TruthRL: Incentivizing Truthful LLMs via Reinforcement Learning
Abstract: While LLMs have demonstrated strong performance on factoid question answering, they are still prone to hallucination and untruthful responses, particularly when tasks demand information outside their parametric knowledge. Indeed, truthfulness requires more than accuracy -- models must also recognize uncertainty and abstain when unsure to avoid hallucinations. This presents a fundamental challenge for existing methods: approaches that optimize for accuracy often amplify hallucinations, while those that encourage abstention can become overly conservative, sacrificing correct answers. Both extremes ultimately compromise truthfulness. In this work, we present TruthRL, a general reinforcement learning (RL) framework that directly optimizes the truthfulness of LLMs. Specifically, we implement TruthRL using GRPO with a simple yet effective ternary reward that distinguishes correct answers, hallucinations, and abstentions. It incentivizes models to reduce hallucinations not only by providing correct responses, but also by enabling abstention when uncertain, thereby improving truthfulness. Extensive experiments across four knowledge-intensive benchmarks show that, compared to vanilla RL, TruthRL significantly reduces hallucinations by 28.9% and improves truthfulness by 21.1%, with consistent gains across various backbone models (e.g., Qwen, Llama) under both retrieval and non-retrieval setups. In-depth ablation study demonstrates that vanilla accuracy-driven methods, such as supervised fine-tuning or RL with a binary reward, struggle to balance factual correctness and uncertainty. In contrast, our proposed truthfulness-driven TruthRL achieves strong performance in both accuracy and truthfulness, underscoring the importance of learning objective design for developing truthful LLMs.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making LLMs more truthful. Truthful means not just getting answers right, but also saying “I don’t know” when they’re unsure instead of guessing and making things up. The authors created a training method called TruthRL that teaches LLMs to reduce “hallucinations” (confident but wrong answers) and to abstain when they don’t know.
Key Objectives
The paper aims to answer simple, practical questions:
- How can we train LLMs to be truthful, not just accurate?
- Can we encourage models to avoid guessing when they’re unsure?
- What kind of training rewards help models balance giving correct answers and admitting uncertainty?
Methods and Approach
Think of training an LLM like coaching a student for a quiz:
- Old methods focused only on accuracy. This is like telling the student, “Always answer—guess if you must,” which leads to more wrong answers.
- The new method, TruthRL, uses reinforcement learning (RL). RL is like giving feedback after each attempt: reward good behavior, discourage bad behavior, and repeat until the student improves.
Here’s how TruthRL works, using everyday ideas:
- Group practice: The model tries several possible answers to the same question.
- A “ternary reward” system:
- Correct answer: reward (+1)
- “I don’t know” (abstain): neutral (0)
- Wrong answer (hallucination): penalty (−1)
- Why this matters: If the model truly doesn’t know, it’s better to abstain than to invent something wrong. This reward design teaches that behavior.
The training algorithm they use is called GRPO (Group Relative Policy Optimization). Simple explanation:
- The model makes a small group of answers.
- The training compares answers in the group and pushes the model toward the better ones.
- With the ternary reward, telling the truth (“I don’t know”) is treated better than guessing and being wrong.
They also tried extra reward ideas:
- Knowledge-enhanced rewards: give a bonus for abstaining when a question is genuinely beyond the model’s knowledge.
- Reasoning-enhanced rewards: score how good the model’s thinking process is, not just the final answer.
Surprisingly, the simple ternary reward usually worked best.
To find which questions the model truly doesn’t know, they probed its “knowledge boundary” by sampling many answers. If none were correct, they labeled the question as “out-of-knowledge” and trained the model to say “I don’t know” for those.
Main Findings and Why They Matter
In tests on four tough question-answering benchmarks (CRAG, NaturalQuestions, HotpotQA, MuSiQue), and with different LLMs (like Llama and Qwen), TruthRL:
- Cut hallucinations by up to 28.9%. Fewer wrong, made-up answers.
- Improved overall truthfulness by 21.1%. Better balance of being right and admitting uncertainty.
- Worked both with and without retrieval. Retrieval means the model can look up documents. Even when those documents are noisy or misleading, TruthRL helped the model resist being tricked.
