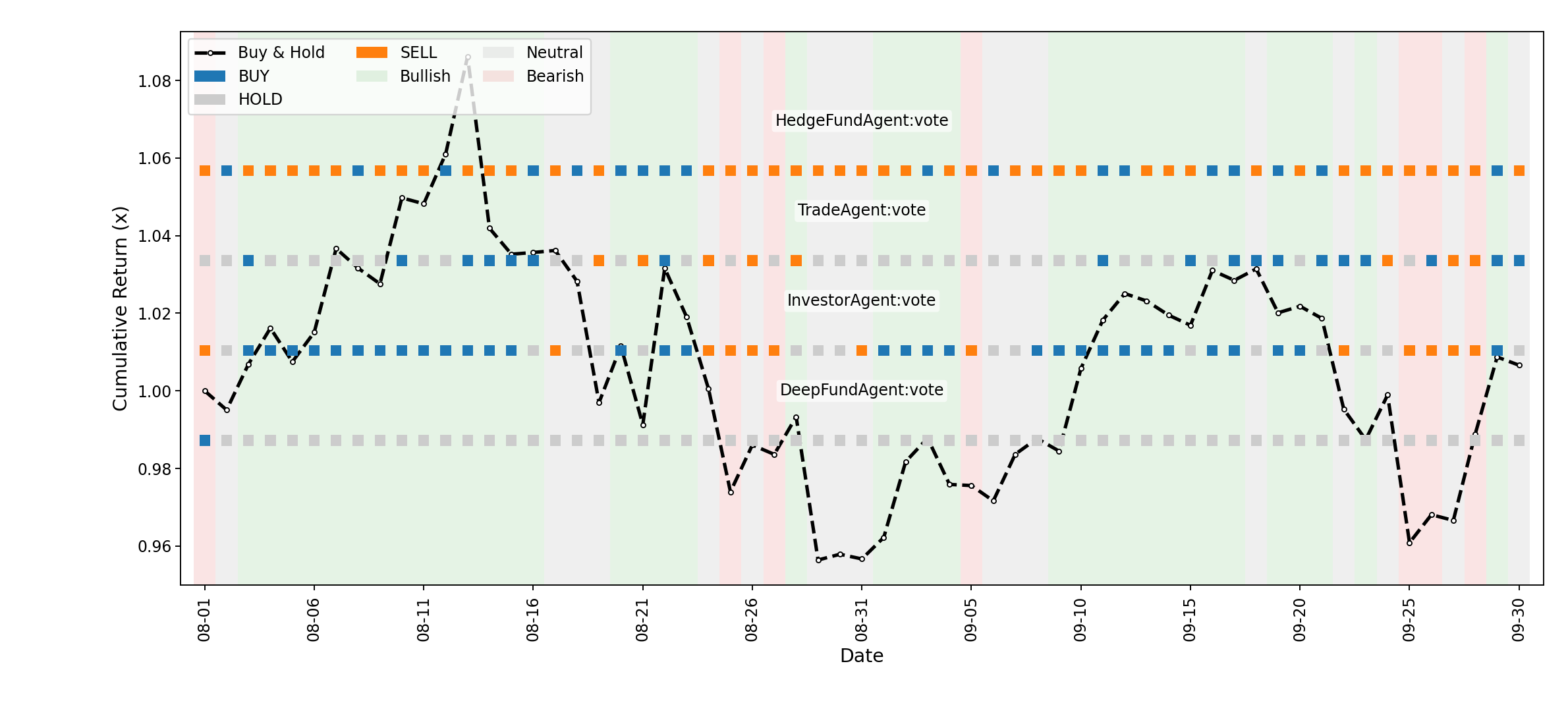
Figure 4: Cumulative return comparison of Buy-and-Hold baseline for BTC, annotated with daily news sentiment and agent voting signals.
Trading Styles and Risk Profiles
Agents exhibit distinct trading philosophies: HedgeFundAgent and InvestorAgent favor short positions, DeepFundAgent prefers buying, and TradeAgent tends to hold. Aggressive agents (HedgeFundAgent) achieve substantial profits in ETH and BMRN but incur losses in TSLA and BTC, while conservative agents (DeepFundAgent) maintain stable, moderate gains. These patterns reflect the impact of memory-adaptive mechanisms and risk preferences on decision consistency and profitability.
AMA's dashboard and equity comparison views enable granular analysis of agent performance dynamics, volatility tolerance, and decision robustness.
