- The paper presents HRPO, a novel hybrid reasoning framework that integrates discrete token embeddings with continuous hidden states using reinforcement learning.
- It employs a gating mechanism to blend latent features with token representations, enhancing training dynamics on knowledge and STEM benchmarks.
- Experimental results demonstrate that HRPO achieves competitive exact match scores with compact models, indicating efficient and robust learning.
Hybrid Latent Reasoning via Reinforcement Learning
The paper introduces hybrid reasoning policy optimization (HRPO), a novel framework for training LLMs to perform hybrid latent reasoning by integrating discrete tokens with continuous hidden representations using reinforcement learning (RL). HRPO leverages a gating mechanism to combine token embeddings and hidden states and employs an RL-based optimization to train the model without relying on chain-of-thought (CoT) trajectories. The approach aims to capitalize on the inherent reasoning capabilities of LLMs while maintaining their generative abilities.
Hybrid Reasoning with a Gating Mechanism
The core of HRPO lies in its hybrid reasoning approach, which blends discrete token embeddings with continuous hidden state representations. The method addresses the challenge of directly feeding hidden states into the model by projecting them back into the embedding space using a weighted interpolation technique. This ensures that the inputs conform to the model's learned distribution, thereby improving training dynamics. A gating mechanism, inspired by gated recurrent models, is introduced to gradually incorporate hidden state representations into the sampled token embeddings. This mechanism prioritizes token embeddings initially and progressively integrates richer features from previous hidden states, leading to improved internal reasoning. The hybrid reasoning process only applies during the reasoning phase, while the final answer is generated via standard autoregressive decoding.
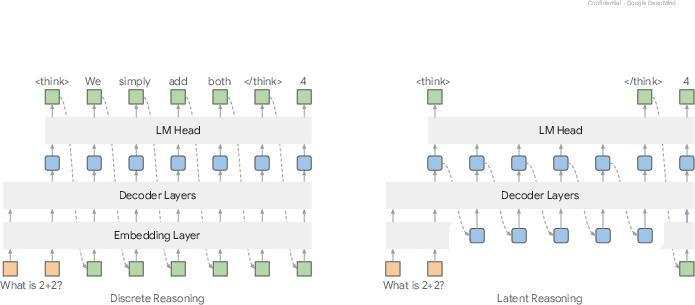
Figure 1: Comparison between discrete reasoning (left) and latent reasoning (right). Unlike the autoregressive sampling process in discrete reasoning, latent reasoning incorporates hidden representations from previous steps to enhance reasoning performance (between > and ).
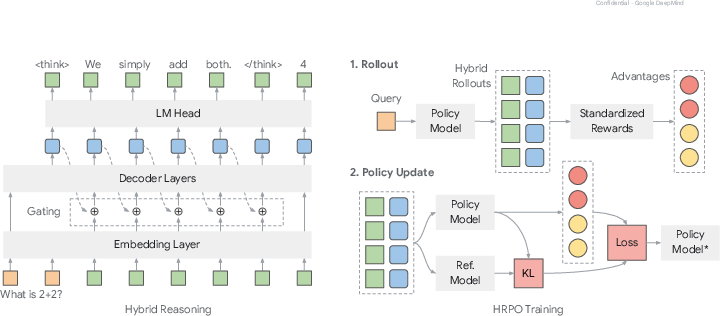
Figure 2: Hybrid reasoning with gating (left) and hybrid reasoning policy optimization (right). During rollouts, the reasoning trajectory is generated hybridly with both discrete tokens and latent features, and for policy update, we compute the HRPO loss using the hybrid rollout buffer to update the model.
Reinforcement Learning Optimization
HRPO optimizes the policy model via hybrid rollouts using RL, harnessing LLMs' native reasoning capabilities. The framework optimizes the policy to maximize the expected reward for input queries by standardizing the rewards within a group of generated hybrid rollouts. The policy gradients are estimated using a REINFORCE-style formulation, fusing discrete token inputs with continuous hidden representations across the reasoning span via the introduced gating mechanism. The hybrid trajectories that yield higher returns are assigned larger advantage estimates, encouraging policy updates to increase the log probabilities of their subsequent reasoning tokens.
Experimental Evaluation
The paper evaluates HRPO on both knowledge- and reasoning-intensive tasks. The knowledge-intensive tasks include open-domain multi-hop question answering, while the reasoning-intensive tasks involve STEM benchmarks. The experiments demonstrate that HRPO outperforms existing models and latent reasoning baselines across diverse scenarios. HRPO achieves strong exact match (EM) scores on knowledge benchmarks, rivaling much larger 7B baselines with smaller Qwen models. On STEM benchmarks, HRPO delivers strong results with compact Qwen backbones, matching the performance of much larger LLMs.
