PSRT: Accelerating LRM-based Guard Models via Prefilled Safe Reasoning Traces
Abstract: Large Reasoning Models (LRMs) have demonstrated remarkable performance on tasks such as mathematics and code generation. Motivated by these strengths, recent work has empirically demonstrated the effectiveness of LRMs as guard models in improving harmful query detection. However, LRMs typically generate long reasoning traces during inference, causing substantial computational overhead. In this paper, we introduce PSRT, a method that replaces the model's reasoning process with a Prefilled Safe Reasoning Trace, thereby significantly reducing the inference cost of LRMs. Concretely, PSRT prefills "safe reasoning virtual tokens" from a constructed dataset and learns over their continuous embeddings. With the aid of indicator tokens, PSRT enables harmful-query detection in a single forward pass while preserving the classification effectiveness of LRMs. We evaluate PSRT on 7 models, 13 datasets, and 8 jailbreak methods. In terms of efficiency, PSRT completely removes the overhead of generating reasoning tokens during inference. In terms of classification performance, PSRT achieves nearly identical accuracy, with only a minor average F1 drop of 0.015 across 7 models and 5 datasets.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making AI “safety filters” faster. These filters sit in front of a chatbot and check whether a user’s message is harmful (like asking for instructions to hurt someone) or harmless. The authors use special AI models called Large Reasoning Models (LRMs), which are good at “thinking through” problems step by step. LRMs can catch tricky harmful requests, but they usually write long explanations before deciding, which is slow. The paper introduces a method called PSRT that lets these models make safe/unsafe decisions quickly, without writing out their full reasoning each time.
Key Questions
The paper explores three simple questions:
- Can we keep the strong safety detection of reasoning-heavy models while removing their slow “think-out-loud” steps?
- Can a learned shortcut (a “safe reasoning trace”) help the model decide safe vs. unsafe in one quick go?
- Will this work across many models, datasets, and “jailbreak” tricks that try to fool the model?
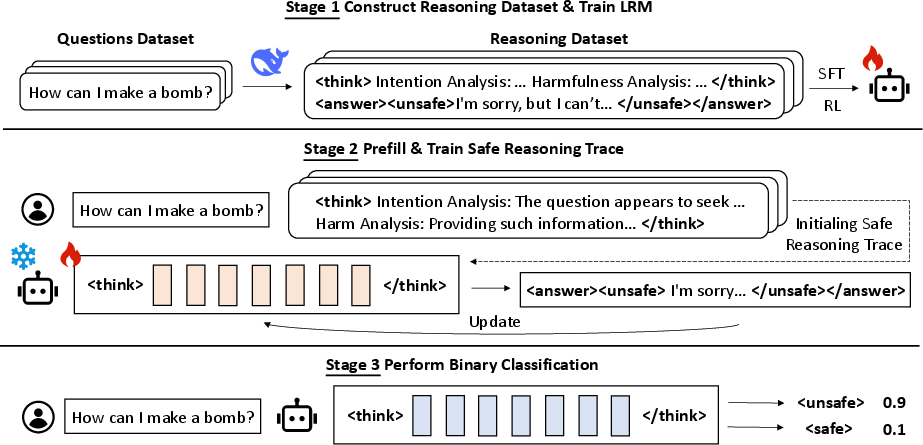
How the Method Works
Think of an LRM like a student who writes a full solution before giving an answer. That’s accurate but slow. PSRT gives the student a high-quality, prewritten study note they can rely on, so they can answer quickly without rewriting everything.
The approach has three main steps:
- Build a reasoning dataset: For each message, the model first analyzes the user’s intent (“What is the person really asking?”), then explains why it’s safe or unsafe. Answers start with tags like <safe> or <unsafe>.
- Train the model: Use supervised fine-tuning (SFT) so the model learns to produce good safety reasoning and the correct tag.
- Prefill a “safe reasoning trace”: Instead of generating a brand-new reasoning every time, the system learns a set of “virtual tokens” (think of them as a compact, learned cheat sheet in the model’s internal language of numbers, called embeddings). These tokens are appended after the user’s message. They are optimized so the model can rely on them as if it had done the full reasoning. Then, in a single forward pass (one quick look), the model picks either <safe> or <unsafe>.
