- The paper presents RAVE, a VAE-based model employing a dual-phase training process—representation learning and adversarial fine-tuning—to produce high-quality audio.
- It achieves remarkable computational efficiency with synthesis speeds of 985kHz on CPU and 11.7MHz on GPU, outperforming models like NSynth and SING.
- The framework supports versatile applications such as timbre transfer and audio compression, balancing reconstruction fidelity with a compact latent representation.
RAVE: A Variational Autoencoder for Fast and High-Quality Neural Audio Synthesis
Introduction
The paper presents "RAVE," a novel neural audio synthesis framework leveraging Variational AutoEncoders (VAEs). The primary objective of RAVE is to achieve real-time audio synthesis with high fidelity and efficiency, addressing the challenges associated with raw waveform modeling. Traditional approaches often struggle with computational intensity, limited control ability, or low sampling rates, especially when striving for high-quality audio generation. This research introduces a two-stage training procedure that enables RAVE to overcome these barriers and produce high-quality 48kHz audio, running significantly faster than real-time on standard hardware.
Methodology
The core innovation in RAVE lies in its dual-phase training architecture. The first phase focuses on representation learning using VAEs, while the second phase involves adversarial fine-tuning to refine the audio quality. Initially, the model undergoes training as a regular VAE, where dimensionality reduction and compact representation are emphasized through a spectral distance-based loss.

