- The paper demonstrates that LLM truthfulness representations collapse under out-of-distribution transformations, with AUC scores sharply declining even when semantics remain intact.
- It employs non-linear, linear, and next-token probability probes across diverse datasets, revealing that high benchmark accuracy does not guarantee robust internal knowledge.
- Findings show that larger models are not inherently more resilient, highlighting the need for training innovations to achieve invariant, robust representations.
Brittle Knowledge in LLMs: Truthfulness Representations Depend on Superficial Resemblance
Introduction
This paper presents a systematic investigation into the robustness of truthfulness representations in LLMs, focusing on whether internal knowledge representations generalize beyond the superficial forms encountered during pre-training. The authors build on prior work demonstrating that LLM hidden states encode separable representations of true versus false statements, and extend this line of inquiry by probing the stability of these representations under semantically-preserving but distribution-shifting transformations. The central claim is that LLM knowledge is brittle: separability of truthfulness representations degrades rapidly as input samples become more out-of-distribution (OOD) with respect to pre-training data, even when semantic content is preserved.
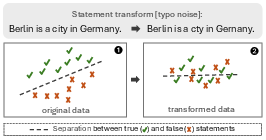
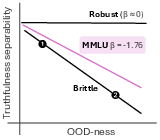
Figure 1: Semantically-preserving transformations (e.g., typos, paraphrases, translation) drive samples OOD, causing collapse of true/false statement representations and degrading separability.
Methodology
Probing Techniques
Three probing methods are employed to assess the separability of true and false statements:
- Non-linear probe: A 3-layer feedforward neural network trained on residual stream activations of the final token.
- Linear probe: A single-layer logistic regression on the same activations.
- P(True): An output-based method using next-token probabilities in a multiple-choice format, normalized to yield a probability of truthfulness.
Probe performance is quantified via AUC (Area Under the ROC Curve), with higher AUC indicating better separability.
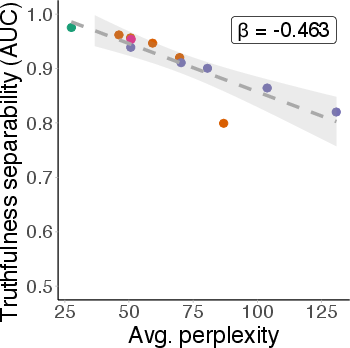
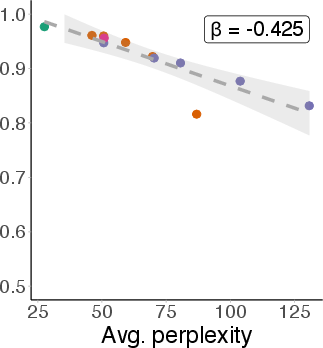
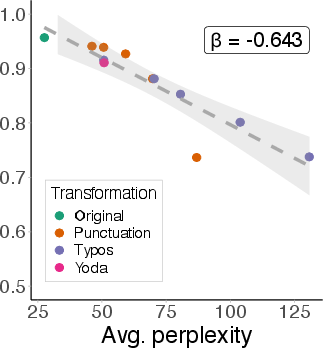
Figure 2: Linear probe architecture for classifying true/false statements from LLM activations.
Models and Datasets
Ten decoder-only autoregressive LLMs spanning four model families (OLMo, Llama 3.1/3.2, Gemma-3) are evaluated. Four benchmark datasets are used: True-False, MMLU, OpenBookQA, and TruthfulQA, covering a range of domains and question formats.
To drive samples OOD, the following transformations are applied:
- Typos and punctuation noise (character-level perturbations)
- Syntactic negation
- Clause reordering ("Yoda speak")
- Translation to French and Spanish
These transformations preserve semantic content but alter surface form, enabling analysis of robustness to superficial changes.
Measuring OOD-ness
Statement perplexity, computed by the LLM, is used as a proxy for OOD-ness. Validation against n-gram statistics from the OLMo pre-training corpus confirms that higher perplexity correlates with lower representation in the training data.
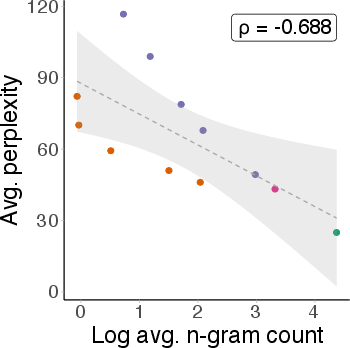
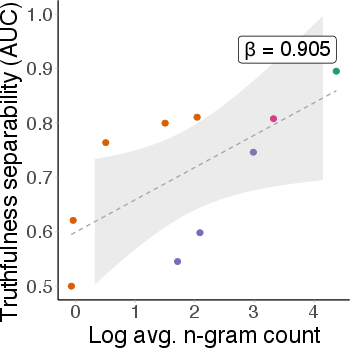
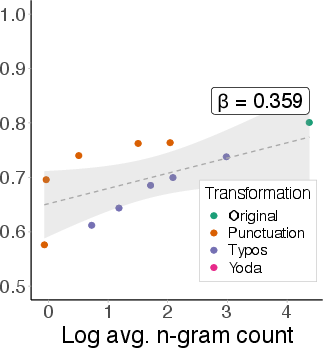
Figure 3: Strong negative correlation between statement perplexity and n-gram count in pre-training data, validating perplexity as an OOD proxy.