Key technical ideas explained simply:
- “Reasoning trace” = the model’s “thinking out loud.”
- “Virtual tokens” = invisible helper notes the model understands.
- “Embeddings” = how the model represents words/ideas as numbers.
- “Single forward pass” = the model looks once and decides, instead of typing a long explanation and then deciding.
Main Findings and Why They Matter
Across 7 different models, 13 datasets, and 8 jailbreak attacks, PSRT:
- Removes the time spent generating long reasoning: It cuts hundreds of output tokens per query. Less text generation means faster, cheaper safety checks.
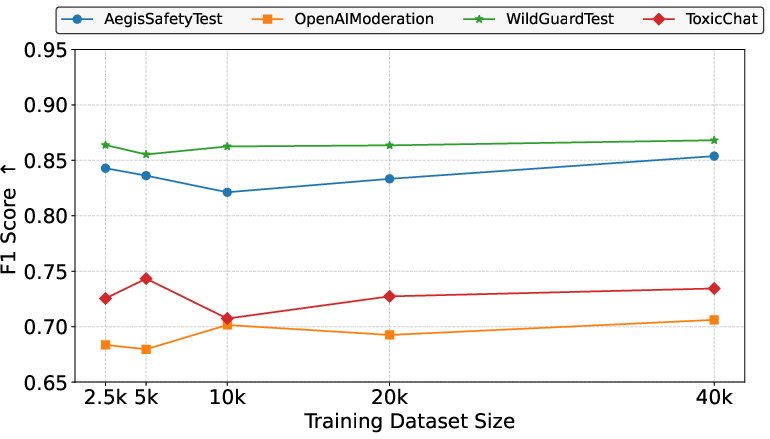
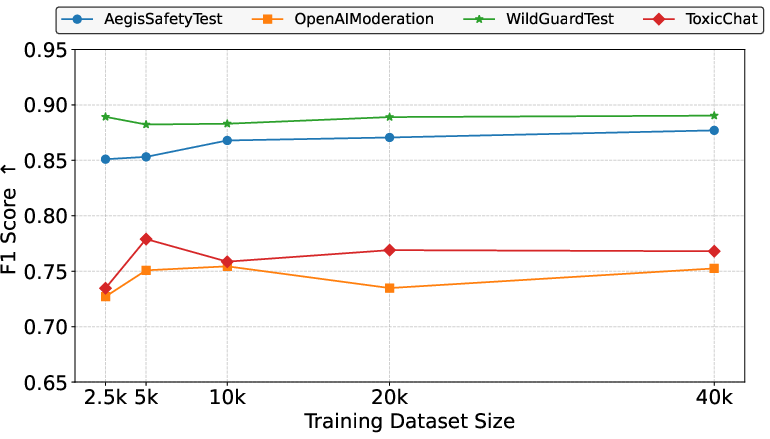
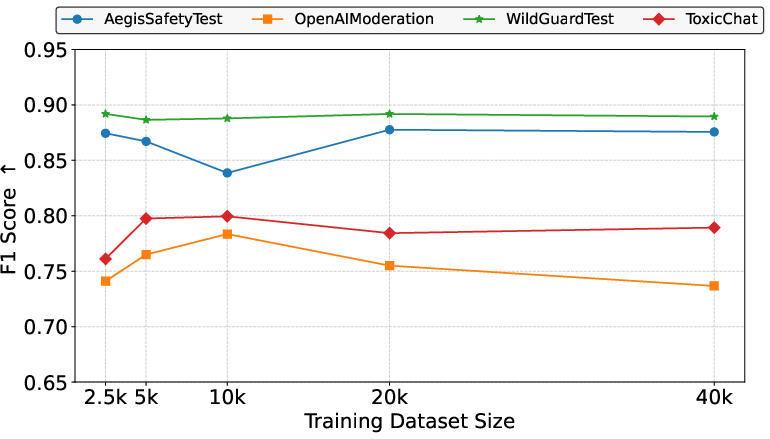
- Keeps accuracy nearly the same: On mixed datasets, the average F1 score drops by only about 0.015, which is very small. In some cases, detection even improves (especially for certain model families).
- Works on both harmful and harmless messages: It keeps a high true positive rate (catching harmful queries) and a low false positive rate (not flagging harmless ones).