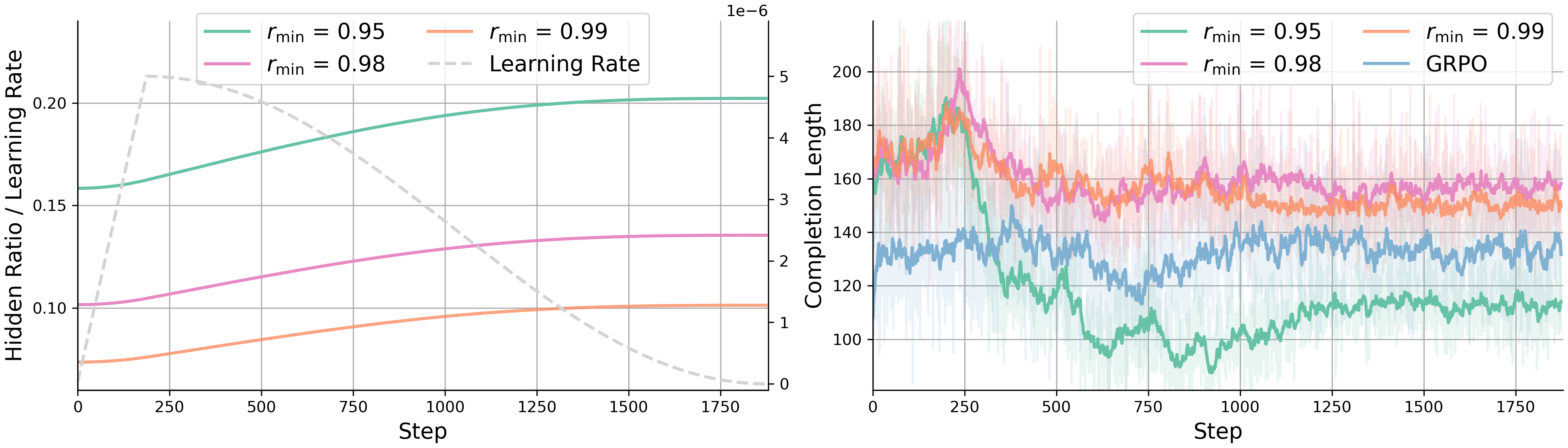
Figure 3: Hidden ratio with varying rmin in exp(−c⋅softplus(Λ)) and learning rate. We visualize the hidden ratio and completion length for training runs with rmin from [0.95,0.98,0.99].
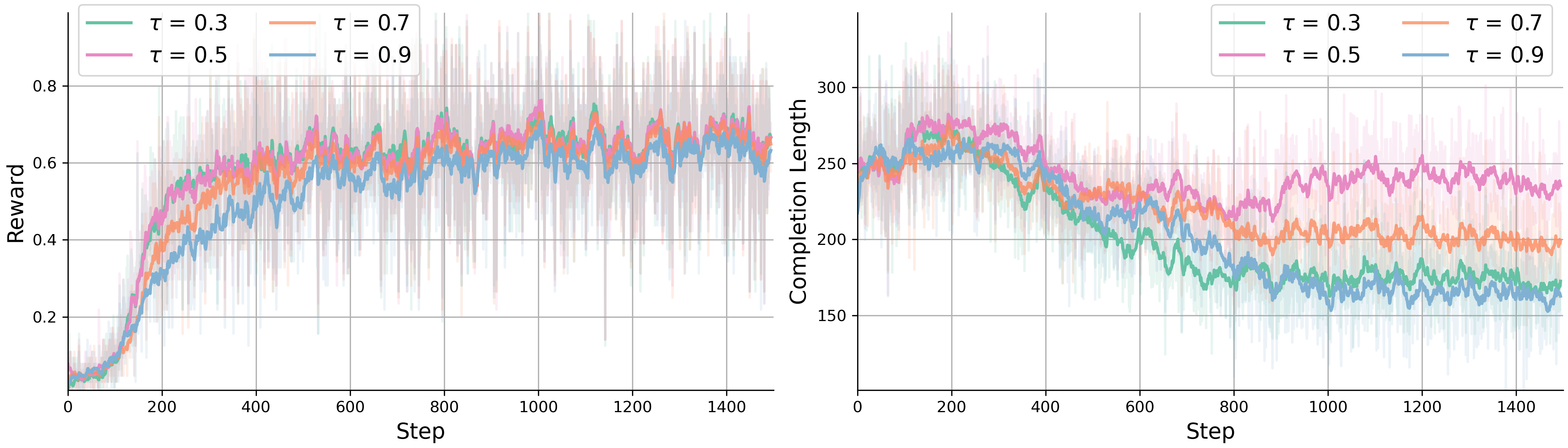
Figure 4: Sensitivity analysis for temperature tau in \Cref{eq:hidden_states}. We visualize the reward and completion length for training runs with different temperature selected from [0.3,0.5,0.7,0.9].
Analysis of Hybrid Latent Reasoning
The paper provides an analysis of HRPO, comparing different strategies for computing latent representations. The results show that HRPO achieves superior training dynamics with faster convergence while maintaining stability comparable to GRPO. The paper also tracks how the balance between discrete tokens and continuous latent representations shifts as LLMs learn to reason hybridly. The results indicate that the hidden ratio increases steadily, even as the learning rate tapers off. Furthermore, the paper examines how the initialization of Λ, which controls the balance between latent features and token embeddings, affects HRPO performance.

Figure 5: Example cross-lingual reasoning (English-Chinese) and its translation for HRPO.
Conclusion
The paper presents HRPO, a novel RL framework that unifies discrete token sampling with continuous latent representations through a learnable gating mechanism. By gradually incorporating hidden features into sampled token embeddings, HRPO incentivizes LLMs to refine their reasoning strategies hybridly. The experimental results and analysis demonstrate that HRPO outperforms both SFT and RL baselines, achieving consistent gains across diverse scenarios and triggering intriguing reasoning patterns.