- Helped models recognize their “knowledge boundary.” On very hard questions where almost no method gets the right answer, TruthRL’s models mostly said “I don’t know” instead of guessing.
- Was robust to “hallucination-baiting” questions (like multiple-choice comparisons that tempt guessing). TruthRL kept hallucinations low.
- Beat other training styles:
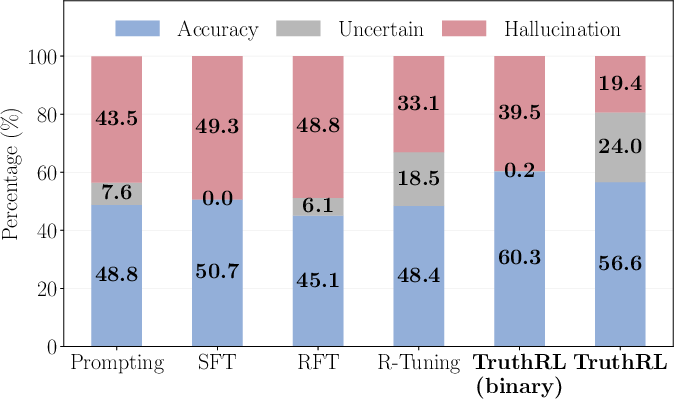
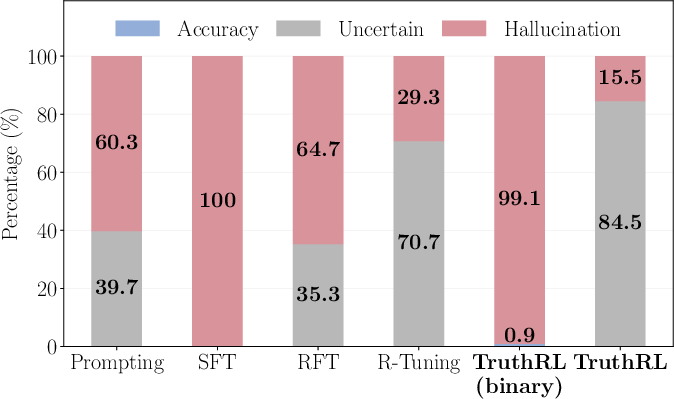
- Supervised fine-tuning (SFT): boosted accuracy but often killed abstaining and increased hallucinations.
- Vanilla RL with a binary reward (just right vs. wrong): gave high accuracy but also high hallucinations and almost no abstentions.
- Offline/semi-online RL (like DPO): helped a bit but was inconsistent. TruthRL’s online training did better.
In short, focusing on truthfulness—not just accuracy—produced models that are safer and more reliable.
Implications and Impact
This work suggests a simple but powerful change in how we train LLMs:
- Rewarding correct answers, tolerating honest “I don’t know,” and penalizing wrong answers leads to more trustworthy models.
- This is especially important in high-stakes areas like medicine or law, where a wrong confident answer can be harmful.
- The approach scales across different model sizes and datasets.
- It shows that good training goals (the “learning objective”) matter as much as big models or more data.
If widely adopted, TruthRL could help build AI systems that people can rely on—not because they always answer, but because they know when not to.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of unresolved issues the paper leaves open. Each item is framed to be concrete and actionable for future research.
- Truthfulness metric design: The evaluation sets w1=1, w2=0, w3=1 (favoring accuracy minus hallucination, without rewarding abstention). Explore principled weighting schemes, task-dependent weights, and adaptive/dynamic weighting that explicitly values appropriate abstention.
- Abstention detection: “Uncertain” is operationalized via “I don’t know.” Develop robust detectors for abstention that handle paraphrases, hedged language, mixed responses (partial answer + uncertainty), and multi-lingual cases to prevent gaming and misclassification.
- Verifier reliability: Training and evaluation depend on LLM-based judges; quantify judge error, bias, and susceptibility to reward hacking. Establish standardized, cross-judge agreement metrics, human validation, and robust aggregation to ensure reliable reward signals.
- Rule-based vs. LLM-based verification: Rule-based verification failed, but the paper does not analyze hybrid or improved rule-based schemes (e.g., semantic matching, fuzzy normalization, passage-grounded string checks). Investigate combined verifiers for stability and cost-efficiency.
