- The paper characterizes knowledge collapse across three distinct stages, revealing that LLMs maintain fluency even as factual accuracy deteriorates.
- It employs a cyclical synthetic training framework with varying synthetic ratios to measure entropy decline, vocabulary narrowing, and accuracy loss.
- Domain-specific synthetic training is introduced as a mitigation strategy that significantly delays collapse and preserves semantic fidelity.
Knowledge Collapse in LLMs: When Fluency Survives but Facts Fail under Recursive Synthetic Training
Introduction
This paper provides a rigorous empirical and methodological analysis of "knowledge collapse" in LLMs subjected to recursive synthetic training. The authors distinguish knowledge collapse from general model collapse by focusing on the phenomenon where factual accuracy degrades while surface fluency and instruction-following persist, resulting in "confidently wrong" outputs. The study is motivated by the increasing reliance on synthetic data for LLM training due to the scarcity of high-quality human-written content and the contamination of internet sources with AI-generated text. The work systematically characterizes the collapse process, its conditional dependence on prompt format, and proposes domain-specific synthetic training as a mitigation strategy.
Experimental Framework
The authors employ a cyclical workflow for recursive synthetic training, iteratively generating datasets, evaluating models, and fine-tuning across multiple generations.
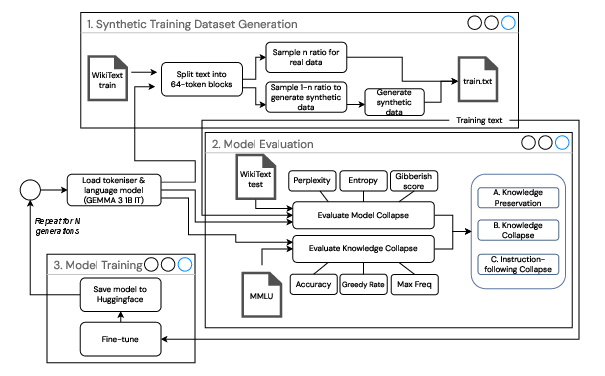
Figure 1: Cyclical workflow for recursive synthetic training: dataset generation, dual evaluation, and fine-tuning repeated across generations.