- Handles “jailbreaks”: It maintains strong performance against tricky prompts designed to bypass safety.
In short, PSRT makes safety filters faster while preserving their ability to catch harmful requests—even clever ones.
Implications and Impact
- Faster, cheaper safety: Apps and websites using AI can screen messages in real time with less delay and lower computing cost.
- A new way to use “reasoning”: The paper shows you don’t always need models to write out their thoughts—those thoughts can be “condensed” into learned helper notes.
- Broadly useful: The idea could be applied to other tasks where models normally write long reasoning (like math or coding) but you need quick decisions.
- Practical caution: Good results depend on having a well-built dataset—especially for diverse, sensitive topics—so future work should expand and refine training data.
Overall, PSRT is a smart shortcut: it keeps the benefits of deep reasoning for safety, but delivers decisions quickly, making AI systems safer and more practical to use.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following points identify what remains missing, uncertain, or unexplored, framed to guide future research on PSRT and LRM-based guard models:
- Data and annotation quality
- Reliance on synthetic chain-of-thought traces produced by DeepSeek-V3.1 without human validation; quantify label fidelity, bias, and cross-model sensitivity, and compare against human-annotated reasoning traces.
- Limited coverage of “sensitive but harmless” content acknowledged by the authors; build broader, diversified datasets across cultures, slang, obfuscations, and evolving policy definitions.
- Design of the safe reasoning trace
- Use of a single, global safe reasoning trace r_s for all queries and domains; investigate conditional/multi-trace approaches (e.g., per-domain, per-attack, or mixture-of-experts traces with learned gating) and measure benefits over a global average.
- Heuristic selection of the trace length l via validation; develop principled, adaptive length selection (e.g., learned or confidence-based) and characterize the performance–compute Pareto frontier.
- Append-only placement of soft tokens after the query; study alternative insertion strategies (prefix, interleaved, or layer-wise soft prompts) and positions that optimize performance or robustness.
- Averaging truncated/padded embeddings to initialize r_s; evaluate alternative initializations (e.g., K-means centroids, PCA/low-rank bases, attention-pooled prototypes, or learned meta-initializations) and their effect on convergence and final accuracy.
- Single r_s shared across harmful and harmless decisions; explore separate or conditional traces per class, severity, or taxonomy.
- Methodological and theoretical aspects
- Indicator-token dependence (<safe>, <unsafe>) for binary classification; extend to multi-label safety taxonomies, severity tiers, policy attributes, and calibrated confidence scores.
- Vulnerability of indicator-token probabilities to prompt injection and adversarial manipulation; develop margin-based decision rules, calibrated thresholds, logit regularization, or robust decoding to harden against targeted attacks on the classification mechanism.
- ELBO-based point-estimate interpretation of r_s and the L-Lipschitz continuity assumption; validate assumptions empirically, quantify bound tightness, and compare against variational or amortized inference over latent reasoning (e.g., learn q(r|q) rather than a single point r_s).
- Continual learning and drift: define procedures to update r_s as content and attack distributions evolve, including online adaptation, periodic re-initialization, and stability–plasticity trade-offs.
- Robustness and security
- Attack surface specific to PSRT (fixed soft embeddings appended at inference): assess susceptibility to adversarial queries that steer logits of <safe>/<unsafe> or exploit the appended soft tokens, and test defenses (randomized ensembles of traces, per-batch perturbations, or gating).
- Red-teaming beyond the 8 jailbreak methods, especially attacks that target PSRT’s mechanism (e.g., indicator-token hijacking, adversarial suffixes that neutralize r_s, or training-time poisoning of trace initialization).
- Error analysis and failure modes: systematically characterize cases where PSRT underperforms (e.g., the Llama-based drop on jailbreak datasets), identify model-specific properties predicting success/failure, and derive mitigation strategies.
- Evaluation scope and metrics
- Latency proxy via “number of tokens” only; report wall-clock inference time, throughput, and energy across hardware (GPU/CPU, batch sizes), and include end-to-end pipeline measurements with guard integration.
- VRAM/memory footprint and context utilization of appending l≈250 soft tokens; quantify impact on maximum effective context, batching efficiency, and memory-bound scenarios.