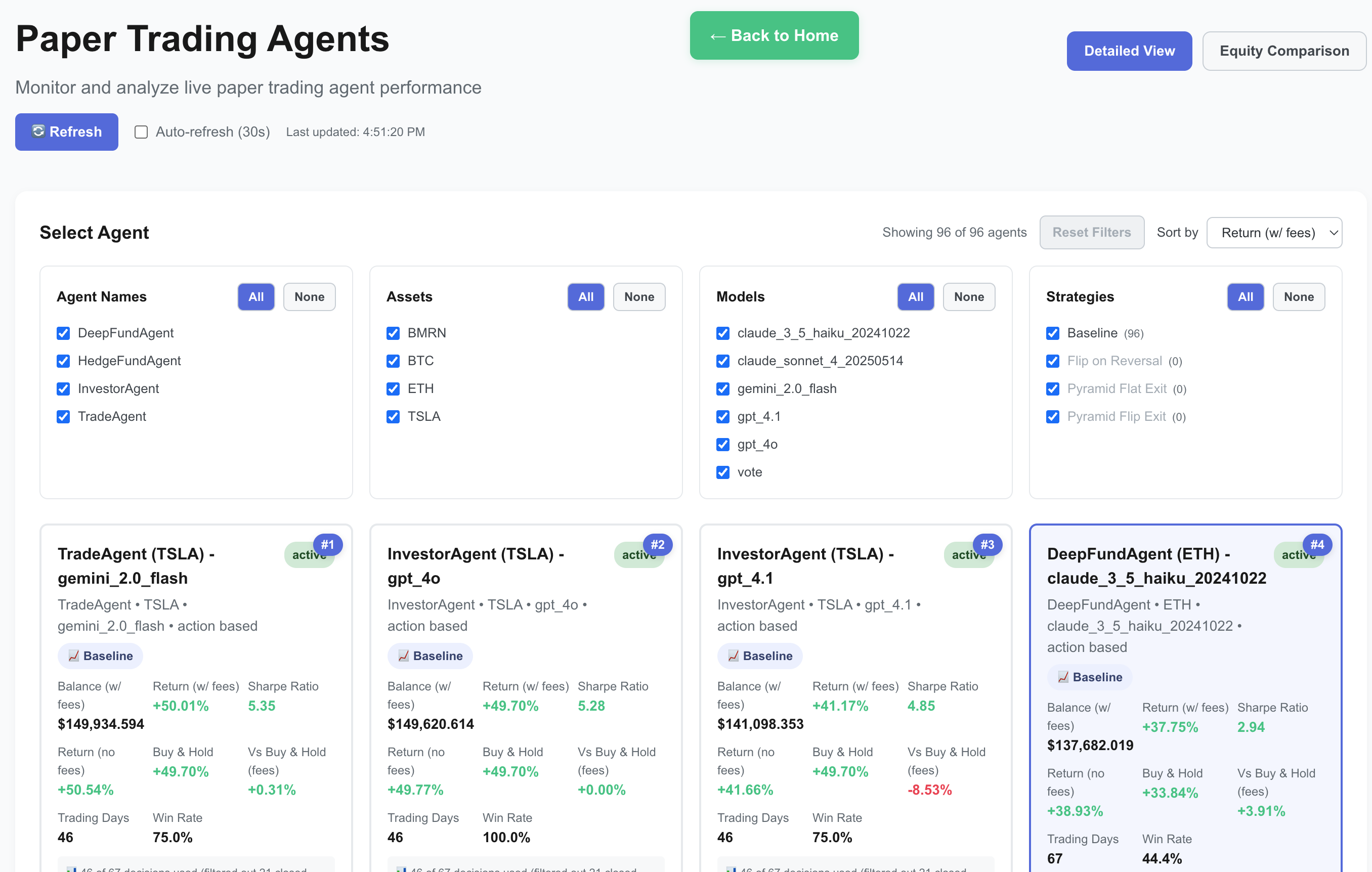
Figure 5: Agent Market Arena Dashboard (Overview View) for real-time monitoring and comparison of agent performance.