Training is performed on the GEMMA 3 1B IT model using WikiText-2 as the base corpus, with synthetic fractions α∈{0.25,0.50,1.0} controlling the proportion of synthetic data. Evaluation is conducted on five MMLU subjects reformatted to short-answer style to isolate factual retention. The framework combines model-centric metrics (perplexity, entropy, gibberish score) and task-centric metrics (accuracy, greedy rate, option bias, judge score, entailment score) to detect and characterize collapse phases.
Three-Stage Knowledge Collapse
The central contribution is the definition and empirical validation of a three-stage knowledge collapse process:
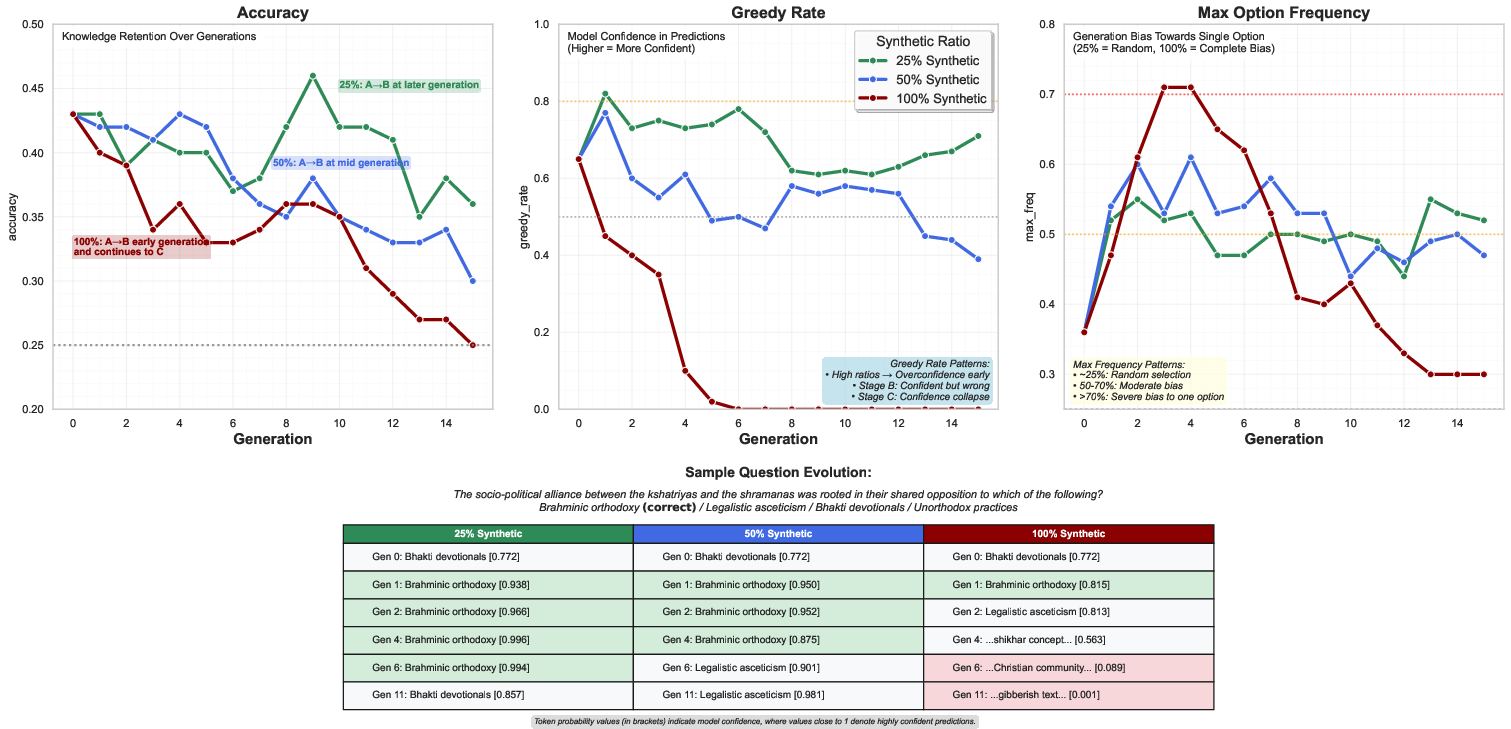
The transition from Stage A to Stage B is particularly hazardous for downstream applications, as models remain fluent and confident while factual reliability erodes. The onset and trajectory of collapse are strongly modulated by the synthetic data ratio: lower ratios delay collapse, while higher ratios accelerate it. Distributional analysis reveals rapid entropy decline and vocabulary narrowing at high synthetic ratios, with lower ratios preserving discriminative capability despite accuracy loss.
A key finding is that collapse dynamics are conditional on instruction format rather than being prompt-agnostic. Short-answer prompts maintain stability longer, few-shot prompts collapse rapidly, and zero-shot prompts exhibit intermediate degradation.
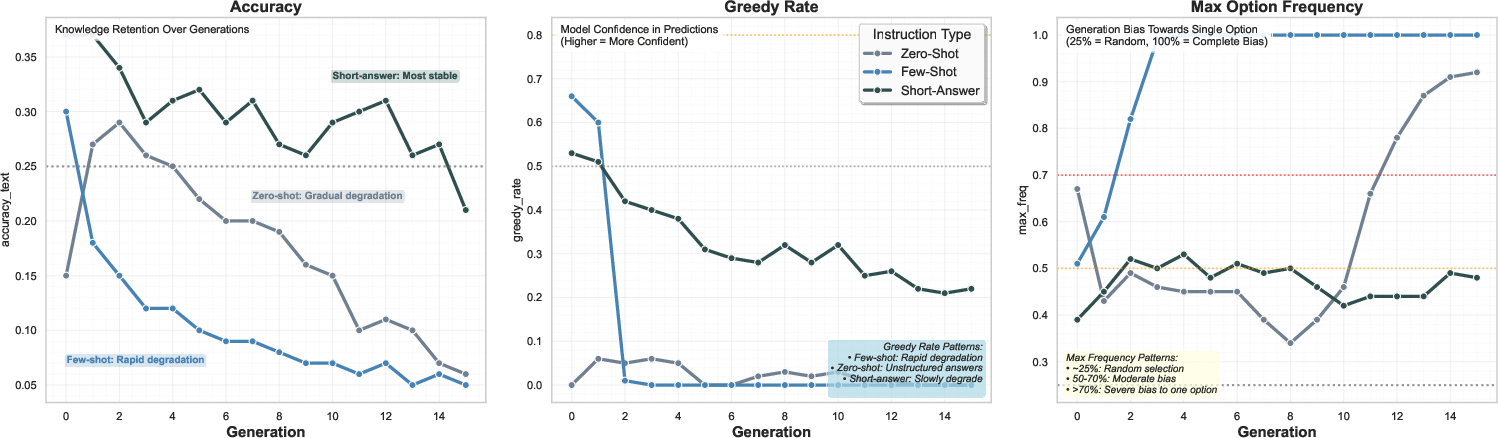
Figure 3: Instruction format sensitivity in knowledge collapse showing conditional degradation patterns.