Main Findings
Degradation of Truthfulness Representations
Across all probing methods, datasets, and model families, separability of true and false statements degrades as samples become more OOD. On the original True-False dataset, all probes achieve high AUC (≥0.96), but AUC drops sharply with increasing perplexity. The degradation slope (β) is consistently negative, with P(True) showing the steepest decline.
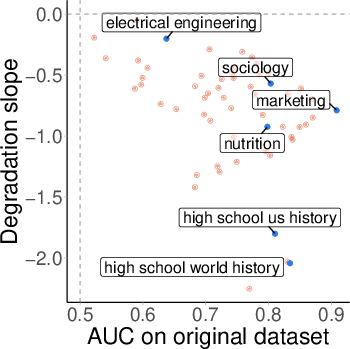
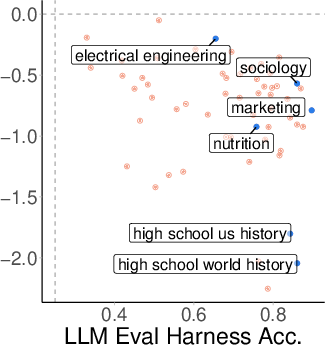
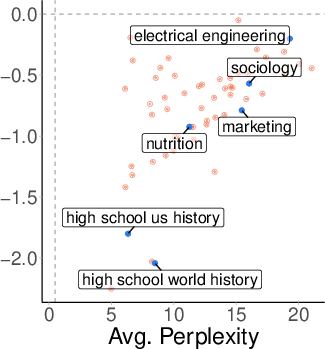
Figure 4: Probe AUC decreases as average perplexity increases, indicating collapse of truthfulness representations under OOD shift.
This pattern generalizes to MMLU, OpenBookQA, and TruthfulQA, with the steepest degradation observed for MMLU (β=−1.76 for the non-linear probe).
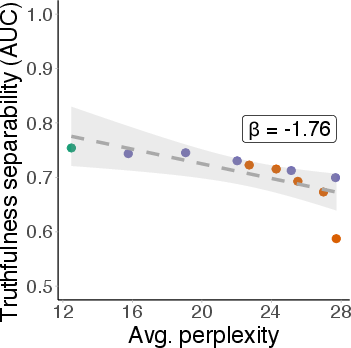
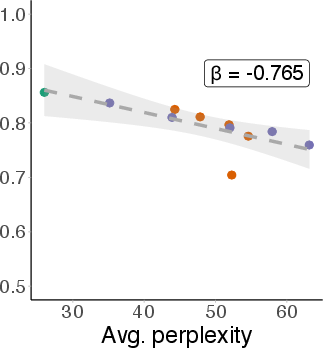
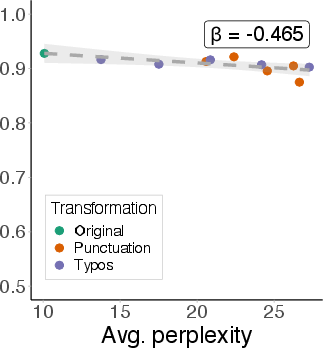
Figure 5: Non-linear probe AUC on MMLU degrades with increasing perplexity, demonstrating brittleness across domains.
Model Scale and Family Effects
All tested model families exhibit similar degradation rates. Notably, larger models (e.g., Llama 3.1 70B) are less robust than smaller counterparts, contradicting the expectation that scale improves generalization of internal knowledge representations.
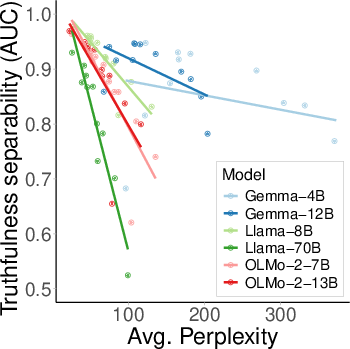
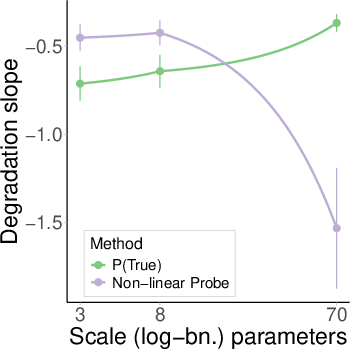
Figure 6: Non-linear probe AUC vs. perplexity for multiple model families; all show degradation, with larger models degrading faster.
