- The paper introduces GFPO, a selective learning algorithm that mitigates response length inflation while maintaining high reasoning accuracy.
- It employs group sampling and token efficiency filtering to achieve up to 85% reduction in excess length across multiple benchmarks.
- Empirical results demonstrate that GFPO generalizes well, ensuring efficiency improvements and steady accuracy even on out-of-distribution tasks.
Group Filtered Policy Optimization for Concise Reasoning
Motivation and Problem Statement
Reinforcement learning from verifier rewards (RLVR) has enabled LLMs to achieve state-of-the-art performance on complex reasoning tasks by scaling test-time compute, often via methods such as Group Relative Policy Optimization (GRPO) and Proximal Policy Optimization (PPO). However, RLVR-trained models exhibit a pronounced tendency toward response length inflation: longer chains are produced to maximize accuracy, but many tokens are redundant, repetitive, or uninformative. Empirical analysis reveals that longer responses are frequently less accurate, and that length inflation is not always correlated with problem difficulty. Existing approaches, including token-level loss normalization (e.g., DAPO, Dr. GRPO), fail to adequately control verbosity, as they penalize long incorrect chains but inadvertently reward long correct ones.
GFPO: Algorithmic Framework
Group Filtered Policy Optimization (GFPO) is introduced as a principled extension of GRPO to explicitly counteract response length inflation. The core mechanism is to sample a larger group of candidate responses per question during training, then filter these responses according to a target metric—primarily response length or token efficiency (reward per token). Only the top-k responses, as ranked by the metric, are used for policy gradient updates; the rest are masked out by setting their advantages to zero. This selective learning acts as implicit reward shaping, steering the policy toward concise and efficient reasoning.


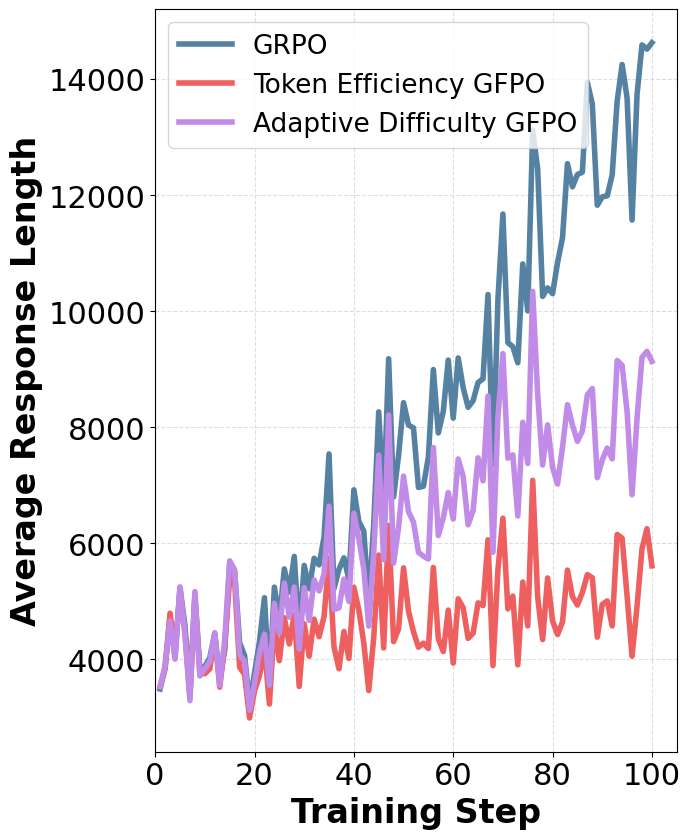
Figure 1: GFPO modifies GRPO by sampling more responses, ranking by a target attribute, and learning only from the top-k; this curbs length inflation while maintaining reasoning capabilities.
The GFPO objective is compatible with any GRPO variant and loss normalization scheme. The advantage normalization is performed only within the retained subset, ensuring that policy updates are focused on responses exhibiting the desired property. The method is general and can be extended to other metrics (e.g., factuality, diversity).
