- The paper introduces PART, a method that reformulates reasoning traces to impair unauthorized distillation while preserving critical information.
- It employs token-level adjustments by removing self-talk tokens and structural reordering techniques to disrupt gradient-based learning in student models.
- Extensive experiments demonstrate that student models experience significant performance degradation, including a 13.5% drop on the AIME benchmark.
The paper, "Information-Preserving Reformulation of Reasoning Traces for Antidistillation" (2510.11545), discusses a novel approach named PART (Preserving Antidistillation Reformulation of Traces) to protect the proprietary intellectual property encapsulated within the reasoning traces generated by LLMs. This method reformulates these traces to impede unauthorized distillation while retaining their informative content for human comprehension.
Introduction to PART
PART targets a critical issue faced by proprietary model providers: the vulnerability of detailed reasoning traces to illicit knowledge distillation by student models. Conventional methods such as providing summaries or entirely omitting traces strip away valuable information. PART employs a calculated reformulation at both the token and structural levels, where reasoning traces retain their informative value for users but lose efficacy for distillation processes.

Figure 1: Overview of PART. Directly exposing original reasoning traces leaves them vulnerable to unauthorized distillation, whereas providing only summaries deprives users of the information contained in the reasoning process.
The PART methodology begins with the removal of self-talk behaviors from tokens. These low-probability tokens (e.g., "Hmm," "Wait") typically have a significant impact on gradient updates during Supervised Fine-Tuning (SFT). By eliminating these tokens, PART disrupts the gradient information vital to the distillation process without degrading understanding for human users.

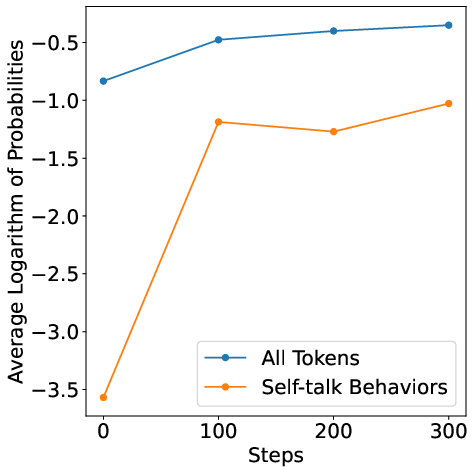
Figure 2: Predicted probabilities of the student model on teacher-generated reasoning traces highlighting low-probability tokens.
At the sequence level, PART rearranges the reasoning trace structure by placing sub-conclusions before the corresponding reasoning steps. This reordering exploits a key divergence in cognitive processing between humans and LLMs, where humans can readily adapt to non-sequential structuring unlike models, which are disrupted by deviation from the linear logical flow.

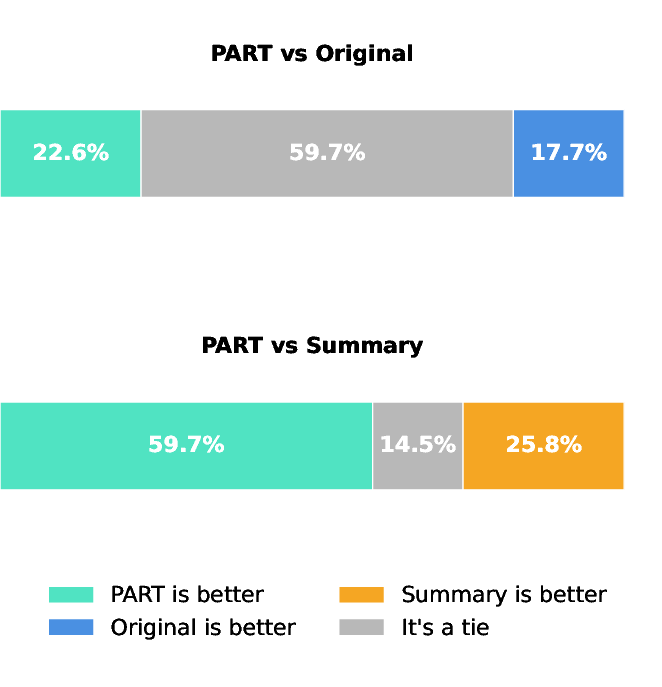
Figure 3: (a) Match ratios under different lexical similarity score thresholds. PART achieves significantly higher match ratios than summary methods. (b) Human judgment shows PART is informatively preferable.
The quality of reformulated traces is evaluated through lexical and semantic similarity measures, as well as human judgment assessments. PART produces high lexical and semantic match ratios, indicating substantial information preservation. Human evaluations further endorse the informativeness of PART-generated traces compared to summary-based approaches.
Extensive distillation experiments reveal significant performance degradation for student models trained on PART-reformulated data as opposed to original traces. Across diverse benchmarks such as mathematical problem solving and coding, the efficacy of PART as an antidistillation mechanism is evident. Notably, even a substantial 32B model witnessed a performance degradation on AIME 2024 from 54.17 to 46.88, marking a 13.5% decrease.
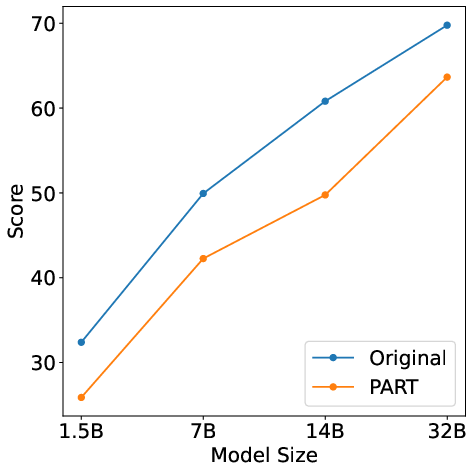
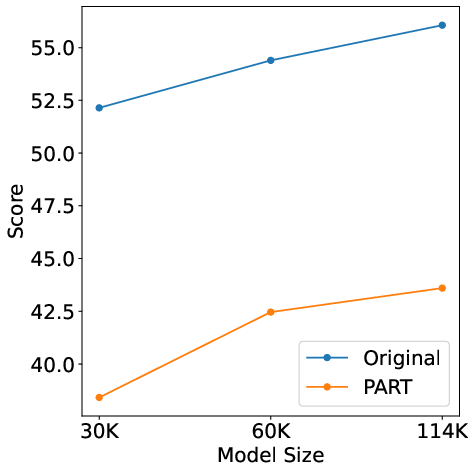
Figure 4: Performance comparison shows consistent performance degradation of models trained on reformulated traces across data scales.
Implementation of PART
To streamline the deployment of PART in real-world settings, a compact reformulation model is developed. Fine-tuned on a paired dataset of original and GPT-4o generated reformulated traces, this model offers efficient processing with minimal computational overhead.
Robustness and Scale Considerations
PART's efficacy is tested across varying data scales and model sizes, displaying robust performance in degrading distillation effectiveness. The framework also incorporates detectability features, akin to watermarking, enabling discernment of PART-reformulated data through significant alterations in keyword frequency distribution.
Conclusion
PART introduces a practical and efficient methodology for safeguarding proprietary reasoning traces against unauthorized distillation. By focusing on preserving the informational content while undermining the distillation potential, PART bridges the gap between protecting model IP and maintaining user accessibility to reasoning processes. Future work in this domain could explore enhancing detectability and optimizing reformulation strategies to further thwart sophisticated distillation attempts.