- The paper presents a novel convolutional VAE architecture that fuses language-audio distillation with a multi-component loss structure to achieve efficient semantic audio compression.
- It leverages innovative training techniques such as polyphonic augmentation, denoising, and CLAP-based contrastive learning to optimize semantic representation and audio quality.
- The model demonstrates enhanced zero-shot classification and captioning performance, signaling potential for multimodal AI applications.
SALAD-VAE: Semantic Audio Compression with Language-Audio Distillation
Introduction
The paper "SALAD-VAE: Semantic Audio Compression with Language-Audio Distillation" (2510.07592) advances audio processing through the innovative Variational Autoencoder (VAE) design optimized for semantic audio compression. The model, named SALAD-VAE, offers state-of-the-art compression capabilities, operating in the frequency domain with a remarkably low latent frame rate of 7.8 Hz. This approach prioritizes the balance between semantic richness and high-fidelity audio reconstruction. Unlike some prior architectures like StableAudio Open and Music2Latent, which wrestle with trade-offs between semantic interpretability and audio generation quality, SALAD-VAE streamlines these objectives through its sophisticated architecture and training methodologies.
VAE Architecture and Training Methodologies
SALAD-VAE employs a convolutional VAE operating in the frequency domain, utilizing both centered ResBlocks in its encoder and causal ResBlocks in its decoder (Figure 1). This structure provides a compact and continuous latent-space codec that captures and maintains semantic integrity while ensuring high-quality audio playback. The encoder-decoder pair is optimized using a multi-component loss framework that includes reconstruction loss, adversarial and feature matching losses, and a Kullback-Leibler Divergence (KLD).
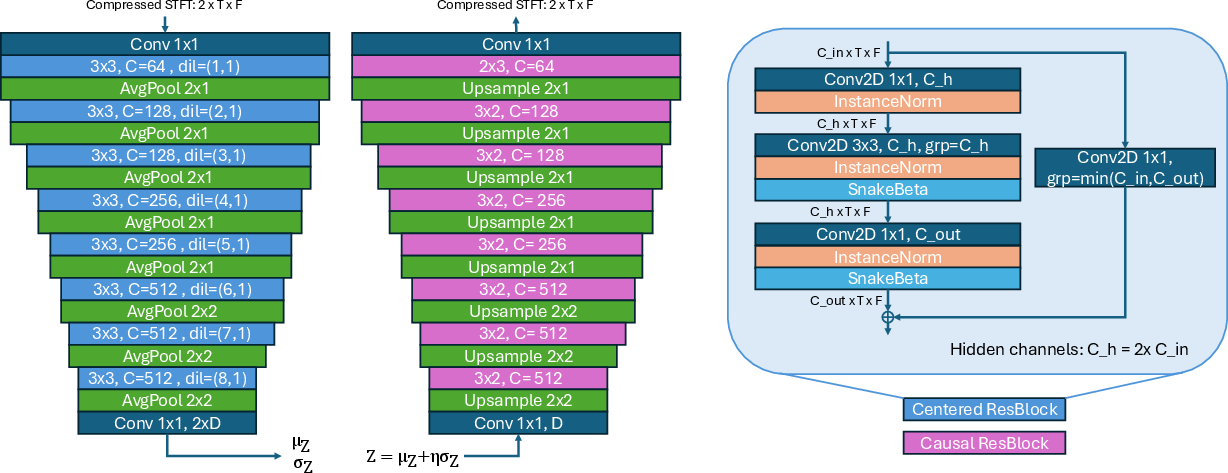
Figure 1: Left: proposed VAE architecture using centered ResBlocks in encoder and causal ResBlocks in decoder. Right: Inverted bottleneck ResBlock.
The training process incorporates innovative enhancements such as:
- Polyphonic Augmentation: This feature combines multiple audio sources in real-time, fostering robust model generalization across varied audio types.
- Denoising Autoencoder Approach: Inputs are deliberately degraded, pressuring the network to improve its generative capabilities by concealing these degradations in the output.
- Contrastive Learning and CLAP Loss: A contrastive semantic loss helps disentangle semantic content, while the CLAP-based distillation enhances latent representation by aligning it with pretrained text-audio embedding spaces.
In experimental evaluations, SALAD-VAE demonstrates a significant improvement over baseline models in both audio quality and semantic comprehension. A comprehensive set of evaluation metrics, including Word Error Rate (WER), Fréchet Audio Distance (FAD), and DistillMOS, gauge various aspects of audio quality and the effectiveness of the latent embeddings.
Key Numerical Results:
- Superior semantic and reconstruction performance across latent space probing tasks.
- Zero-shot classification and captioning functionalities, enabled by the integration of pre-trained CLAP embeddings.
The performance evaluations reveal SALAD-VAE's adeptness at maintaining audio fidelity while offering a semantically dense latent space. Particularly in zero-shot classification scenarios, the model delivers competitive generalization capabilities, a novel advancement compared to existing architectures.
Implications and Future Directions
SALAD-VAE's design facilitates seamless integration with LLMs and cross-modal systems due to its compact continuous latent space, bridging the divide between semantic representation quality and audio generation fidelity. This model's ability to incorporate text-audio alignment into a VAE architecture introduces new paradigms for audio processing, especially in multimodal AI systems and applications such as audio captioning and classification.
Future research could focus on extending SALAD-VAE to handle more complex audio scenarios, including multi-channel audio formats, and potentially scaling the architecture for even richer audio contexts. Expanding the model's ability to generalize to unforeseen classes without retraining could significantly broaden its application scope within AI systems integrating audio understanding and synthesis.
Conclusion
SALAD-VAE exemplifies a sophisticated approach to semantic audio compression by effectively marrying semantic depth with reconstruction fidelity. It distinguishes itself from prior models by achieving efficiency at lower complexities and advancing the methodological tapestry of audio variational autoencoders. As the demand for robust audio processing in AI systems grows, SALAD-VAE provides a promising framework for future exploration and innovation in semantic audio technologies.