Experimental Setup
GFPO is evaluated using the Phi-4-reasoning model, with RL training restricted to 100 steps and a batch size of 64, matching the GRPO baseline. The reward function combines length-aware accuracy and n-gram repetition penalties. Group sizes G are varied ($8, 16, 24$), and the number of retained responses k is tuned to control the trade-off between brevity and accuracy. Evaluation is performed on AIME 25/24, GPQA, Omni-MATH, and LiveCodeBench, measuring pass@1 accuracy and excess length reduction (ELR).
Empirical Results
Length Reduction and Accuracy Preservation
GFPO variants consistently match GRPO's accuracy (no statistically significant differences under Wilcoxon signed-rank test) while delivering substantial reductions in response length inflation:
- Shortest k/G GFPO: Increasing G and decreasing k yields strong length reductions. For example, Shortest 4/24 GFPO achieves up to 59.8% excess length reduction on AIME 24.
- Token Efficiency GFPO: Optimizing for reward per token delivers the largest cuts—up to 84.6% excess length reduction on AIME 24—while maintaining accuracy, albeit with slightly increased training variance.
- Adaptive Difficulty GFPO: Dynamically adjusting k based on question difficulty further improves the efficiency-accuracy trade-off, outperforming static shortest-k variants at equivalent compute.
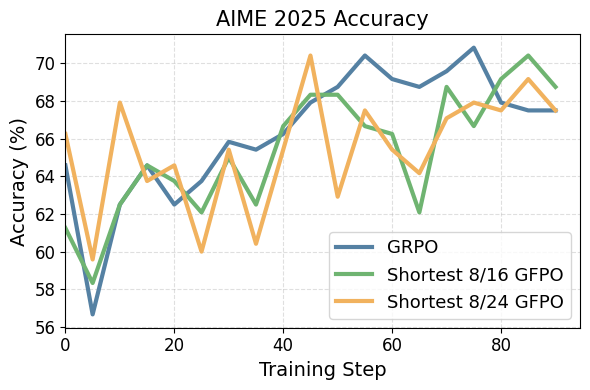
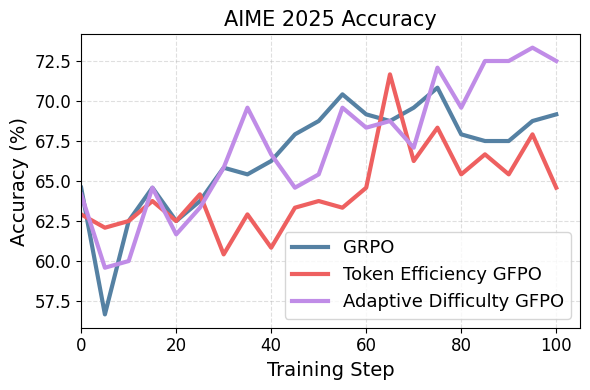
Figure 2: GFPO variants reach the same peak accuracy as GRPO during training on AIME 25.
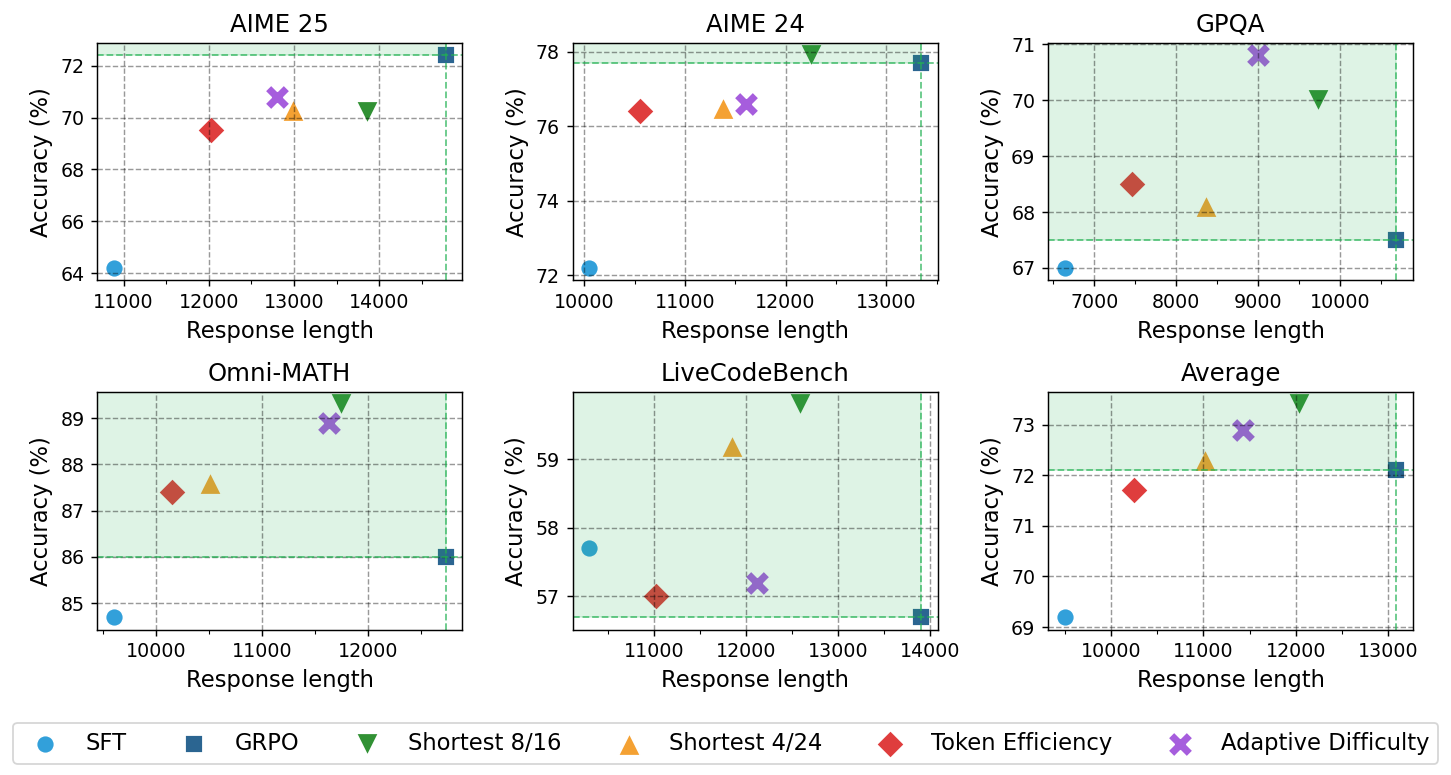
Figure 3: Pareto frontier analysis shows GFPO variants strictly dominate GRPO on most benchmarks, achieving both higher accuracy and shorter responses.
Analysis by Problem Difficulty
GFPO's length reductions are robust across all difficulty levels. Token Efficiency GFPO produces responses even shorter than the SFT baseline on easy questions, while Adaptive Difficulty GFPO achieves the strongest reductions on very hard problems by allocating more training signal to challenging prompts.
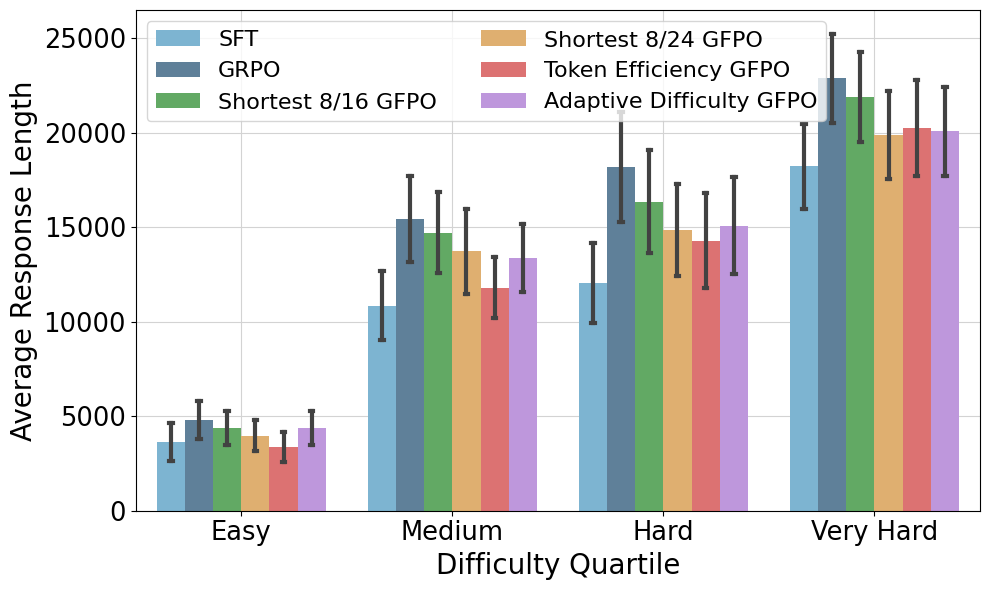
Figure 4: Average response length increases with problem difficulty, but GFPO reduces excess length across all levels.