Filtering MMLU to questions answered correctly by the model does not yield more robust truthfulness representations. The degradation slope for the correct subset is nearly parallel to that of the full dataset, indicating that high benchmark accuracy does not imply robust internal knowledge.
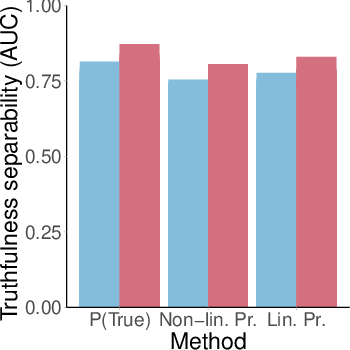
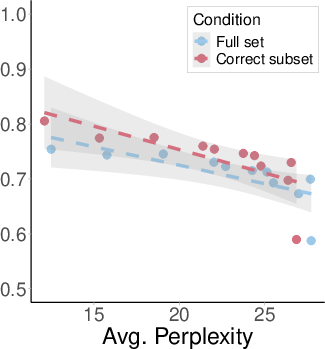
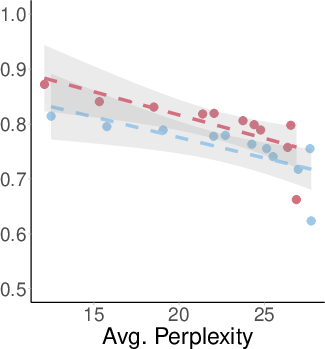
Figure 7: Probe AUC for correct-only MMLU subset degrades at the same rate as the full set, showing that correct answers do not guarantee robust representations.
Topic-Level Variability
Analysis by MMLU topic reveals substantial variability in robustness. Some topics (e.g., sociology, marketing) maintain high separability and robustness under OOD shift, while others (e.g., history) degrade sharply. Importantly, robustness is not explained by pre-training coverage (as measured by perplexity), nor by benchmark accuracy.
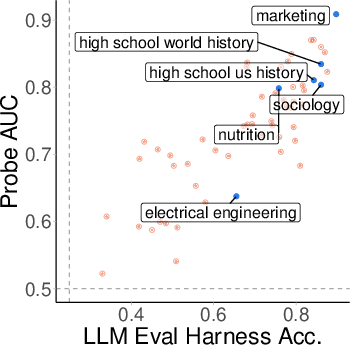
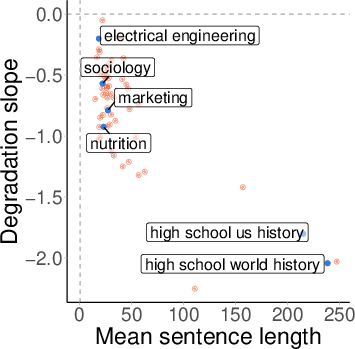
Figure 8: Benchmark accuracy vs. probe AUC by topic; high accuracy does not guarantee robust separability.
Most transformations degrade AUC in proportion to their effect on perplexity. However, translation causes a pronounced drop in AUC without a corresponding increase in perplexity, indicating that knowledge representations can collapse even when samples remain relatively in-distribution.
Implications
Theoretical Implications
The findings challenge the assumption that LLMs acquire robust, generalizable knowledge during pre-training. Instead, internal representations of truthfulness are tightly coupled to superficial resemblance to training data, undermining the reliability of LLMs in OOD scenarios. This brittleness is not mitigated by increased model scale or pre-training coverage, suggesting a fundamental limitation in current LLM architectures and training regimes.
Practical Implications
The brittleness of truthfulness representations has direct consequences for the deployment of LLMs in real-world settings, where input variation is inevitable. Reliance on probing methods to improve factuality or reliability is fundamentally limited by the instability of underlying representations. Benchmark scores are insufficient indicators of robust knowledge, and post-training methods that elicit latent knowledge may not address the core issue.
Future Directions
Improving the robustness of knowledge representations requires architectural or training innovations that promote invariance to superficial input variation. Data-centric approaches focusing on diversity and quality, as well as methods for enforcing semantic invariance in internal representations, are promising avenues. Further research is needed to disentangle the effects of memorization, reasoning, and generalization in LLMs, and to develop evaluation protocols that capture robustness beyond benchmark accuracy.
Conclusion
This work provides compelling evidence that LLM knowledge is brittle: internal truthfulness representations degrade rapidly under semantically-preserving, superficial input transformations. The phenomenon is consistent across models, datasets, and probing methods, and is not alleviated by increased scale or pre-training coverage. These results highlight a critical challenge for the reliability and generalizability of LLMs, motivating future research into robust knowledge encoding and evaluation.