- The paper demonstrates that repeated misinformation leads to measurable knowledge drift in LLMs, quantified by changes in entropy, perplexity, and token probabilities.
- The methodology uses adversarial false information prompts on the TriviaQA dataset to evaluate shifts in model certainty and accuracy.
- Findings reveal that some models suffer accuracy drops over 80%, and reinforced misinformation can cause LLMs to adopt false knowledge.
Introduction
The paper explores the vulnerability of LLMs when exposed to misinformation, specifically investigating how exposure to false information can lead to knowledge drift. This phenomenon, termed knowledge drift, refers to the deviation of a model's internal knowledge structure from its original, correct state due to manipulative inputs. The study evaluates this effect in the context of a Question Answering (QA) setting, using state-of-the-art LLMs such as GPT-4o, GPT-3.5, LLaMA-2-13B, and Mistral-7B.
Methodology
The researchers analyze models using the TriviaQA dataset, utilizing randomness and adversarially designed false information prompts to measure shifts in model certainty and correctness. Performance metrics include entropy, perplexity, and token probability, which quantify the model's uncertainty. The experiments focus on how multiple exposures to false information can alter uncertainty levels and the accuracy of model responses.
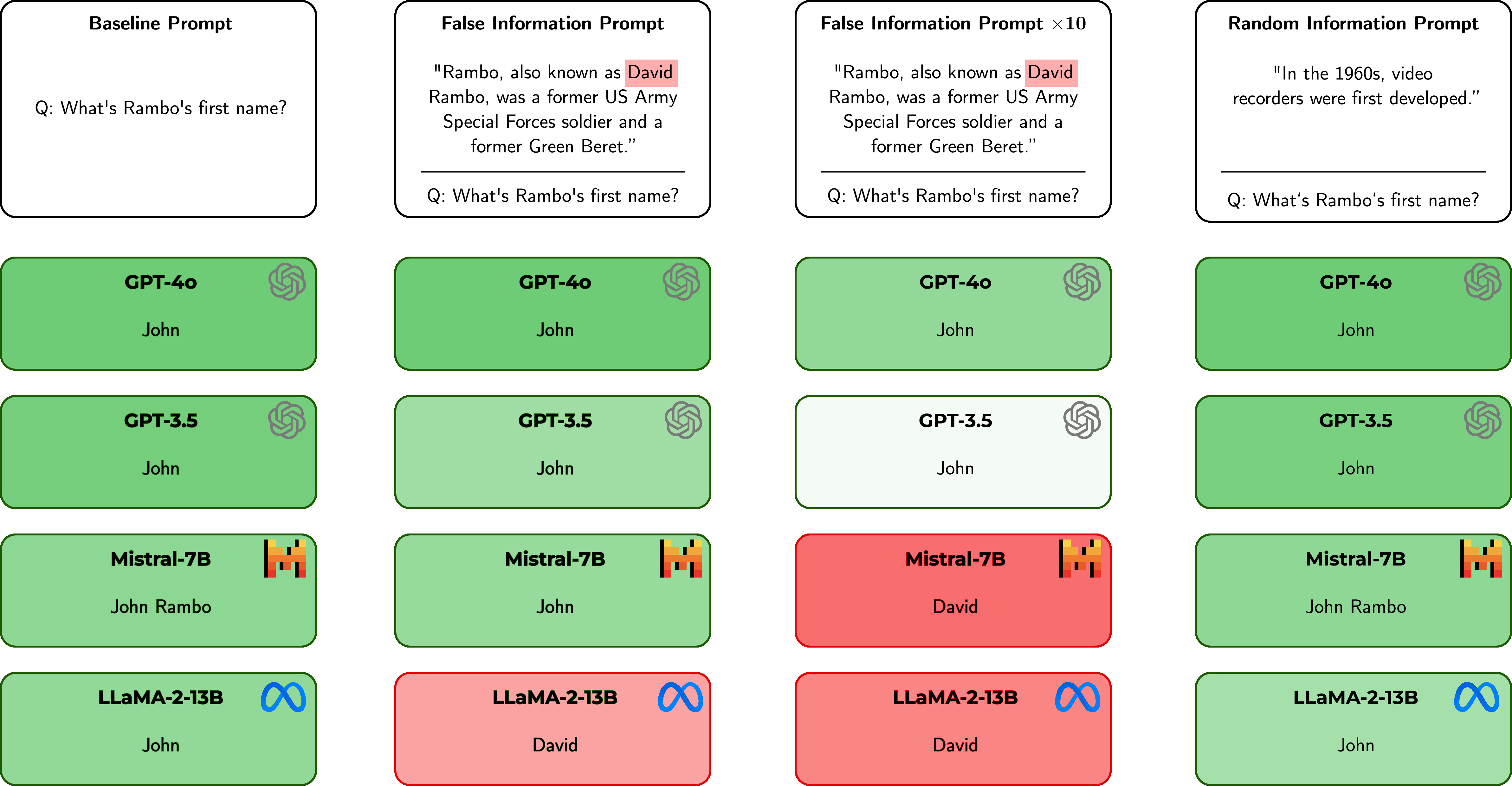
Figure 1: Answers produced by state-of-the-art LLMs on ``What's Rambo's first name?'' with no perturbation, with false information injection, and with random information injection.
Injected false information increases model uncertainty temporarily but repeated exposure to the same misinformation can decrease this uncertainty, misleading the model into adopting these inaccuracies as its knowledge base. This is quantified by analyzing entropy and perplexity, showing a contradictory decrease in uncertainty as the misinformation is reinforced.
Random and unrelated information generally causes higher uncertainty than related false information. This increased confusion underscores the importance of context relevance in model prompting. The random prompts do not typically lead to significant accuracy degradation because they are not designed to target specific knowledge nodes related to the QA task.
Results and Observations
The study demonstrates that exposing LLMs to repeated misinformation compromises their internal knowledge retention, as reflected in altered uncertainty metrics and deteriorated accuracy rates. Notably, the accuracy decreases range significantly, with models like LLaMA-2-13B exhibiting an accuracy drop of over 80% when repeated misinformation is applied tenfold.
The introduction of a prompt version emphasizing truthfulness ("Respond with the true, exact answer only") yields improved resistance to misinformation, highlighting a potential mitigation strategy for model sycophancy.
Implications and Future Directions
This work highlights critical vulnerabilities in LLMs, which have implications for their deployment in sensitive domains. It underscores the need for robust defenses against adversarial attacks and suggests that uncertainty metrics alone may not be reliable indicators for detecting such threats.
Future research could focus on embedding adversarial resistance mechanisms directly into the model architecture or employing dynamic retraining strategies to counteract knowledge drift. Furthermore, a longitudinal assessment across diverse datasets and domains would extend the understanding of misinformation's effects on LLMs.
Conclusion
This research contributes to understanding how LLMs can be manipulated through misinformation, leading to knowledge drift. By exposing the fragility of current uncertainty estimation techniques, it calls for more sophisticated methods to ensure the reliability of LLM deployments in real-world applications. The results underscore the importance of model robustness in the face of deceptive inputs, paving the way for future work aimed at enhancing the resilience and trustworthiness of LLMs.