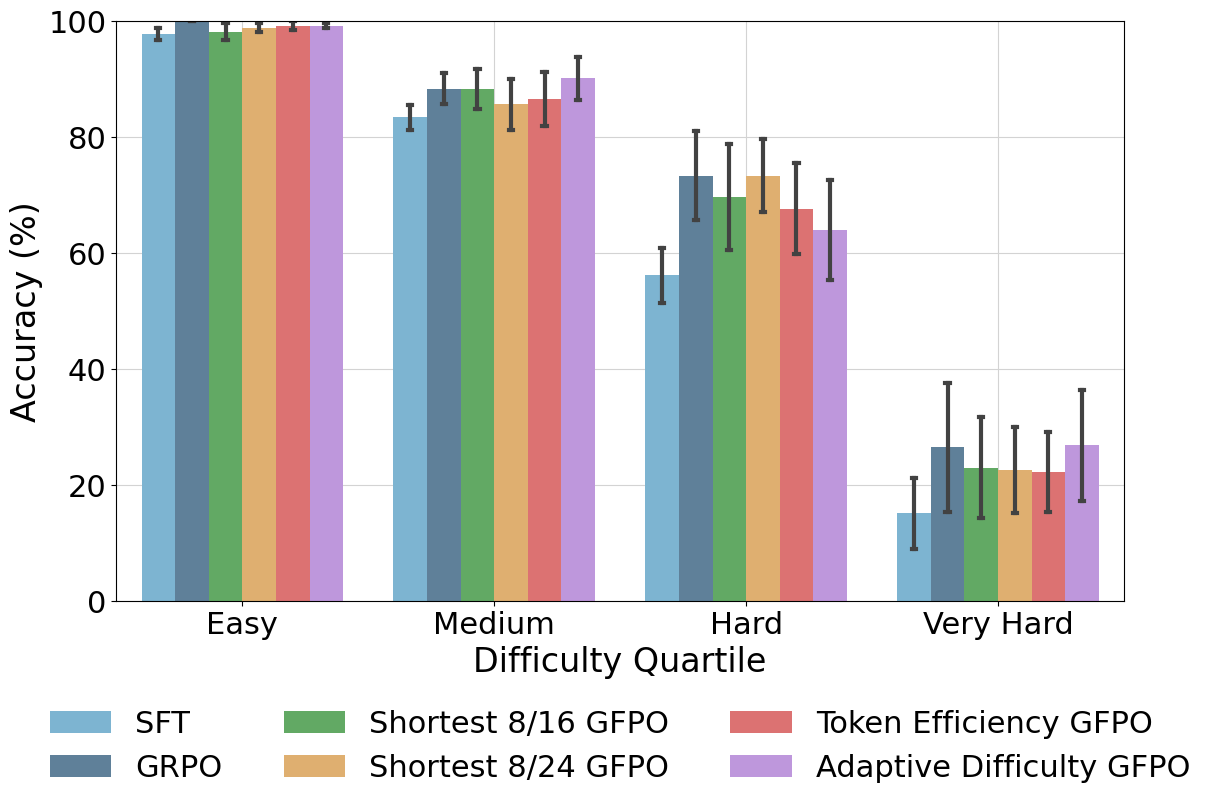
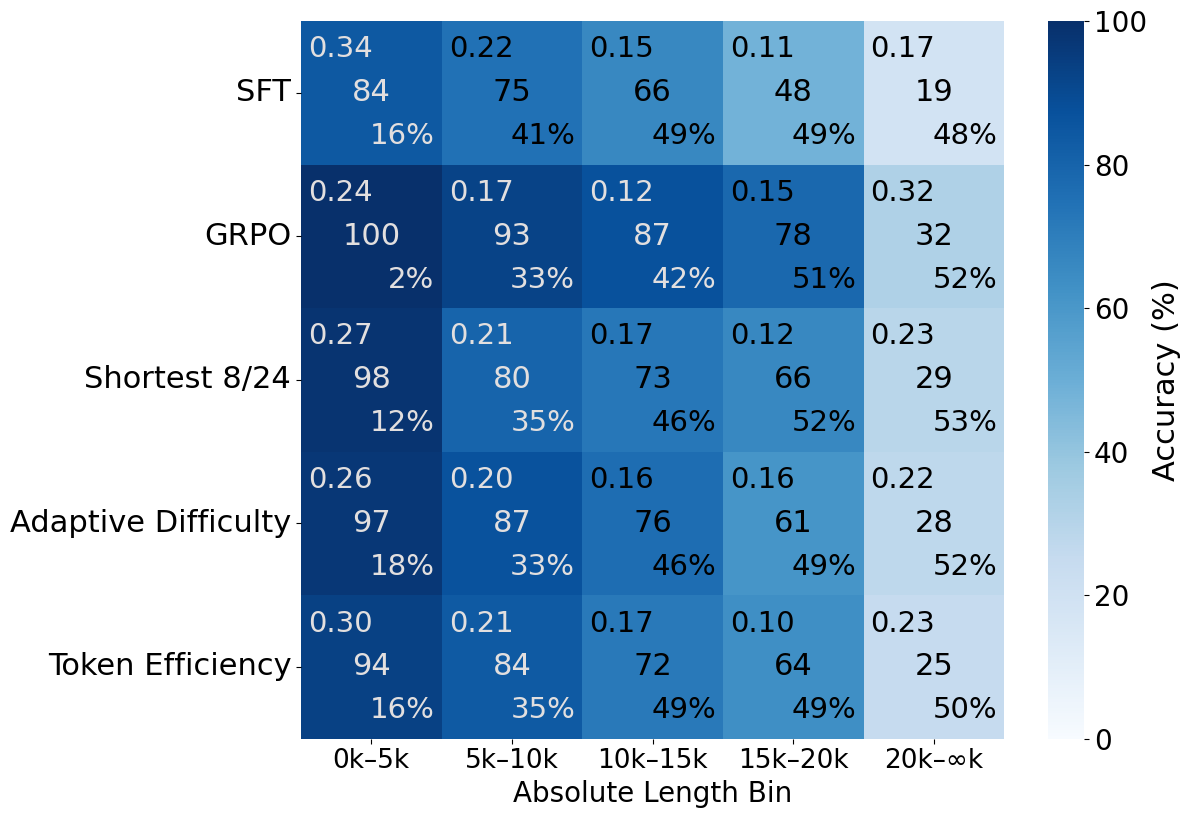
Figure 5: Adaptive Difficulty and Shortest 8/24 GFPO maintain or exceed GRPO accuracy across difficulty bins; Token Efficiency GFPO achieves the strongest length cuts with minor, non-significant accuracy drops.
Distributional Effects and Trace Analysis
GFPO compresses the long tail of response lengths, shifting the distribution toward shorter outputs. Token Efficiency and Shortest 8/24 GFPO achieve the largest shifts. Trace annotation reveals that GFPO trims verbosity primarily in the solution and verification phases, with Shortest 8/24 GFPO cutting 94.4% of excess solution length and 66.7% of excess verification length on AIME 25.