- Reward hacking risks: Assess whether models learn to exploit the judge (e.g., phrasing that persuades the judge, superficial “uncertainty” tokens). Design adversarial tests and safeguards against reward hacking (e.g., randomized judge prompts, multi-judge ensembles).
- Partial correctness and evidence-grounding: Ternary reward collapses nuanced outcomes into correct/uncertain/incorrect. Study graded rewards for partial correctness, citation-based support, and evidence-grounded truthfulness (e.g., rewarding supported claims, penalizing unsupported ones).
- Knowledge boundary identification: OOK labeling via sampling 256 responses is approximate and expensive. Evaluate sensitivity to sample size, error rates, distribution shift, and propose principled, model-agnostic OOK detection (e.g., calibration-based thresholds, uncertainty estimators).
- Calibration and confidence: Confidence grouping is used but the confidence measure is not formally defined. Establish standardized confidence metrics (e.g., token-level entropy/log-prob aggregates), proper calibration procedures, and threshold selection strategies tied to abstention.
- Online RL design choices: GRPO group size, advantage normalization, and KL regularization are not ablated. Systematically study hyperparameters’ effects on stability, sample efficiency, abstention behavior, and truthfulness outcomes.
- Compute and cost analysis: Online RL with LLM judges and large sampling is computationally heavy. Provide detailed cost-per-gain comparisons (tokens, wall-clock time, GPU hours) vs. SFT/RFT/DPO to inform practical deployment.
- Robustness to adversarial inputs: Only one type of hallucination-baiting (comparison-style multiple choice) is tested. Broaden adversarial evaluations (jailbreaks, misleading premises, contradictory contexts, long-form reasoning traps) and measure abstention vs. correction.
- Retrieval reliability: The paper notes RAG can be noisy but does not analyze retrieval quality’s impact. Quantify model behavior under controlled retrieval corruption (wrong/contradictory documents), reliability estimation of retrieved evidence, and abstention triggers when evidence is suspect.
- Evidence attribution: TruthRL does not enforce citing sources. Explore reward designs that require citations, verify citation correctness, and penalize claims with unsupported or mismatched evidence.
- Generalization beyond CRAG training: Models are trained only on CRAG; evaluate generalization to unseen domains and high-stakes areas (medical, legal), multi-lingual QA, and non-encyclopedic knowledge to validate cross-domain robustness.
- Long-form and generative tasks: TruthRL is evaluated on factoid QA. Extend to summarization, multi-paragraph answers, code generation, and instruction-following where “truthfulness” and abstention are less clear; define outcome/reasoning/evidence rewards for open-ended outputs.
- Multi-hop reasoning: HotpotQA/MuSiQue are included, but the reward does not explicitly model multi-hop consistency or intermediate correctness. Investigate step-level rewards, proof consistency checks, and penalize reasoning drift across hops.
- Reasoning rewards: Heuristic reasoning rewards yielded mixed outcomes. Develop principled, scalable reasoning-quality metrics (e.g., structured proofs, entailment checks), and study how to balance outcome vs. reasoning rewards without degrading accuracy or truthfulness.
- Abstention-user experience: The paper optimizes abstention without exploring user experience. Design policies that accompany abstention with next actions (e.g., “what info is missing,” “how to retrieve it”), escalation strategies, and interactive uncertainty communication.
- Hallucination vs. coverage trade-off: Binary reward maximizes accuracy but suppresses abstention; ternary improves truthfulness but can reduce coverage. Formalize the trade-off and define application-specific targets (e.g., acceptable coverage given risk profile).
- Evaluation with humans: All correctness and reasoning evaluations rely on LLM judges. Include human annotation studies, inter-annotator agreement, and error analyses to calibrate LLM judgments.
- Statistical robustness: Provide variance across seeds, confidence intervals, and significance testing for reported improvements; quantify run-to-run stability of GRPO vs. DPO/SFT baselines.
- Safety interactions: Truthfulness reductions do not guarantee safety. Analyze interactions with harmful content policies, refusal behavior, and alignment trade-offs (e.g., truthful yet unsafe suggestions).
