- The paper presents the ETD method, which recursively applies encoding, thinking, and decoding to boost reasoning in LLMs.
- It uses an adaptive depth strategy and selective layer analysis, achieving improvements of 28.4% on GSM8K and 36% on MATH tasks.
- The approach leverages pretrained OLMo-2 models to demonstrate scalable, efficient reasoning without increasing model parameters.
Encode, Think, Decode: Scaling Test-Time Reasoning with Recursive Latent Thoughts
Introduction
The paper "Encode, Think, Decode: Scaling test-time reasoning with recursive latent thoughts" addresses an alternative to increasing the reasoning capabilities of LLMs without expanding the parameter count, hyperparameters, or training data. It introduces the ETD approach that focuses on iterating over a subset of reasoning-centric layers during the mid-training stage to enhance latent reasoning processes, outstripping traditional architectural modifications aimed at boosting reasoning capabilities.
Architecture Design and Training
In the ETD framework, the architecture is delineated into three core components: Encode (latent encoder), Think (recursive block), and Decode (latent decoder). The selection of layers critical for encoding involves analyzing interpretation research, which reveals distinct roles allocated across model layers. Selection is informed by the angular change in the residual stream vector, emphasizing those pivotal in reasoning (Figure 1).
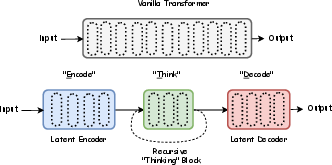
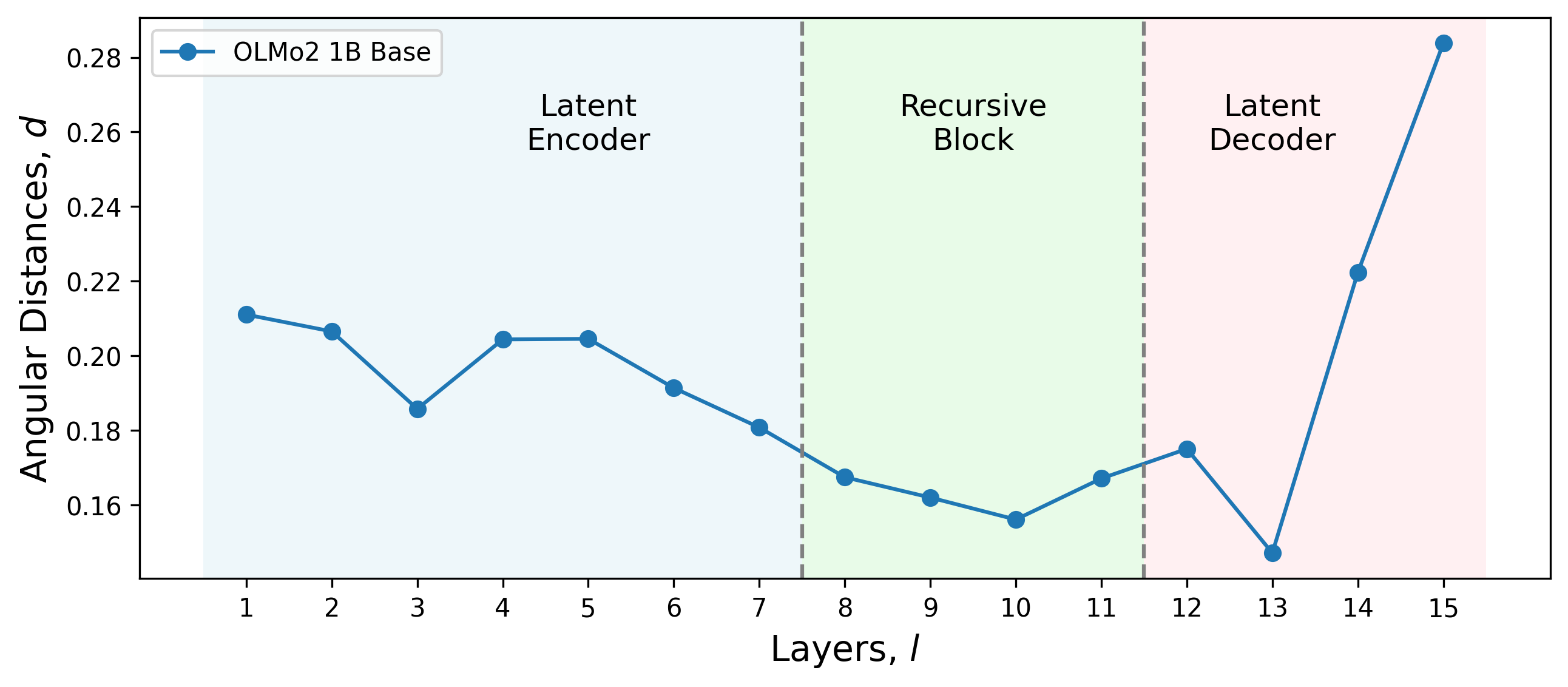
Figure 1: Illustration of the proposed architecture featuring Encode (latent encoder), Think (recursive thinking block), and Decode (latent decoder) sections.
A notable contribution of the ETD method is that it allows recursion over selected layers, bolstering reasoning tasks across diverse benchmarks without revising parameters or introducing auxiliary data. Training reuses open-source pretrained models from the OLMo 2 collection, underlining reproducibility and practicality.
Experimental Results
Empirical results on various benchmarks corroborate ETD's efficacy, particularly in tasks necessitating robust reasoning. With the OLMo-2 1B model, this method shows a remarkable 28.4% improvement in GSM8K and 36% in MATH tasks. These enhancements are attributable to efficient recursion over reasoning-centric layers, aligning computational resources expeditiously within these influential zones (Figure 2).

Figure 2: Results of the ETD method when varying the subset of layers in the recursive block, illustrating the correlation between recursive depth and accuracy.
Additionally, Table 1 reveals performance increments across categories, substantiating ETD's broad applicability in reasoning-stressed contexts.
Adaptive Depth Strategy
ETD also introduces an adaptive depth strategy, adjusting computation per input token. This fine-grained mechanism assesses recursive iterations necessary for each token, dovetailing computational expense with task intricacies. The method derives inspiration from Adaptive Computation Time paradigms, balancing recursive iterations with accuracy gains, particularly in complex tasks like GSM8K (Figure 3).

Figure 3: Comparison of fixed-depth and adaptive-depth ETD with corresponding accuracy outcomes, emphasizing the merits of adaptive strategies in realigning computational depth with task demands.
ETD's recursive latent reasoning offers numerous avenues for future research. Further developments could explore its integration within multimodal architectures and optimize training strategies coupling adaptive depth strategies for improved efficiency. The study's findings suggest latent recurrence as a viable path to amplify reasoning without escalating computational resources, contrasting significantly with prevalent recursive architectures such as fully-recurrent and Mixture-of-Experts models, which do not selectively target reasoning-specific layers.
Conclusion
The "Encode, Think, Decode" framework provides a cogent methodology to advance reasoning within LLMs using latent-space enhancements, presenting researchers with a reproducible, adaptable, and efficient look into recursive design benefits. ETD highlights how recursive depth, when strategically embedded, markedly improves reasoning tasks, paving the way for scalable reasoning with rich implications for real-world applications. Future explorations should consider extending this architecture within broader experimental contexts and evaluative benchmarks to cement its position as a robust mechanism for reasoning amplification in LLMs.

