- The paper introduces a unified audio autoencoder that produces both continuous embeddings and discrete tokens using an innovative FSQ-dropout technique.
- It employs a transformer-based architecture with consistency training to achieve high-fidelity audio reconstruction and efficient decoding strategies.
- Experimental results reveal improved audio quality and faster inference compared to baselines, highlighting its potential for generative audio modeling and MIR applications.
CoDiCodec: Unifying Continuous and Discrete Compressed Representations of Audio
Introduction and Motivation
CoDiCodec introduces a unified audio autoencoder architecture capable of producing both compressed continuous embeddings and discrete tokens from a single model, addressing a longstanding dichotomy in audio representation learning. Existing approaches typically force a choice between continuous latent spaces—favored for compatibility with diffusion and GAN-based generative models—and discrete tokenization, which is essential for autoregressive language modeling and efficient downstream tasks. CoDiCodec leverages summary embeddings, consistency-based training, and Finite Scalar Quantization (FSQ) with a novel FSQ-dropout technique to bridge this gap, enabling high compression ratios and superior audio fidelity without the need for multi-stage or adversarial training procedures.
Model Architecture and Training Paradigm
The architecture comprises three main components: an encoder, an upsampler, and a consistency model decoder. The encoder operates on complex STFT spectrograms, applying amplitude transformation to mitigate frequency bin energy skew. It uses a convolutional patchifier followed by transformer blocks to produce K summary embeddings, which efficiently capture global audio features and reduce temporal redundancy.
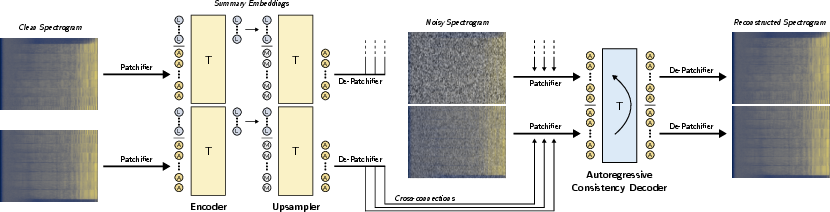
Figure 1: Training process. Transformer modules are represented with T, audio embeddings with A, learned/summary embeddings with L, and mask embeddings with M. Chunked causal masking enables autoregressive decoding.
The upsampler mirrors the encoder, reconstructing intermediate feature maps for cross-connections to the decoder. The consistency model decoder, trained via consistency training (CT), maps noisy spectrograms to clean ones, conditioned on upsampler features. Chunked causal masking in the transformer stack enables both autoregressive and parallel decoding strategies.
Consistency training is performed end-to-end with a single loss, avoiding the instability and complexity of adversarial or multi-stage objectives. The loss minimizes the distance between model outputs at adjacent noise levels, using a stop-gradient teacher-student framework. The architecture prioritizes transformer layers for scalability and efficient inference.
FSQ and FSQ-Dropout: Enabling Unified Latent Spaces
FSQ is employed for quantization, bounding latent values and rounding them to discrete levels, with gradients approximated via the straight-through estimator. Standard FSQ training leads to clustering of continuous pre-quantization values near quantization levels, limiting expressiveness. FSQ-dropout is introduced to address this: during training, with probability p, the rounding step is bypassed, allowing the model to process both continuous and discrete representations. This encourages a more uniform distribution of continuous latent values and trains the decoder to accept both input types.