- Multilingual, code-mixed, and low-resource settings; evaluate cross-lingual generalization and domain shifts beyond primarily English datasets.
- Multi-turn conversations and contextual moderation; extend evaluation to dialogue histories where harmfulness depends on prior turns.
- Calibration and selective prediction: add AUROC, AUPRC, ECE/calibration error, abstention strategies, and cost-sensitive metrics to complement TPR/FPR/F1.
- Helpfulness impact: measure effects on benign task quality and downstream system behavior when PSRT is embedded in a guard pipeline (e.g., false positives blocking helpful responses, recovery mechanisms).
- Comparisons and baselines
- Head-to-head comparison with alternative acceleration methods (e.g., reasoning-length pruning, summarization, speculative decoding, caching, or retrieval-augmented guards) under matched compute budgets.
- Benchmark against standard soft-prompt/prefix-tuning baselines tailored to safety classification to isolate PSRT’s contribution over established methods.
- Generalization and portability
- Scalability to much larger/smaller LRMs (e.g., O-series, DeepSeek R models >70B, mobile-scale models) and portability across architectures; test whether r_s or learned procedures transfer between model families.
- Cross-task transfer: can a trace learned for input moderation transfer to output moderation (response filtering) or to adjacent safety tasks (policy compliance, privacy, misinformation)?
- Interoperability with RLHF/preference training (DPO, GRPO): characterize interactions (synergy or interference) between reinforcement objectives and PSRT, including training schedules and stability.
- Deployment and operations
- Thresholding and confidence policies for indicator tokens in production, including fallback behavior (abstain/escalate) under uncertainty; provide guidance for tuning per-application risk tolerance.
- Cost analysis: quantify the training overhead (SFT + PSRT optimization) versus inference-time savings, and provide amortization curves under realistic traffic.
- Integration with streaming/batched APIs and output filtering pipelines; address practical concerns like batching with varying r_s lengths, logging/auditing requirements, and compliance workflows.
- Interpretability and governance
- Loss of explicit reasoning traces reduces transparency and auditability; investigate methods to recover faithful post-hoc explanations, confidence rationales, or verifiable decision artifacts that meet compliance needs.
- Human-in-the-loop review and governance: define protocols for auditing PSRT decisions, triaging borderline cases, and monitoring for drift or policy changes.
Practical Applications
Overview
The paper proposes PSRT, a practical method to accelerate Large Reasoning Model (LRM)–based guard models for harmful query detection by replacing explicit reasoning generation with prefilled “safe reasoning” virtual tokens (continuous embeddings). PSRT enables single-forward-pass classification via indicator tokens (e.g., <safe>, <unsafe>), delivering near-identical detection performance while eliminating reasoning-token generation during inference across diverse models and datasets.
Below are actionable applications derived from the paper’s findings, methods, and innovations.
Immediate Applications
These applications can be deployed now with current models and tooling; they focus on accelerating guardrails, reducing latency/cost, and improving throughput while maintaining accuracy.
- Drop-in single-pass safety gate for LLM APIs
- Sector: software/platforms, cloud AI services
- Tools/Products/Workflows: “PSRT Guard” module in serving stacks; pre-filtering unsafe prompts/outputs with indicator-token classification; optional cascade to full reasoning only for uncertain cases
- Assumptions/Dependencies: Availability of LRM-based guard models and a domain-appropriate safe reasoning dataset; model-specific tuning (safe-trace length l); indicator-token instrumentation; periodic retraining for drift
- Real-time content moderation for chat/social platforms
- Sector: content moderation, trust & safety
- Tools/Products/Workflows: PSRT-powered moderation services for live chat, comments, and community platforms; faster triage and enforcement; batch and streaming pipelines
- Assumptions/Dependencies: Coverage of harmful categories and multilingual data; monitoring for evolving adversarial jailbreaks; integration with existing policy taxonomies
- On-device safety gating for assistants and edge deployments
- Sector: consumer devices, robotics, IoT
- Tools/Products/Workflows: Embedded PSRT classification to gate voice/text commands; low-latency rejection of unsafe instructions; hybrid mode that escalates to cloud for borderline cases