Statistical analysis (two-way ANOVA) confirms significant main effects and interactions between instruction format and generation, with few-shot prompts exhibiting the earliest collapse. This demonstrates that prompt structure mediates the vulnerability of models to synthetic data artifacts, with complex formats amplifying systematic biases and accelerating collapse.
Distributional and Semantic Degradation
Distributional indicators across generations show that high synthetic ratios induce rapid vocabulary narrowing, increased gibberish scores, and divergence between external validation and internal consistency.
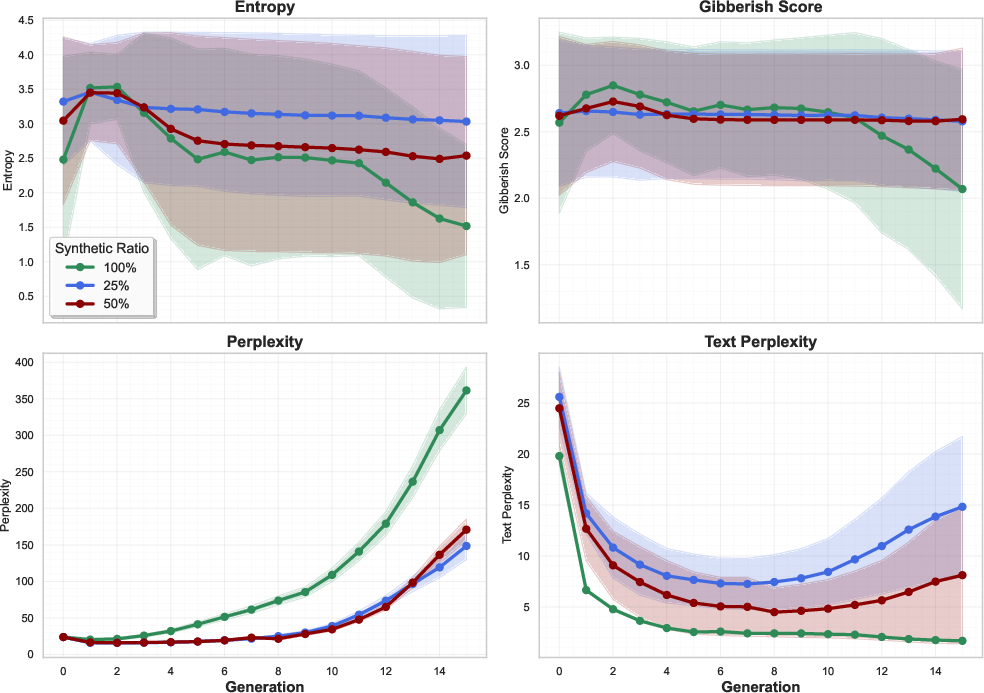
Figure 4: Distributional indicators across generations under different synthetic ratios.
Semantic fidelity metrics (judge and entailment scores) further validate the three-stage framework. Lower synthetic ratios show gradual semantic drift, while 100% synthetic regimes exhibit rapid collapse and entailment illusions, where verbose gibberish creates spurious lexical overlap with gold references.
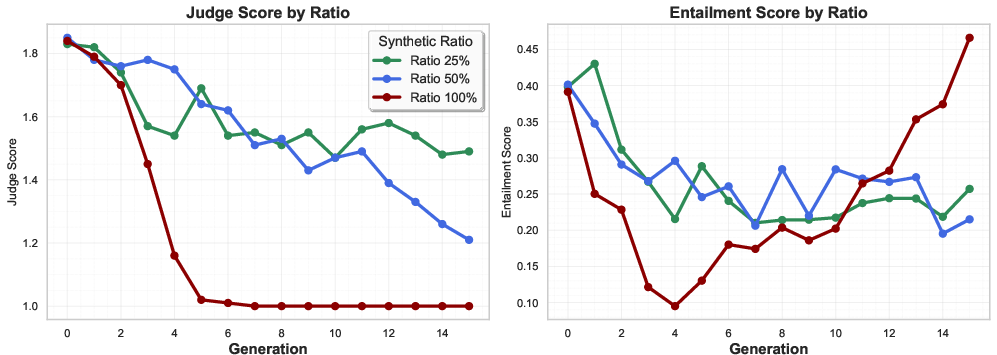
Figure 5: Judge and entailment scores across generations. The 100% synthetic regime shows rapid semantic degradation, while lower ratios exhibit gradual drift, supporting the Stage B "confidently wrong" phenomenon.