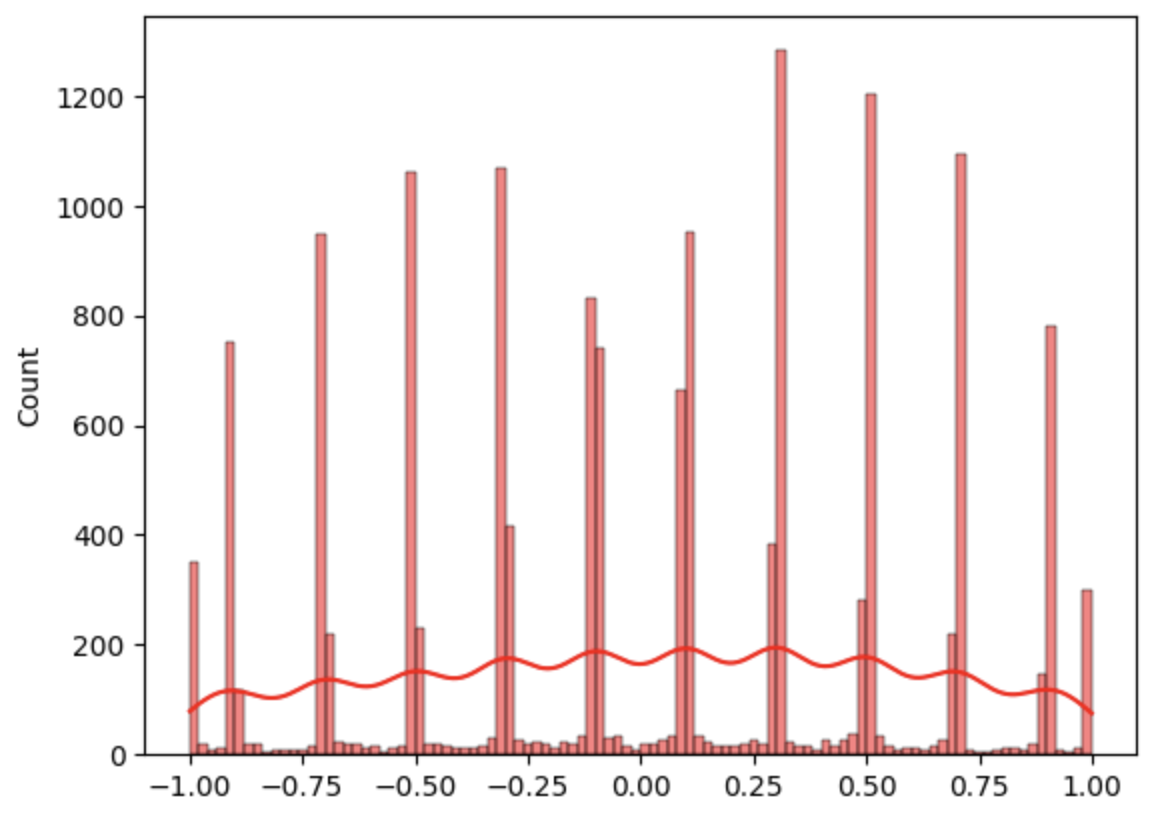
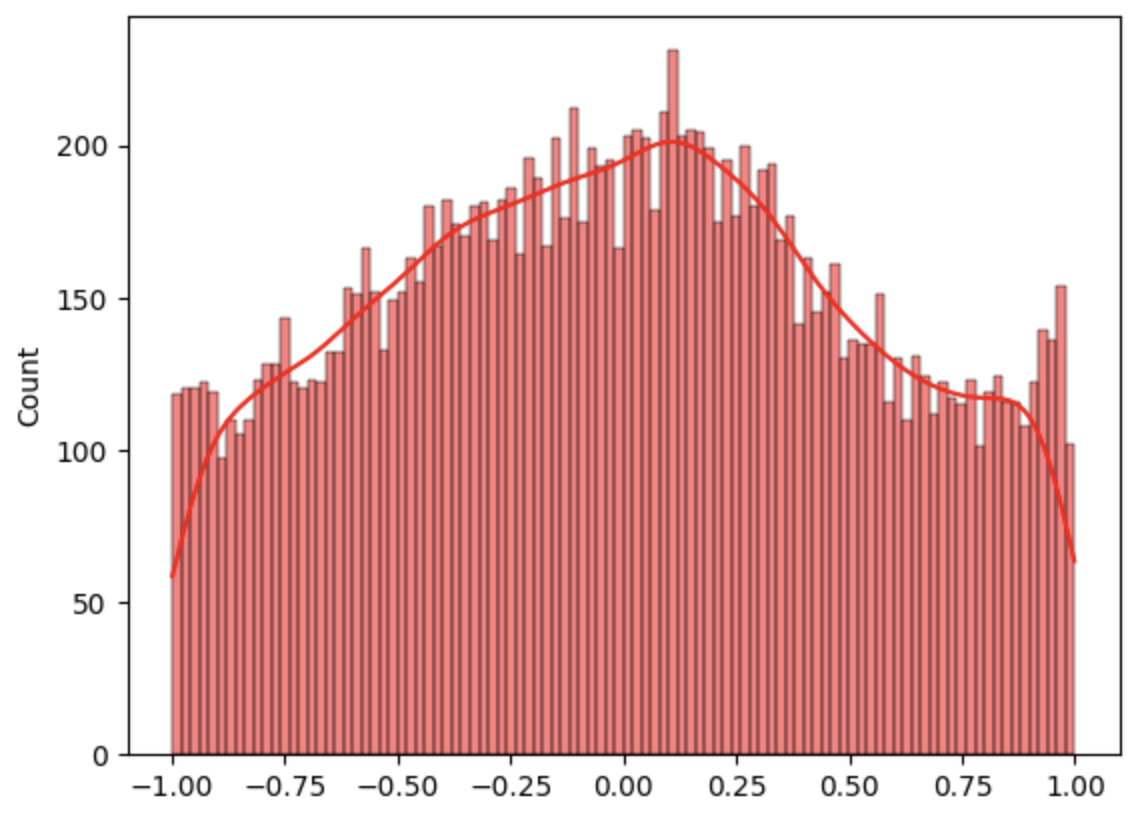
Figure 2: Distribution of continuous latent embeddings before rounding: (a) standard FSQ, (b) FSQ-dropout with p=0.75. FSQ-dropout utilizes the full [−1,1] range.