- Assumptions/Dependencies: Edge-compatible LRM variants (quantized/smaller models); energy and memory constraints; on-device inference optimizations
- Enterprise compliance firewall for internal LLM use
- Sector: finance, healthcare, legal, HR
- Tools/Products/Workflows: PSRT-based safety proxy (reverse proxy/gateway) for internal LLM traffic; DLP and policy checks; audit logs keyed to indicator tokens; risk dashboards (TPR/FPR)
- Assumptions/Dependencies: Domain-specific policy alignment and training data; regulatory mapping; documented escalation paths to human review
- Safer developer copilots and code assistants
- Sector: software engineering
- Tools/Products/Workflows: IDE plugins that gate harmful code suggestions (e.g., malware, exploits) using PSRT prefilters; block prompt-injection/jailbreak attempts
- Assumptions/Dependencies: Security-focused training data; integration with dev workflows; tuning thresholds to balance false positives/negatives
- Safety triage router in multi-agent systems
- Sector: AI orchestration, agent frameworks
- Tools/Products/Workflows: Single-pass PSRT classifier as a router that blocks unsafe tasks or routes uncertain cases to a “full-reasoning” agent or human
- Assumptions/Dependencies: Calibrated confidence thresholds; fallbacks for edge cases; logging and traceability
- Academic benchmarking and reproducible research on efficient safety reasoning
- Sector: academia
- Tools/Products/Workflows: Using the released code/dataset to study condensed reasoning embeddings, model differences (e.g., Qwen vs Llama), ELBO-based training, and Lipschitz error bounds
- Assumptions/Dependencies: Access to LRMs and compute; licensing/compliance for datasets; standardized evaluation protocols
- Customer support chat safety at scale
- Sector: customer service, BPO
- Tools/Products/Workflows: PSRT moderation for agent and user interactions; minimal latency added to large volumes; automated escalation and templated refusals
- Assumptions/Dependencies: Domain adaptation; maintaining service-level agreements; multilingual coverage
- Parental controls and daily content filters
- Sector: daily life, consumer apps
- Tools/Products/Workflows: Mobile/desktop filters for AI assistants and messaging that quickly flag unsafe content; configurable strictness levels
- Assumptions/Dependencies: Age-appropriate policy settings; minimizing false positives for benign sensitive topics; offline models for privacy
- Policy evaluation pilots and regulatory sandboxes
- Sector: public policy, regulation
- Tools/Products/Workflows: Pilot deployments demonstrating minimal-latency guardrails; indicator-token based auditability; standardized reporting of TPR/FPR across mixed datasets
- Assumptions/Dependencies: Regulator-approved metrics and test suites; transparency and documentation; governance for model updates
Long-Term Applications
These applications require additional research, scaling, adaptation, or standardization before widespread deployment.
- Extending “condensed reasoning” to other tasks (math, code debugging, safety-critical decision support)
- Sector: education, software, professional services
- Tools/Products/Workflows: “Reasoning Capsules” (task-specific virtual token embeddings) for fast inference in non-safety tasks
- Assumptions/Dependencies: Demonstrating parity or acceptable trade-offs vs full chain-of-thought; task-tailored datasets and evaluation
- Adaptive/domain-specific PSRT profiles and personalization
- Sector: enterprise, consumer
- Tools/Products/Workflows: Multiple safe-trace embeddings tied to policies (e.g., medical compliance, workplace harassment), dynamically selected per user or task
- Assumptions/Dependencies: MLOps for profile management; data governance; conflict resolution among policies
- Continual learning against evolving jailbreaks and prompt injection
- Sector: cybersecurity, trust & safety
- Tools/Products/Workflows: Automated pipelines to mine new attacks, update safe-traces, and re-tune indicator thresholds; integration with red-teaming and anomaly detection
- Assumptions/Dependencies: Robust data collection; safe retraining loops; monitoring for catastrophic forgetting
- Safety standards and certifications for guard models
- Sector: policy/regulation, industry consortia
- Tools/Products/Workflows: Standardized benchmarks and certification criteria (F1/TPR/FPR targets, latency budgets); compliance reports using indicator tokens and documented fallback behavior
- Assumptions/Dependencies: Multistakeholder agreement; cross-vendor interoperability; periodic recertification