Domain-Specific Synthetic Training as Mitigation
The authors propose domain-specific synthetic training as a targeted mitigation strategy. By restricting synthetic data generation to a subject-aligned corpus (World Religions), they achieve a 15× improvement in collapse resistance compared to general synthetic training. Domain-specific models maintain stable accuracy, controlled perplexity growth, and entropy preservation, while general models exhibit rapid degradation.
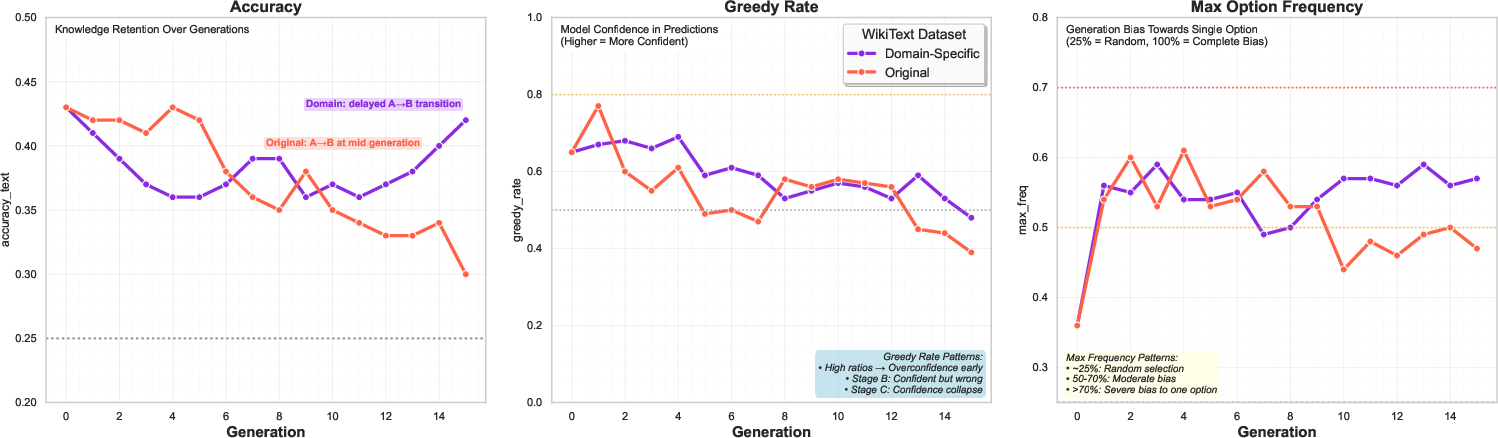
Figure 6: Domain-specific mitigation through WikiText filtering to focus on World Religions content demonstrates superior collapse resistance.
Distributional analysis confirms that domain-specific training preserves lexical diversity and semantic coherence, delaying both knowledge and instruction-following collapse.
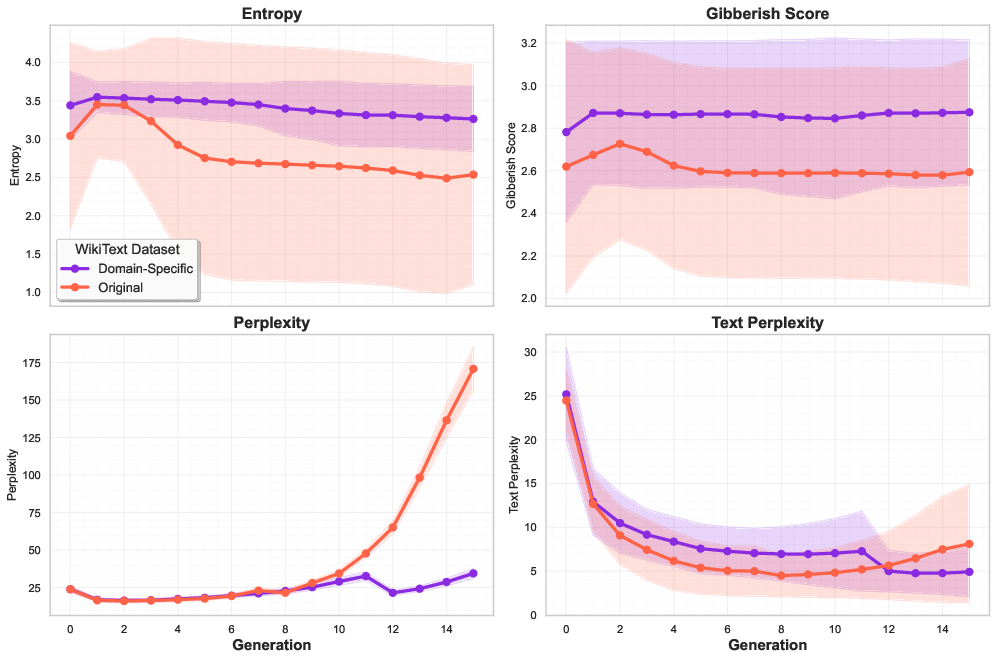
Figure 7: Domain-specific training preserves distributional stability through entropy maintenance and controlled perplexity growth.
