- The paper presents DeepPrune, a novel framework that reduces over 80% token usage in parallel LLM reasoning by eliminating redundant traces.
- It employs a judge model and dynamic clustering to predict equivalence with an AUROC of 0.87, optimizing computational costs.
- Experimental results show that DeepPrune maintains competitive accuracy within 3 percentage points across multiple reasoning benchmarks.
DeepPrune: Parallel Scaling without Inter-trace Redundancy
Introduction
"DeepPrune: Parallel Scaling without Inter-trace Redundancy" addresses a key inefficiency in LLMs when employing parallel scaling for reasoning tasks. By generating multiple Chain-of-Thought (CoT) reasoning traces simultaneously, parallel scaling can significantly enhance reasoning capacities in LLMs. However, this strategy often results in substantial computational redundancy, as over 80\% of reasoning traces yield identical final answers. The proposed DeepPrune framework leverages a judge model and a dynamic pruning algorithm to eliminate redundant traces while preserving answer diversity, achieving striking reductions in token usage and computational cost.
Problem Definition and Inter-trace Redundancy
The paper begins by elucidating the problem of inter-trace redundancy in parallel reasoning. Despite multiple traces being generated to improve reasoning outcomes, a majority of these traces converge to identical answers, leading to wasted computation (Figure 1). The challenge lies in predicting the equivalence of final answers from partial reasoning traces. Initial experiments using shallow semantic similarity (SentenceBERT) and LLM-based deep comparison (Qwen3-4B-Instruct) show limited success, prompting the need for a more sophisticated approach.
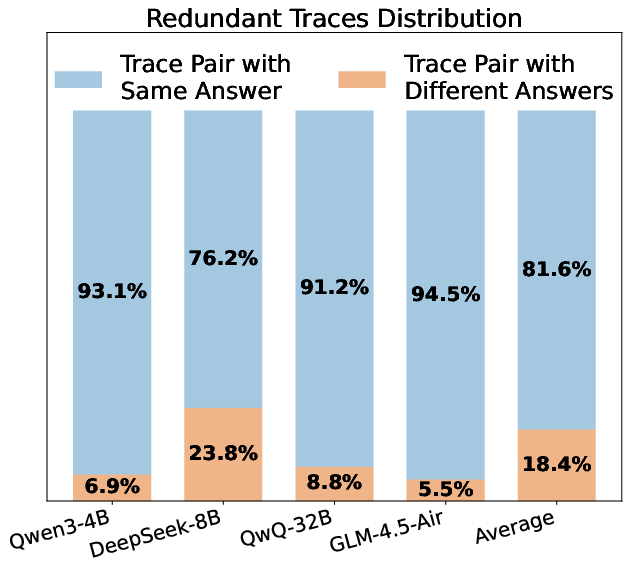
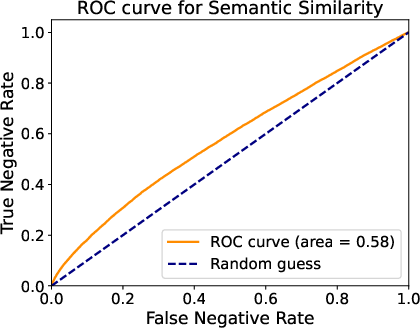
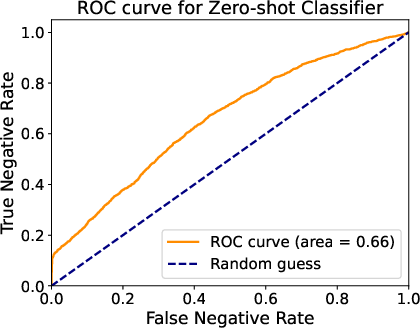
Figure 1: Analysis of Inter-trace Redundancy, highlighting severe redundancy and limited predictive power of shallow similarity measures.
The DeepPrune Framework
DeepPrune operates in two phases: offline training of a judge model and online pruning during inference. The judge model is trained to predict whether two partial traces will yield equivalent answers. This involves constructing datasets of reasoning trace pairs with binary labels indicating answer equivalence. Two truncation strategies are explored for effective prediction: fixed-length prefixes and reasoning-step aligned segments. The model uses focal loss and oversampling to handle class imbalance, achieving an AUROC of 0.87 for equivalence prediction.
The online pruning phase utilizes a greedy clustering algorithm to dynamically group traces predicted to have equivalent answers, thereby reducing redundancy while preserving answer diversity. This clustering approach minimizes the number of comparisons needed and facilitates efficient majority voting to determine the final answer (Figure 2).