- Continuous learning and knowledge updates: Study how TruthRL adapts to evolving knowledge (temporal drift), data freshness, and continual training without catastrophic forgetting or truthfulness degradation.
- Integration with tool use: Explore coupling TruthRL with tools (web search, calculators, databases) and tool reliability checks, rewarding the model’s choice to use tools or abstain when tools are unreliable.
- Cross-lingual and cultural contexts: Truthfulness and abstention detection may be language- and culture-dependent. Evaluate cross-lingual generalization and design language-agnostic abstention/verification mechanisms.
- Metric alignment with stakes: Truthfulness is treated uniformly across tasks. Develop risk-sensitive metrics and rewards that weight hallucinations more in high-stakes contexts (e.g., medicine), guiding abstention thresholds accordingly.
- Dataset biases and coverage: CRAG/NQ/HotpotQA/MuSiQue emphasize specific knowledge types. Audit dataset biases (topics, answer styles), and evaluate on domain-specific benchmarks with differing uncertainty profiles.
- Policy interpretability: Provide mechanistic or behavioral analyses of how TruthRL changes token-level distributions, uncertainty expressions, and internal representations to better understand learned abstention behavior.
- Deployment guidance: Offer best-practice recipes (e.g., judge selection, reward scaling, KL coefficients, group size) and failure modes to facilitate reproducible, reliable deployment in production settings.
Practical Applications
Immediate Applications
Below is a concise set of actionable, sector-linked use cases that can be deployed now using the paper’s TruthRL framework (GRPO with a ternary reward) and its demonstrated robustness across LLM backbones and retrieval/non-retrieval setups.
- Enterprise knowledge assistants (Software, IT, HR, Customer Support)
- What to deploy: Fine-tune existing RAG chatbots with TruthRL to reduce hallucinations and enable principled abstention (“I don’t know”) when content is outside model knowledge.
- Workflow: Add an LLM-based verifier to the RL loop; enable abstention-aware routing to a human or follow-up retrieval; track Acc/Unc/Hall in a truthfulness KPI dashboard.
- Dependencies/assumptions: Reliable LLM judge; sufficient compute for online RL; quality retrieval corpora; product acceptance of abstentions.
- Clinical documentation and triage assistants (Healthcare)
- What to deploy: TruthRL-tuned assistants that consult vetted medical guidelines via RAG and abstain when uncertain, escalating cases to clinicians.
- Workflow: Ternary reward incentivizes correct advice and discourages risky guesses; confidence thresholds trigger human review.
- Dependencies/assumptions: Curated medical sources; regulatory and liability alignment; robust verifier; clear escalation policies.
- Legal research and contract review (Law)
- What to deploy: TruthRL-trained legal QA that cites authoritative sources and abstains on ambiguities or hallucination-baiting prompts.
- Workflow: Integrate case-law/contract databases; add “safe-citation” checks; abstention triggers clarification or a human lawyer review.
- Dependencies/assumptions: High-quality legal corpora; strict source attribution; acceptance of non-answers in workflows.
- Financial research and compliance QA (Finance)
- What to deploy: Assistants that query filings, regulations, or policies, returning accurate responses or abstaining for uncertain cases.
- Workflow: Truthfulness gate (LLM judge) before user delivery; route uncertain items to compliance analysts; maintain audit logs.
- Dependencies/assumptions: Up-to-date, curated corpora; governance of escalations; compute for online RL updates.
- Uncertainty-aware tutoring systems (Education)
- What to deploy: Tutors trained with TruthRL that provide correct explanations when confident and abstain otherwise, guiding learners to references or asking clarifying questions.
- Workflow: Confidence-calibrated outputs; abstention prompts retrieval of examples or follow-up questions.
- Dependencies/assumptions: Acceptance of “I don’t know” in learning UX; domain-specific content for retrieval; verifier reliability.
- Moderation triage and review routing (Software/Safety)
- What to deploy: Moderation assistants that abstain on borderline classifications and escalate to human moderators.
- Workflow: Ternary reward discourages confident misclassifications; abstention-aware routing reduces false positives/negatives.
