- The paper introduces SAC, a novel method that integrates document-level summaries into text chunks to mitigate retrieval mismatch.
- It employs LLM-generated summaries and recursive chunking to enhance precision and recall across various legal documents.
- Results show that generic summarization outperforms expert-guided strategies, offering a scalable improvement in RAG system reliability.
Towards Reliable Retrieval in RAG Systems for Large Legal Datasets
Introduction
The paper provides an in-depth look at improving retrieval reliability within Retrieval-Augmented Generation (RAG) systems, specifically when applied to large legal datasets. The paper identifies Document-Level Retrieval Mismatch (DRM) as a prevalent issue in standard RAG pipelines, where information is mistakenly sourced from incorrect documents. To address this, the authors propose Summary-Augmented Chunking (SAC) as a computationally efficient technique to infuse global context into retrieval stages. The approach integrates a synthetic, document-level summary into each chunk, thus enhancing the retriever's ability to select accurately from large, homogeneous legal databases.
Methodology
The methodology is centered around developing and deploying SAC within a legal dataset context. This involves four key steps: producing a document-level summary using LLMs, recursively character-splitting texts into chunks, prepending the summaries to these chunks, and indexing them for retrieval.
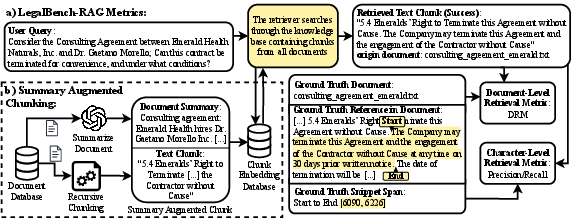
Figure 1: Part a) illustrates how the retrieval quality metrics, DRM and text-level precision/recall, are computed in the LegalBench-RAG.
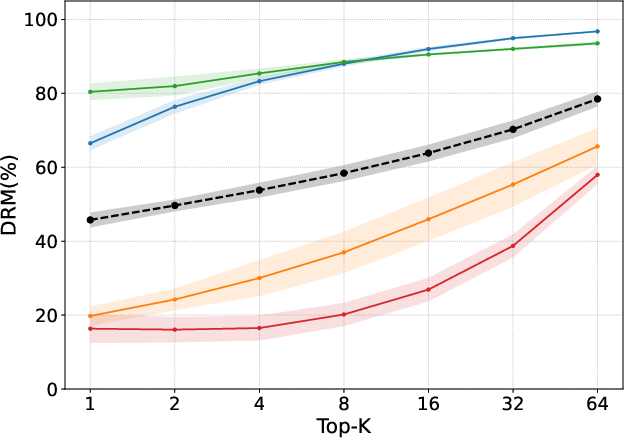
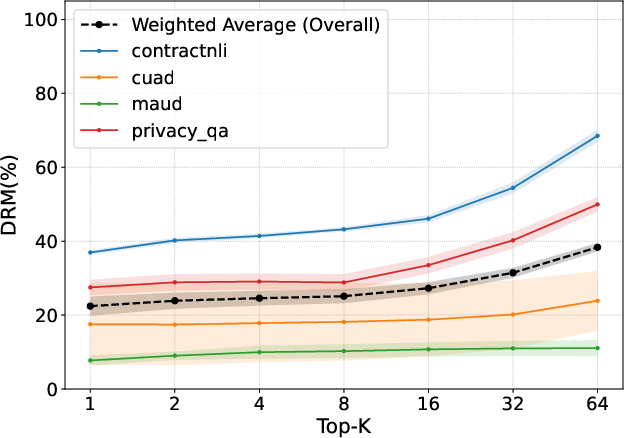
Figure 2: DRM of a standard RAG approach (left) and using SAC (right), applied to the four datasets in the LegalBench-RAG benchmark.
The system was evaluated on the LegalBench-RAG benchmark across a diverse array of legal documents including NDAs, privacy policies, and mergers. The evaluation metrics used were character-level precision/recall and the newly defined DRM, offering quantifiable insight into the retrieval performance.
Results
Using SAC resulted in a marked reduction in DRM across all tested datasets, accompanying improvements in text-level retrieval metrics. The SAC method demonstrated a superior ability to avoid cross-document confusion, a common problem in legal datasets rich with structurally similar documents.