Behavioral analysis shows that domain-aligned models maintain superior accuracy, confidence dynamics, and semantic quality across generations.
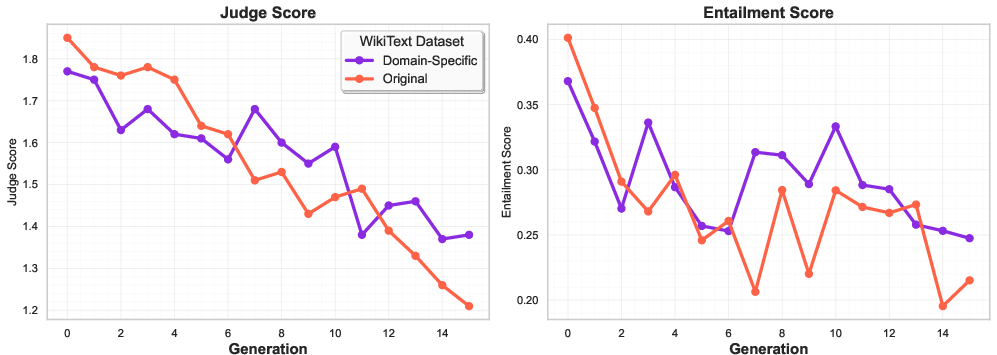
Figure 8: Domain-specific training maintains superior behavioral stability and semantic quality.
Implementation Considerations
The experimental setup is fully reproducible using publicly available datasets (WikiText-2, MMLU) and the GEMMA 3 1B IT model. Training is performed with light-touch updates (0.5 epochs) to enable gradual drift observation. Synthetic data generation employs top-k and top-p nucleus sampling to encourage diversity. Evaluation leverages both automated metrics and LLM-as-judge scoring for semantic fidelity. Domain-specific corpus construction utilizes semantic filtering and reranking with Sentence-BERT and cross-encoder models.
Resource requirements are modest: single GPU (RTX 3090 Ti, 24 GB), with each generation requiring approximately one hour of compute. The framework is scalable to larger models and domains, though the mitigation benefits of domain-specific training are domain-bound and do not generalize to out-of-domain evaluation.
Implications and Future Directions
The identification of knowledge collapse as a distinct, prompt-conditional, three-stage process has significant implications for the sustainable training and deployment of LLMs in accuracy-critical domains. The persistence of fluency and confidence during factual degradation (Stage B) poses safety risks, particularly in applications such as healthcare, law, and education. The demonstrated effectiveness of domain-specific synthetic training suggests that distributional anchoring can delay collapse, but does not eliminate it.
Theoretical implications include the breakdown of neural scaling laws under recursive synthetic training and the need for collapse-aware training protocols. Future research should extend the analysis to larger model scales, more diverse domains, and reasoning-heavy tasks. Predictive frameworks for early detection of collapse onset and adaptive mitigation strategies are critical for robust LLM lifecycle management.
Conclusion
This paper provides a comprehensive characterization of knowledge collapse in LLMs under recursive synthetic training, distinguishing it from general model collapse by its conditional, prompt-dependent nature and the persistence of fluency during factual degradation. The three-stage framework, combined with rigorous empirical analysis and domain-specific mitigation, offers actionable guidance for sustainable AI training in knowledge-intensive applications. The findings underscore the necessity of prompt-aware evaluation and domain-aligned synthetic data strategies to preserve factual reliability in future LLM development.