- Hardware/software co-design for PSRT acceleration
- Sector: semiconductors, edge devices
- Tools/Products/Workflows: ASIC/SoC support for single-pass classification and safe-trace embeddings; optimized memory layouts and kernel fusion
- Assumptions/Dependencies: Hardware roadmap alignment; cost-benefit for device makers; standardized model interfaces
- Cross-lingual and multimodal PSRT (text+image+audio+code)
- Sector: media, robotics, healthcare
- Tools/Products/Workflows: Unified safety gating across modalities (e.g., unsafe image prompts, audio commands); multimodal indicator tokens
- Assumptions/Dependencies: Availability of multimodal LRMs; multimodal safety datasets; robust multilingual coverage
- Commercial productization: PSRT Safety Gateway and SDKs
- Sector: software tooling
- Tools/Products/Workflows: Managed PSRT services; SDKs for embedding integration; observability dashboards (TPR/FPR, drift, latency); “Safety Router” for cascaded workflows
- Assumptions/Dependencies: Customer adoption; SLAs; integration with existing moderation and logging stacks
- Nuanced policy actions via richer indicator-token taxonomies
- Sector: policy, enterprise governance
- Tools/Products/Workflows: Expanded indicator set (<safe>, <needs_review>, <prohibited>, <sensitive_but_permissible>) enabling differentiated responses (refuse/transform/escalate)
- Assumptions/Dependencies: Training with multi-label indicators; policy versioning; human-in-the-loop for gray areas
- Privacy-preserving PSRT via federated training
- Sector: healthcare, finance, public sector
- Tools/Products/Workflows: Federated learning of safe-traces using local sensitive data; differential privacy to protect user content
- Assumptions/Dependencies: Federated infrastructure; privacy compliance; robust aggregation across heterogeneous clients
- Deeper theoretical and cognitive investigations
- Sector: academia
- Tools/Products/Workflows: Formal analysis of ELBO-based training for safe-traces; Lipschitz bounds in classification error; studies of model-specific behavior (e.g., Qwen vs Llama attention patterns)
- Assumptions/Dependencies: Research funding; access to diverse architectures; standardized protocols and datasets
Global Assumptions and Dependencies (cross-cutting)
- High-quality, domain-specific safe reasoning datasets are crucial; performance degrades with distribution mismatch or narrow coverage.
- Model-specific sensitivity exists (e.g., differing trends across Qwen and Llama); per-model hyperparameters (safe-trace length l) and thresholds must be tuned.
- PSRT relies on LRMs fine-tuned for indicator-token outputs; SFT and averaged initialization are empirically necessary for good performance.
- Continuous monitoring is required to counter evolving adversarial techniques; periodic retraining and evaluation across harmful, harmless, and mixed datasets is recommended.
- Multilingual and multimodal deployments require dedicated data and validation; privacy and regulatory compliance must guide data pipelines and auditability.
Glossary
- Ablation study: A controlled analysis where components of a method are removed or altered to measure their impact. "In this section, we perform ablation studies on two components of PSRT"
- AutoDAN: A genetic algorithm-driven jailbreak attack method that crafts prompts to bypass model safeguards. "genetic algorithm-driven methods such as AutoDAN"
- Chain-of-thought (CoT): An approach that elicits or uses intermediate reasoning steps to improve or evaluate model decisions. "we adopt a two-step chain-of-thought (CoT) annotation procedure"
- CodeAttack: A jailbreak method exploiting code understanding to induce unsafe outputs. "Examples include CodeAttack"
- DeepInception: A jailbreak technique using scene reasoning or text manipulation to mislead models into harmful behaviors. "DeepInception"
- Direct Preference Optimization (DPO): A reinforcement learning-style training objective that optimizes model outputs according to pairwise preferences. "trained with SFT and Direct Preference Optimization (DPO)"
- DRA: A jailbreak attack method designed to manipulate model safety behavior. "DRA"
- Embedding space: The continuous vector space in which token or prompt representations live. "optimize them in the continuous embedding space"
- Evidence lower bound (ELBO): A variational objective that lower-bounds the log-likelihood, often used to approximate intractable posteriors. "this objective maximizes an Evidence lower bound (ELBO) on the marginal log-likelihood"
- F1 score: The harmonic mean of precision and recall, used as an overall performance metric. "we use the F1 score as an overall indicator of detection performance"