- Dependencies/assumptions: Defined thresholds; human review availability; measured latency overhead.
- Customer support decision support (Software/Customer Support)
- What to deploy: TruthRL-trained agents that provide answers when confident and escalate tickets when uncertain.
- Workflow: Confidence gating; abstention triggers more retrieval or handoff; monitor truthfulness over time.
- Dependencies/assumptions: Ticket semantics are captured well; acceptable increase in abstentions; reliable verifier.
- Truthfulness monitoring and model evaluation (Industry/Academia)
- What to deploy: A Truthfulness KPI dashboard tracking Accuracy, Uncertainty, and Hallucination; periodic audits with multiple LLM judges.
- Workflow: Continuous evaluation under real prompts; majority@k analysis; judge-robustness checks.
- Dependencies/assumptions: Stable evaluator(s); evaluation budget; consensus on weighting (w1, w2, w3) for truthfulness score.
- Developer toolkit for GRPO with ternary reward (Software/ML Ops)
- What to deploy: A fine-tuning library that wraps GRPO + LLM-based verifier + abstention-aware reward schema for open-source LLMs (e.g., Llama, Qwen).
- Workflow: Templates for non-retrieval and RAG; hooks for confidence calibration; CI/CD integration.
- Dependencies/assumptions: GPUs; verified datasets; reproducible verifier prompts.
- Confidence-calibrated APIs and UX components (Software/Product)
- What to deploy: APIs that return an answer, confidence, and an abstention flag; UX patterns that normalize “I don’t know.”
- Workflow: Confidence thresholds; user-facing rationales; optional follow-up retrieval.
- Dependencies/assumptions: Product acceptance of abstentions; calibration validated in-domain.
- Search and assistance for ambiguous queries (Software/Consumer)
- What to deploy: Assistants that abstain on ambiguous or insufficiently grounded queries and proactively ask for clarification.
- Workflow: Detect ambiguity; trigger clarifying questions or targeted retrieval; measure reduction in hallucination-bait failures.
- Dependencies/assumptions: Conversation design; retrieval responsiveness; user tolerance for extra steps.
Long-Term Applications
Below are forward-looking uses that require further research, scale-up, or ecosystem development, informed by the paper’s findings on reward design, verifiers, online RL, and reasoning signals.
- Sector-wide standards for truthfulness metrics (Policy/Standards)
- What to build: Procurement and compliance guidelines mandating truthfulness KPIs (Acc/Unc/Hall) and judge-robust evaluation protocols.
- Dependencies/assumptions: Cross-stakeholder consensus; standardized benchmarks; multi-judge evaluation services.
- Verifier-as-a-Service (Software/Platform)
- What to build: Robust, ensemble LLM-based verifiers with semantic equivalence, partial credit, and adversarial robustness.
- Dependencies/assumptions: Ongoing verifier R&D; cost-effective inference; mitigation against “judge hacking.”
- Continuous online RL with privacy and safety (Software/ML Ops)
- What to build: Production pipelines for online GRPO fine-tuning using safe user feedback streams, with strong privacy guarantees.
- Dependencies/assumptions: Feedback governance; drift detection; secure data handling; cost controls.
- Truthfulness-aware robotics and autonomous systems (Robotics/Safety)
- What to build: Language-driven planners that abstain or seek human input when uncertain about instructions or environment, reducing risky actions.
- Dependencies/assumptions: Grounded perception; integration with control stacks; adaptation beyond QA to planning and execution.
- Multi-objective RL for truthfulness and reasoning (Software/Research)
- What to build: Stable reward designs that jointly optimize outcome correctness, abstention behavior, and reasoning quality.
- Dependencies/assumptions: Better reasoning evaluators; principled reward shaping; training stability at scale.
- Joint retriever–generator optimization for truthfulness (Software/IR)
- What to build: RL systems that co-train retrieval and generation to maximize truthfulness under noisy corpora, including abstention-aware retrieval fallback.
- Dependencies/assumptions: Access to large, evolving corpora; retriever metrics aligned with truthfulness; pipeline complexity.
- Hallucination-bait detection and defense (Software/Safety)
- What to build: Meta-classifiers and policies that identify prompts prone to inducing overconfident errors and raise abstention thresholds or demand citations.