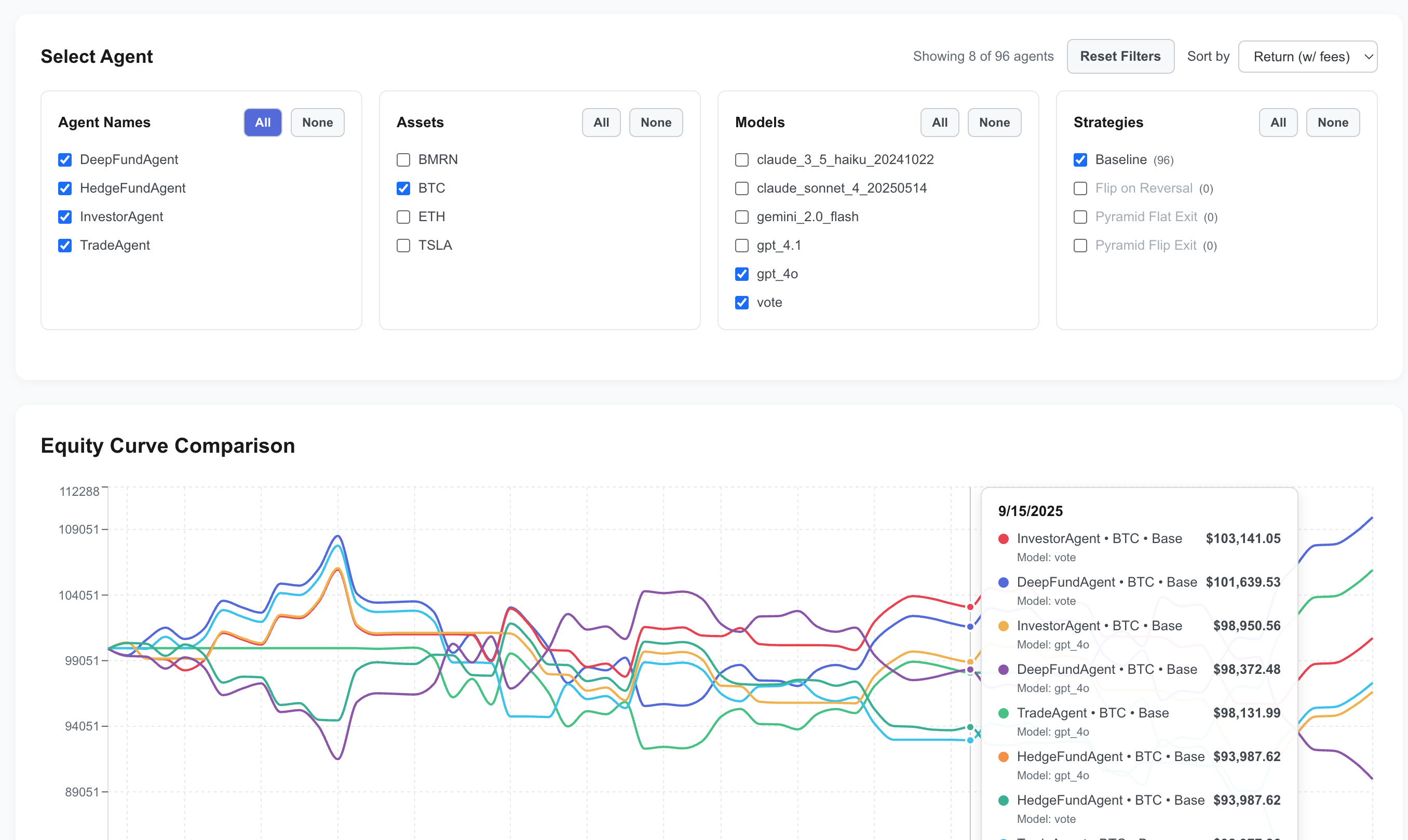
Figure 6: Equity Comparison View for multi-dimensional evaluation of agent, asset, and model combinations.
Implications and Future Directions
AMA establishes a reproducible, dynamic foundation for studying autonomous financial intelligence in LLM-driven systems. Key findings include:
- LLM-based agents can trade effectively and outperform simple baselines in live environments.
- Agent architecture is the primary determinant of profitability and adaptability, surpassing the influence of LLM backbone choice.
- Adaptive frameworks excel in volatile markets, while trading style shapes risk-return profiles.
- Multi-market, real-time evaluation is essential for generalizable assessment of agent reasoning and decision-making.
Future work should extend AMA with inter-agent communication, cross-asset dynamics, and reinforcement learning feedback, advancing toward more sophisticated autonomous trading systems.
Conclusion
Agent Market Arena represents a significant advance in benchmarking LLM-based trading agents under genuine market conditions. By integrating verified data streams, standardized protocols, and transparent analytics, AMA enables rigorous, continuous evaluation of agent reasoning, adaptability, and trading intelligence. The results highlight the primacy of agent design over model backbone and underscore the necessity of dynamic, multi-market benchmarks for progress in financial AI.