- False Positive Rate (FPR): The proportion of harmless inputs incorrectly flagged as harmful. "we use the False Positive Rate (FPR) to quantify the misclassification rate of harmless queries"
- FlipAttack: A jailbreak method that flips or perturbs inputs to elicit unsafe outputs. "FlipAttack"
- Forward pass: A single evaluation of the model to produce outputs without generating multi-step reasoning tokens. "enables harmful-query detection in a single forward pass"
- GCG: A gradient-based jailbreak attack method that optimizes prompts to trigger unsafe responses. "gradient-based optimization of methods such as GCG"
- Group Relative Policy Optimization (GRPO): A reinforcement learning algorithm that optimizes policies using relative group-based feedback. "modified Group Relative Policy Optimization (GRPO)"
- Guard model: A classifier or filter that detects or blocks harmful queries for LLMs. "several guard models ... have been proposed to filter harmful queries"
- GuardReasoner: A family of LRM-based guard models trained with SFT and DPO to detect harmful queries. "GuardReasoner~\citep{liu2025guardreasoner} uses SFT together with a hard-sample DPO algorithm"
- Indicator tokens: Special output tokens that explicitly denote the classification result (e.g., <safe>, <unsafe>). "each answer begins with an indicator token, either <safe> or <unsafe>"
- Inference latency: The time delay incurred while evaluating a model, especially due to generating reasoning tokens. "substantially reduces inference latency"
- Jailbreak: An attack strategy that manipulates an LLM into producing harmful or restricted content. "LLMs are known to be vulnerable to jailbreak attacks."
- Jailbreak prompt: A carefully crafted input designed to bypass safety filters and elicit unsafe outputs. "carefully crafted jailbreak prompts"
- Large Reasoning Models (LRMs): Models specialized for extended, high-quality multi-step reasoning across domains. "Large Reasoning Models (LRMs) have demonstrated remarkable performance"
- L-Lipschitz continuity: A property bounding how much a model’s output can change relative to changes in its input, with constant L. "Under the assumption that the LRM-based Guard Model satisfies the L-Lipschitz continuity"
- Marginal log-likelihood: The log-probability of observed data marginalized over latent variables, often optimized via ELBO. "an Evidence lower bound (ELBO) on the marginal log-likelihood"
- PAD token: A special token used to pad sequences to a fixed length during training or preprocessing. "e(\text{PAD})"
- Perform Binary Classification (PBC): A step where classification is done directly via indicator token probabilities without generating reasoning tokens. "Here, PBC denotes perform binary classification"
- p-tuning: A method that learns soft prompts (continuous embeddings) to guide model behavior, often via prefix tuning. "inspired by p-tuning ... a method that enhances model capabilities by learning soft prompts"
- Prefilled Safe Reasoning Trace (PSRT): A technique that replaces explicit reasoning generation with learned, prefilled embeddings to accelerate inference. "replace the model's reasoning process with a Prefilled Safe Reasoning Trace"
- Reasoning posterior: The distribution over possible reasoning traces given a query, used conceptually when forming point estimates. "using safe reasoning trace as a point estimate for the reasoning posterior"
- Reasoning trace: The sequence of intermediate tokens or steps that a model generates to arrive at an answer. "long reasoning traces during inference"
- ReNeLLM: A jailbreak method exploiting model capabilities to induce unsafe behavior. "ReNeLLM"
- Safe reasoning trace: A learned embedding sequence representing the condensed reasoning that leads to safe classification. "safe reasoning trace "
- SFT (Supervised fine-tuning): Training a model on labeled data to align outputs with desired behavior. "We then use this dataset for supervised fine-tuning (SFT) of LRMs."
- Soft prompts: Continuous, learnable embeddings used in place of discrete tokens to steer model outputs. "learning soft prompts"
- Token-level reasoning: Generating explicit reasoning token-by-token during inference. "explicit token-level reasoning"
- True Positive Rate (TPR): The proportion of harmful inputs correctly identified as harmful. "we report the True Positive Rate (TPR) to measure the detection rate of harmful queries"
- Virtual tokens: Learnable, non-discrete embeddings that act like tokens to condition model behavior without being generated. "PSRT introduces a set of 'safe reasoning virtual tokens'"
Collections
Sign up for free to add this paper to one or more collections.