- Dependencies/assumptions: Robust bait detectors; minimal UX friction; domain tuning.
- Cross-model truthfulness alignment (Software/Platform)
- What to build: Methods that transfer truthfulness behavior across LLM families and sizes, ensuring consistent performance under different judges.
- Dependencies/assumptions: Interoperability; cross-model evaluation suites; licensing constraints.
- Sector-specific certification and audit trails (Policy/Compliance)
- What to build: Auditable logs of abstentions, escalations, and citations; certification programs for “truthful assistants” in regulated industries.
- Dependencies/assumptions: Regulatory buy-in; standardized audit schemas; privacy compliance.
- Consumer-grade assistants with truthfulness gating (Daily Life/Consumer Tech)
- What to build: Personal assistants that clearly signal uncertainty, abstain without bluffing, and propose safe next steps (retrieve, ask human, defer).
- Dependencies/assumptions: UX patterns that maintain user trust; localized content; device resource constraints.
- Emergency and disaster information assistants (Public Safety)
- What to build: Systems that avoid hallucinated guidance, abstain when not grounded in official sources, and escalate to reliable channels.
- Dependencies/assumptions: Real-time access to trusted feeds; stringent verification; public-sector coordination.
Cross-cutting assumptions and dependencies
- High-quality LLM-based verifiers materially improve training signals; rule-based verifiers can misjudge semantic correctness and cause over-abstention.
- Compute and engineering resources are needed for online RL (GRPO), multi-judge evaluations, and continuous monitoring.
- Retrieval quality and corpus curation strongly influence truthfulness; abstention should trigger better retrieval or escalation.
- Product and policy acceptance of abstentions is critical; workflows must normalize “I don’t know” and define clear escalation paths.
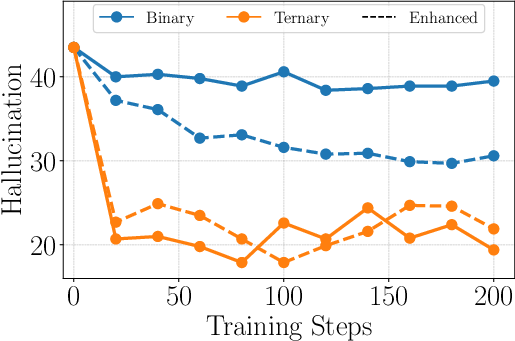
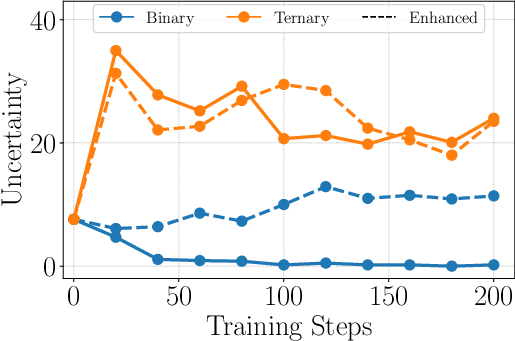
- Ternary reward design is generally superior to binary for truthfulness; adding reasoning rewards requires careful balancing to avoid outcome degradation.
Glossary
- Ablation study: A controlled analysis where components of a method are systematically removed or varied to assess their impact. "In-depth ablation study demonstrates that vanilla accuracy-driven methods, such as supervised fine-tuning or RL with a binary reward, struggle to balance factual correctness and uncertainty."
- Abstention: The model choosing not to answer when uncertain (e.g., responding “I don’t know”). "and treats abstentions neutrally, thereby leading to greater truthfulness."
