RLP: Reinforcement as a Pretraining Objective
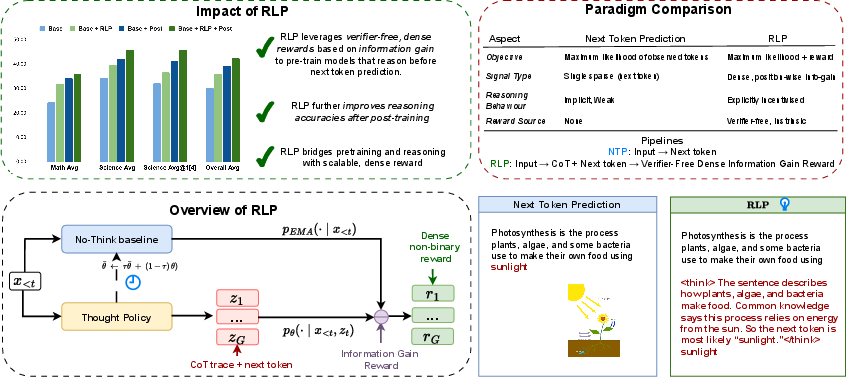
Abstract: The dominant paradigm for training large reasoning models starts with pre-training using next-token prediction loss on vast amounts of data. Reinforcement learning, while powerful in scaling reasoning, is introduced only as the very last phase of post-training, preceded by supervised fine-tuning. While dominant, is this an optimal way of training? In this paper, we present RLP, an information-driven reinforcement pretraining objective, that brings the core spirit of reinforcement learning -- exploration -- to the last phase of pretraining. The key idea is to treat chain-of-thought as an exploratory action, with rewards computed based on the information gain it provides for predicting future tokens. This training objective essentially encourages the model to think for itself before predicting what comes next, thus teaching an independent thinking behavior earlier in the pretraining. More concretely, the reward signal measures the increase in log-likelihood of the next token when conditioning on both context and a sampled reasoning chain, compared to conditioning on context alone. This approach yields a verifier-free dense reward signal, allowing for efficient training for the full document stream during pretraining. Specifically, RLP reframes reinforcement learning for reasoning as a pretraining objective on ordinary text, bridging the gap between next-token prediction and the emergence of useful chain-of-thought reasoning. Pretraining with RLP on Qwen3-1.7B-Base lifts the overall average across an eight-benchmark math-and-science suite by 19%. With identical post-training, the gains compound, with the largest improvements on reasoning-heavy tasks such as AIME25 and MMLU-Pro. Applying RLP to the hybrid Nemotron-Nano-12B-v2 increases the overall average from 42.81% to 61.32% and raises the average on scientific reasoning by 23%, demonstrating scalability across architectures and model sizes.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