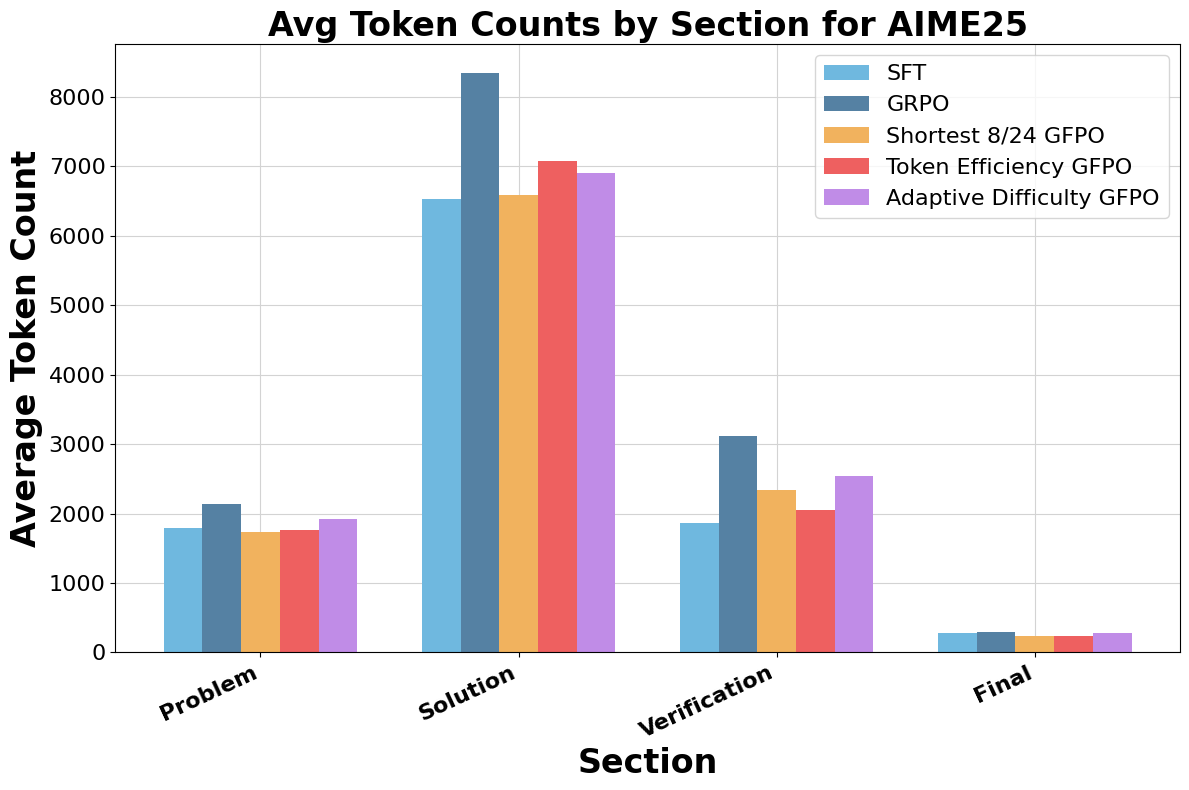
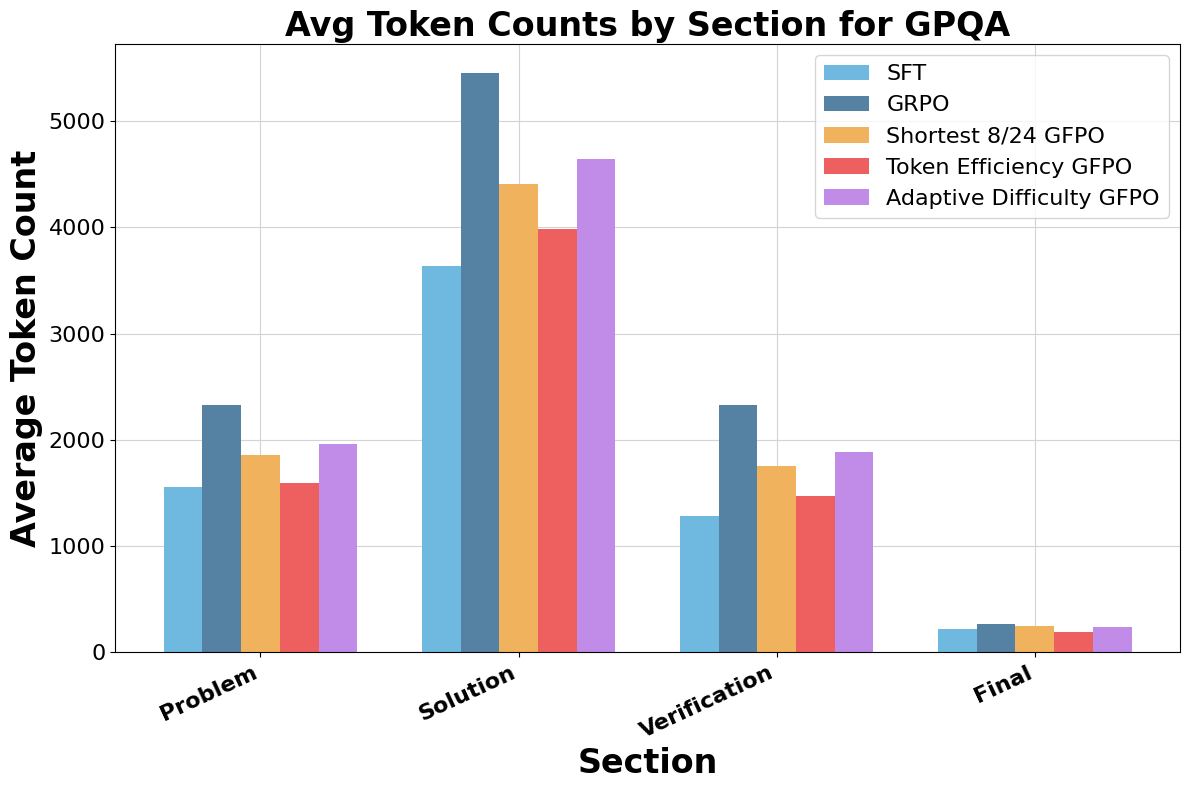
Figure 6: GFPO variants markedly reduce excess tokens in solution and verification phases compared to GRPO.
Out-of-Distribution Generalization
GFPO mitigates length inflation on out-of-distribution tasks (e.g., LiveCodeBench), where GRPO increases response length without accuracy gains. GFPO variants not only curb verbosity but also yield modest accuracy improvements, demonstrating robust generalization.
Implementation Considerations
GFPO incurs higher training-time compute due to increased sampling, but this is offset by persistent inference-time savings from shorter responses. The method is compatible with existing RLHF frameworks (e.g., verl, TRL) and can be integrated with alternative loss normalization or reward engineering strategies. The key hyperparameters are group size G, retained count k, and the choice of filtering metric. Adaptive Difficulty GFPO requires a streaming summary of prompt difficulties (e.g., t-digest) for dynamic curriculum allocation.
Theoretical and Practical Implications
GFPO demonstrates that increased training-time compute can be leveraged to achieve lasting improvements in inference-time efficiency. The selective learning paradigm enables simultaneous optimization of multiple response attributes without complex reward engineering. The approach is extensible to other domains and metrics, and can be combined with inference-time interventions for further control over reasoning length.
The strong empirical results—up to 85% reduction in length inflation with no significant loss in accuracy—challenge the prevailing assumption that longer reasoning chains are necessary for high performance. GFPO provides a scalable solution for deploying efficient LLMs in production settings where inference cost is a critical constraint.
Future Directions
Potential avenues for future research include:
- Integrating GFPO with more sophisticated reward functions or external quality metrics.
- Extending adaptive curriculum strategies to other response attributes (e.g., safety, factuality).
- Combining GFPO with inference-time length control or early stopping mechanisms.
- Scaling GFPO to larger models and more diverse reasoning tasks.
Conclusion
Group Filtered Policy Optimization (GFPO) is a principled extension of GRPO that enables concise reasoning in LLMs by sampling more responses during training and selectively learning from those best aligned with brevity or token efficiency. GFPO achieves substantial reductions in response length inflation while preserving or improving accuracy across a range of benchmarks and difficulty levels. The method is practical, extensible, and offers a robust framework for efficient reasoning in large-scale LLMs.