- Advantage (estimated advantage): In policy optimization, a measure of how much better a specific action (response) is compared to the average in a group or baseline. " is the estimated advantage for response , computed using a group of rewards corresponding to the outputs within each group:"
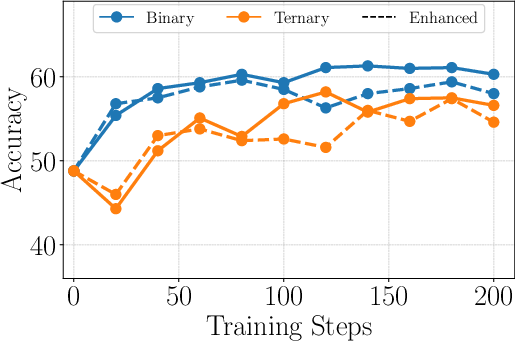
- Binary reward: A reward scheme assigning positive reward for correct outputs and negative for incorrect ones, without distinguishing abstention. "Binary is a variant of our method that uses a binary reward, achieving the highest accuracy but also exhibiting a high hallucination rate"
- Calibrated decoding: A decoding strategy aimed at aligning model confidence with accuracy. "calibrated decoding~\citep{kadavath2022self}"
- Contrastive decoding: A decoding method that contrasts model outputs to reduce errors such as hallucinations. "contrastive decoding~\citep{chuangdola}"
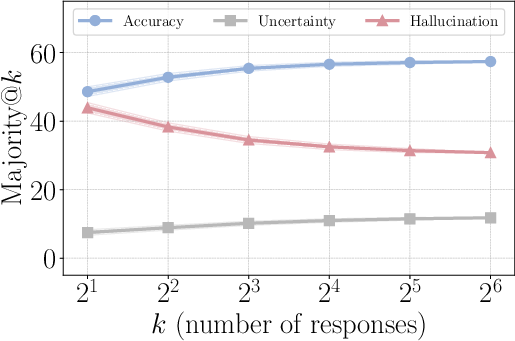
- CRAG: A knowledge-intensive benchmark used for evaluating retrieval and truthfulness in LLMs. "Scaling curve of prompting and vanilla SFT/RL methods on the CRAG benchmark~\citep{yang2024crag}"
- Direct Preference Optimization (DPO): An offline RL-style preference optimization method for aligning models using preference data. "Comparison between Offline RL (DPO), Semi-Online RL (Iterative DPO), and Online RL (TruthRL)"
- Group Relative Policy Optimization (GRPO): An online RL method that optimizes a policy using group-wise relative advantages and KL regularization. "We implement TruthRL using GRPO~\citep{shao2024deepseekmath}, an online RL method that optimizes the following objective:"
- Hallucination: When a model generates fluent but factually incorrect content. "compared to vanilla RL, TruthRL significantly reduces hallucinations by 28.9\%"
- Hallucination-baiting questions: Inputs designed or prone to induce model hallucinations, such as tricky multiple-choice comparisons. "TruthRL is robust to hallucination-baiting questions"
- Importance ratio: The ratio used in off-policy/on-policy corrections, weighting actions by current vs. reference policy likelihood. " denotes the importance ratio,"
- Iterative DPO: A semi-online extension of DPO where preference data and fine-tuning are iteratively refreshed. "Semi-Online RL (Iterative DPO)"
- KL divergence: A measure of divergence between two probability distributions used as a regularizer in RL fine-tuning. "$-\beta \mathbb{D}_{KL}\left(\pi_{\theta} || \pi_{\text{ref}\right)$"
- Knowledge boundary: The implicit limit of what a model knows; recognizing it helps avoid hallucinations. "enhancing the capability of LLMs to recognize their knowledge boundary"
- Knowledge boundary probing: A method to detect questions outside a model’s knowledge by sampling many outputs to see if any are correct. "using a knowledge boundary probing mechanism"
- Knowledge-enhanced reward: A reward scheme that conditions rewards on whether a question is out-of-knowledge, positively reinforcing appropriate abstention. "a knowledge-enhanced variant treats abstention as positive when the model genuinely lacks knowledge."
- LLM-based verifier: Using a LLM as a judge to evaluate correctness and provide reward signals. "LLM-based verifier provides more reliable training signals than rule-based verifier."