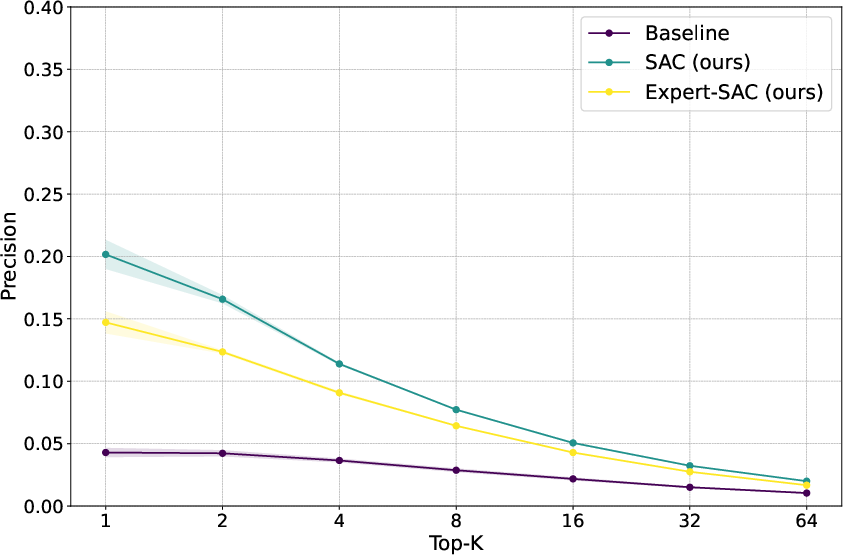
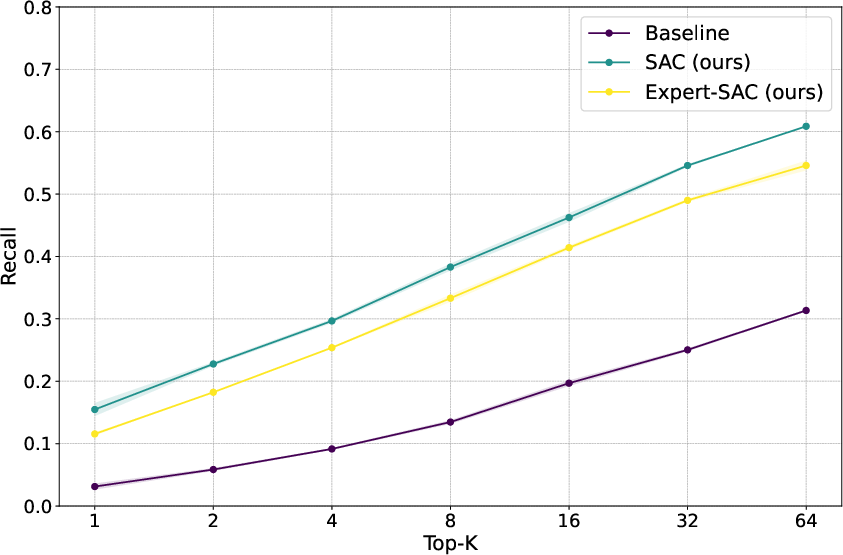
Figure 3: Text-level precision (left) and recall (right) of standard RAG and SAC with general or expert-guided summarization strategy.
However, interestingly, the paper found that generic summarization strategies outperformed expert-guided ones. Despite the structured density and specificity of expert-generated summaries, the broader, more semantically aligned summaries proved more effective for retrieval purposes in this context.
Discussion
The broad semantic cues of generic summarization outperform legally precise summaries within embeddings, raising questions about the interaction between chunk and summary information in semantic space. Insights suggest simple, generic context enrichment strategies are not only computationally efficient but also enhance retrieval effectiveness when dealing with legal datasets.
Future work could explore hierarchical context summarization or the adaptation of query optimization techniques to further refine retrieval accuracy. Additionally, examining the utility of post-retrieval reranking stages presents a promising avenue for improving chunk selection before generation, ultimately enhancing downstream generative tasks.
Conclusion
This research highlights a practical method to bolster the reliability of RAG systems in the legal domain, emphasizing the significant role of SAC in addressing Document-Level Retrieval Mismatch. While SAC is not exhaustive in resolving all retrieval challenges, it offers a scalable, easily integrable approach that meaningfully improves the retriever's performance in legally critical AI applications.
By advancing retrieval reliability, this research contributes to foundational work needed to establish AI as a dependable assistant in processing and navigating complex legal documents.