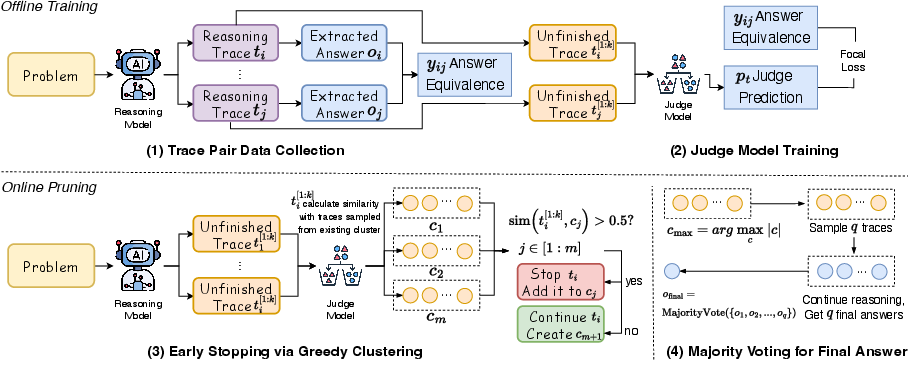
Figure 2: Overview of the DeepPrune framework, illustrating the offline training and online pruning phases.
Experimental Results
Comprehensive experiments demonstrate DeepPrune's effectiveness. The judge model's performance is validated across different reasoning models, achieving substantial improvements over baseline methods. In particular, the method achieves over 80\% token reduction while maintaining competitive accuracy within 3 percentage points across three challenging benchmarks (AIME 2024, AIME 2025, GPQA). This is evidenced by the observation that DeepPrune maintains accuracy even with a dramatic drop in computational cost.
Table results indicate that DeepPrune not only improves computational efficiency but also shows strong potential for cross-model generalization, as it performs consistently across different model architectures (Table provided in the paper).
Ablation Study
The paper includes an ablation study analyzing different truncation strategies for early stopping. The results highlight the effectiveness of using reasoning words compared to simple token truncation, with optimal performance seen for truncating the first 25 reasoning words (Figure 3). This reinforces the importance of selecting semantically rich features for predicting reasoning trace equivalence.
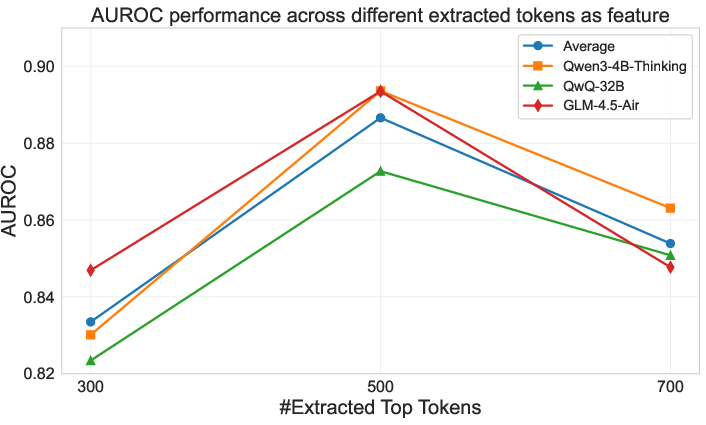
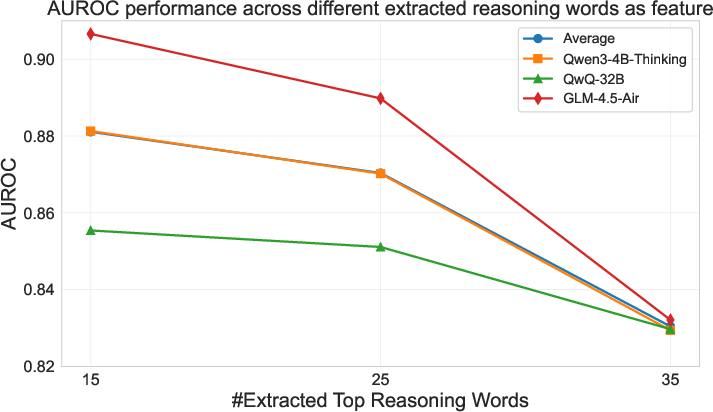
Figure 3: Ablation study on the judge model with different truncation strategies.
Conclusion and Future Work
DeepPrune sets a new standard for efficient parallel reasoning by addressing the pervasive issue of inter-trace redundancy. By intelligently pruning redundant paths, it significantly reduces computational overhead while maintaining answer accuracy. Future developments may explore adaptive threshold selection for redundancy prediction, further enhancing the framework's applicability to diverse reasoning models.
This work provides a robust solution for enhancing the efficiency of parallel reasoning in LLMs, promising improvements in both computational resource usage and performance on reasoning tasks. The findings extend knowledge on optimizing LLMs, with implications for broader AI applications involving complex reasoning scenarios.