This mechanism enables high-fidelity continuous decoding and robust discrete tokenization, supporting diverse downstream generative modeling paradigms.
Decoding Strategies: Autoregressive and Parallel
CoDiCodec supports both autoregressive and a novel parallel decoding strategy. Autoregressive decoding is suitable for low-latency, interactive applications, generating audio chunk-by-chunk conditioned on previous outputs. Parallel decoding processes adjacent chunk pairs in parallel, shifting pairs at each denoising step to mitigate boundary artifacts. This approach allows efficient decoding of long sequences, with memory usage scaling linearly with sequence length.
Implementation Details
The model is implemented with a scaled-up transformer-centric architecture, using 12 transformer blocks per component and summary embeddings of dimensionality dlat=4. FSQ is configured with N=5 (11 quantization levels per dimension), yielding a 2.38 kbps rate for stereo 44.1 kHz audio. FSQ-dropout is set to p=0.75 based on ablation results. Training is performed on a single A100 GPU for approximately two weeks, with a batch size of 20 and 2 million iterations. The model contains ~150M parameters.
Experimental Results
CoDiCodec is trained on a diverse mixture of music, speech, and general audio datasets, with evaluation on MusicCaps. Baselines include Musika, LatMusic, Moûsai, Music2Latent, Music2Latent2, Stable Audio, and Descript Audio Codec (DAC), covering both continuous and discrete representation paradigms.
CoDiCodec achieves superior FAD and FADclap scores compared to all baselines at similar or lower bitrates, for both continuous and discrete representations. The parallel decoding strategy yields the best audio quality, outperforming autoregressive decoding. Notably, CoDiCodec's continuous embeddings are highly expressive and robust for downstream generative modeling, as demonstrated by training Rectified Flow DiT models on both standard and FSQ-dropout embeddings.