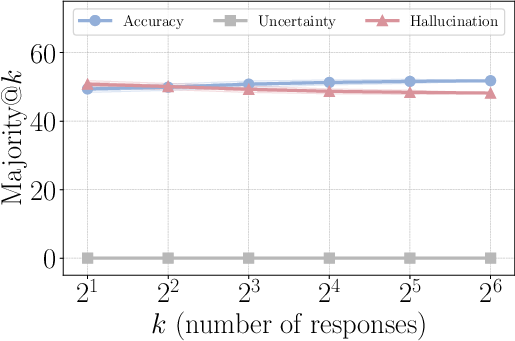
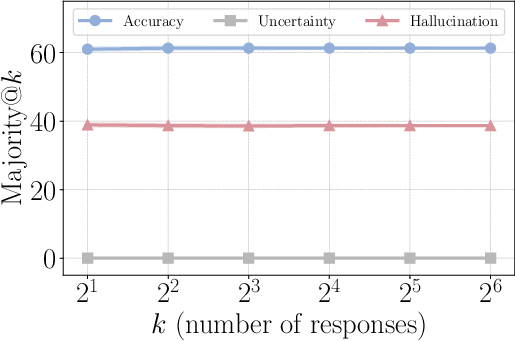
- Majority@: An evaluation/aggregation approach where the most frequent answer among k sampled responses is taken as the final prediction. "strong potential in majority@ scaling"
- MuSiQue: A multi-hop reasoning dataset designed to assess compositional question answering. "MuSiQue~\citep{trivedi2022musique}"
- NaturalQuestions (NQ): A large-scale question answering dataset sourced from real user queries. "NaturalQuestions (NQ)~\citep{kwiatkowski2019natural}"
- Offline RL: RL that learns from fixed datasets without online interaction during training. "Offline RL (DPO)"
- Online RL: RL that updates the policy through on-policy interactions during training. "an online RL method"
- Out-of-knowledge (OOK) questions: Queries that lie beyond the model’s accessible knowledge at training/inference time. "out-of-knowledge (OOK) questions"
- Parametric knowledge: Information stored within the model parameters rather than retrieved externally. "outside their parametric knowledge."
- Reasoning-enhanced variant: A reward design that includes signals assessing the quality of the reasoning process, not just the final answer. "a reasoning-enhanced variant builds on the above outcome-based reward by incorporating additional reward signals that evaluate the quality of the model’s reasoning process."
- Reasoning reward: A reward component that explicitly evaluates the reasoning steps or chain-of-thought quality. "incorporating the reasoning reward $r_{\text{reason}$"
- Rejection sampling fine-tuning (RFT): A fine-tuning strategy selecting model-generated traces (including abstentions for OOK) based on quality or correctness. "rejection sampling fine-tuning (RFT)"
- Retrieval-augmented generation (RAG): A technique where external documents are retrieved and used to condition the model’s generation. "retrieval-augmented generation (RAG)"
- Rule-based verifier: A deterministic evaluator (e.g., string matching) used to judge correctness, often brittle compared to LLM judges. "rule-based verifier"
- Scaling curve: A plot showing performance changes as a function of scale factors (e.g., number of samples k). "Scaling curve of prompting and vanilla SFT/RL methods"
- Semi-Online RL: A hybrid training setup that alternates between data collection and offline preference optimization. "Semi-Online RL (Iterative DPO)"
- Self-consistency sampling: A decoding strategy that samples multiple reasoning paths and aggregates to improve reliability. "self-consistency sampling~\citep{wang2022selfconsistency}"
- Supervised fine-tuning (SFT): Training a model to maximize likelihood of ground-truth outputs given inputs. "Supervised fine-tuning (SFT)."
- Ternary reward: A reward scheme distinguishing correct (+1), uncertain/abstain (0), and incorrect (−1) outputs. "a simple yet effective ternary reward that distinguishes correct answers, hallucinations, and abstentions."
- Truthfulness score: A composite metric combining accuracy, abstention/uncertainty, and hallucination rates with weights. "we define the truthfulness score as a weighted combination:"
- Uncertainty rate: The fraction of cases where the model abstains (e.g., responds “I don’t know”). "uncertainty rate "
- Vanilla RL: Standard accuracy- or reward-only optimized RL without explicit uncertainty/abstention handling. "compared to vanilla RL, TruthRL consistently reduces hallucination"
- Vanilla SFT: Conventional SFT focused on maximizing accuracy, often suppressing abstention and increasing hallucinations. "In vanilla SFT/RL, the model is optimized solely for accuracy,"
Collections
Sign up for free to add this paper to one or more collections.