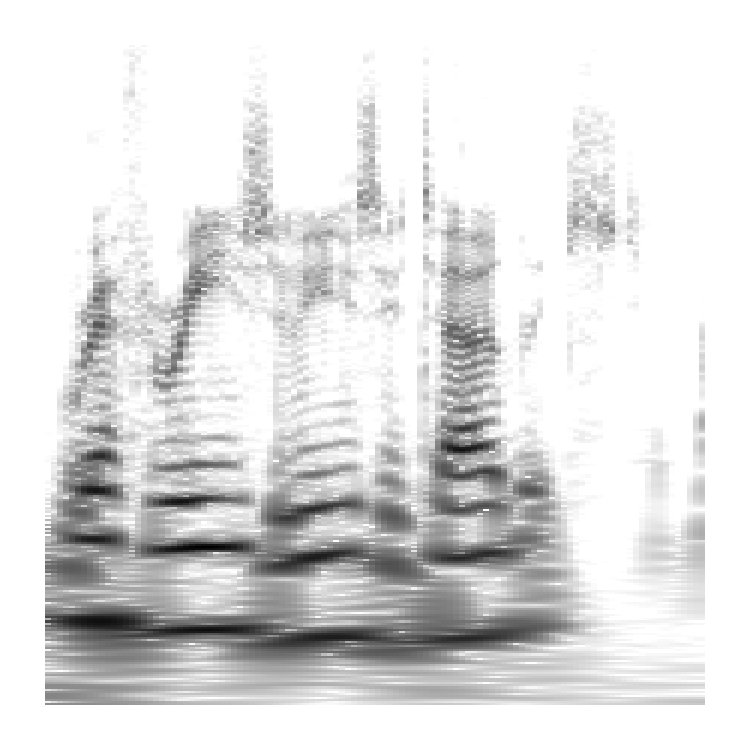


Figure 1: Reconstruction of an input sample with several fidelity parameters f.
Representation Learning
By employing a multiscale spectral distance that focuses on amplitude spectra, the model circumvents the need to accurately reconstruct phase information, leading to a more perceptually relevant representation. This spectral distance drives the first-stage VAE training, effectively guiding the encoder-decoder architecture to converge on capturing essential audio attributes while minimizing undesired noise.
Adversarial Fine-Tuning
For the final synthesis quality, RAVE integrates a Generative Adversarial Network (GAN) framework in its second training phase. This phase freezes the encoder and solely optimizes the decoder against a discriminator network to enhance the naturalness of generated audio. The adversarial objective is complemented by feature matching losses to stabilize and improve training outcomes, ensuring the synthesized samples are indistinguishable from real audio.
Results and Discussion
The experimental analysis validates RAVE's effectiveness, demonstrating its superiority over existing models such as NSynth and SING in terms of both quality and computational efficiency. On a qualitative scale, RAVE achieves a mean opinion score (MOS) of 3.01 compared to 2.68 for NSynth and 1.15 for SING. It also achieves this with significantly fewer parameters, indicating a more compact and efficient architecture.
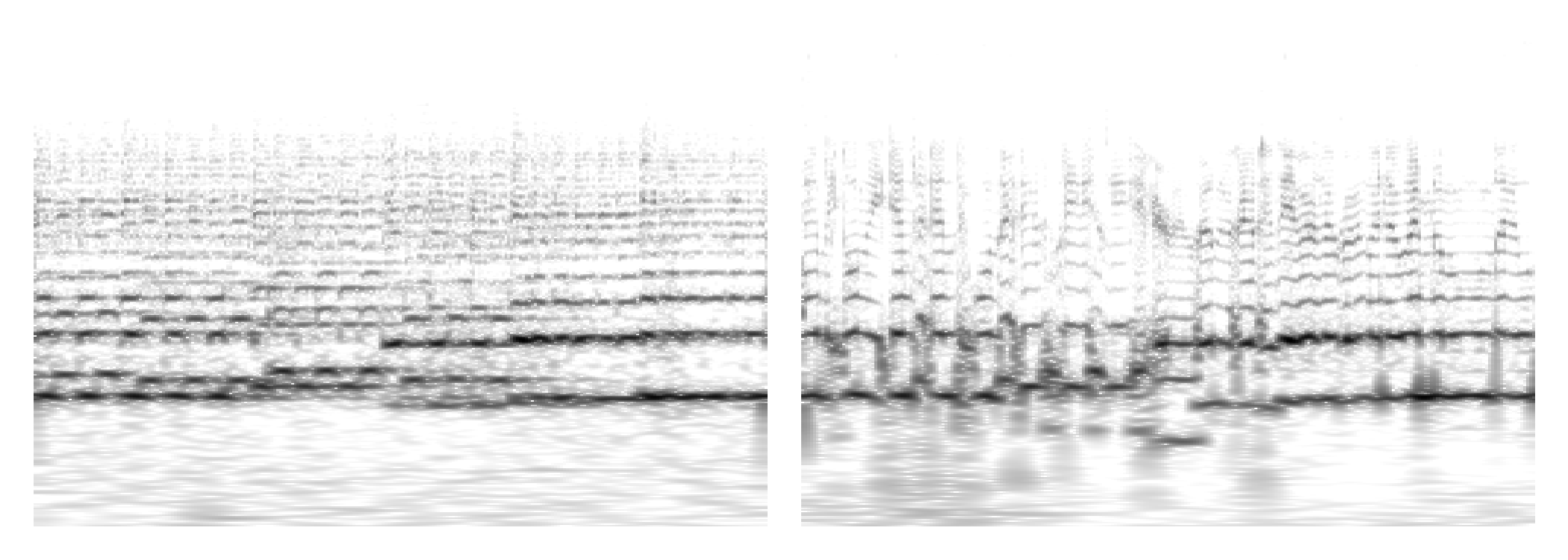

Figure 2: Example of timbre transfer using RAVE.
Synthesis Speed
The synthesis speed of RAVE is another crucial benefit. While autoregressive models like NSynth are hindered by computational bottlenecks, RAVE operates at 985kHz on a CPU and 11.7MHz on a GPU, showcasing its real-time applicability. This is largely attributable to the multiband decomposition, which efficiently handles high sampling rates without elevating the model complexity.
Post-Analysis and Applications
Post-training, the latent representation is scrutinized to balance reconstruction fidelity and representation compactness via Singular Value Decomposition (SVD). This approach allows RAVE to dynamically adjust latency dimensions based on a fidelity parameter without detriment to audio quality. Applications discussed include timbre transfer, where RAVE's model adaptation capabilities support cross-domain audio transformations efficiently, and signal compression, wherein the learned latent space facilitates high-ratio compression for downstream tasks.
Conclusion
RAVE represents a significant advancement in the field of neural audio synthesis, balancing quality and efficiency through advanced VAE-GAN architectures and strategic training. By releasing source code and pretrained models, the authors provide a foundation for further research and application in music technology and audio processing domains.
In essence, the proposed framework offers a compelling and practical solution for high-quality audio generation with potential applications in real-time systems, multimedia content creation, and beyond.