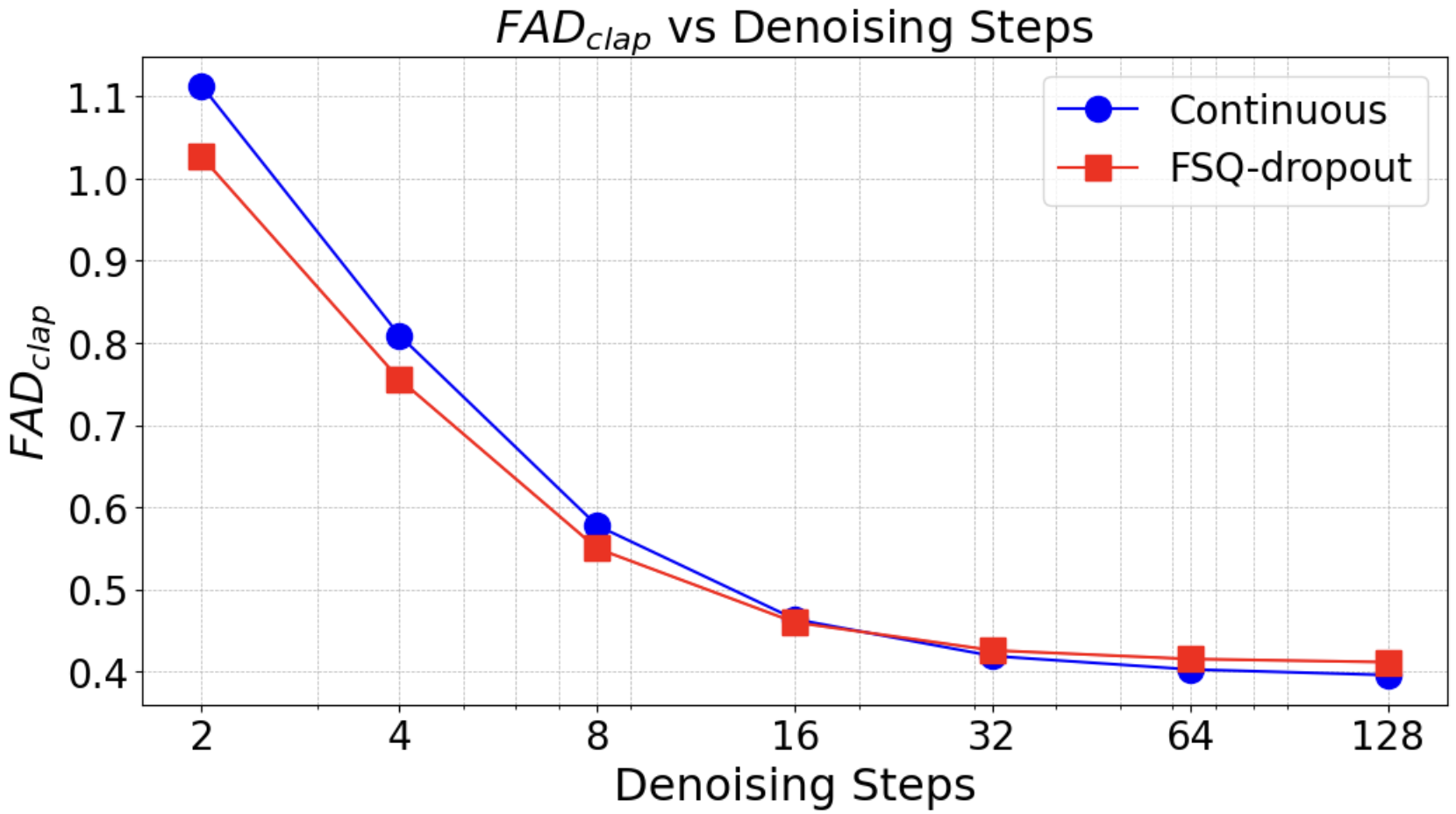
Figure 3: Downstream generative modeling FADclap with respect to number of denoising steps, showing improved robustness for FSQ-dropout embeddings.
Inference speed is also improved: CoDiCodec encodes and decodes faster than Music2Latent2, with parallel decoding providing further acceleration for long sequences.
Ablation and Design Validation
Ablation studies confirm the independent contributions of random mixing augmentation, architectural changes, and summary embedding dimensionality redistribution to improved FAD metrics. FSQ-dropout with p=0.75 recovers the performance of both standard FSQ and fully continuous variants, validating its role in unifying latent spaces.
Implications and Future Directions
CoDiCodec demonstrates that a single model can efficiently produce both continuous and discrete compressed audio representations, supporting a wide range of generative modeling frameworks. The use of summary embeddings and consistency-based training enables high compression ratios and scalable architectures. FSQ-dropout provides a practical solution for bridging the gap between continuous and discrete paradigms, with strong empirical results in both reconstruction and generative modeling tasks.
The architecture is well-suited for further scaling, domain adaptation, and integration into MIR pipelines. Future work should explore larger model variants, application to non-musical audio domains, and the utility of unified representations for MIR and multimodal generative tasks.
Conclusion
CoDiCodec presents a unified approach to audio compression, leveraging summary embeddings, consistency models, and FSQ-dropout to produce both continuous and discrete representations from a single autoencoder. The model achieves state-of-the-art audio quality metrics, supports efficient decoding strategies, and provides robust latent spaces for downstream generative modeling. This work establishes a foundation for scalable, flexible, and unified audio representation learning, with broad implications for generative audio modeling and MIR applications.