DeepScientist: Advancing Frontier-Pushing Scientific Findings Progressively
Abstract: While previous AI Scientist systems can generate novel findings, they often lack the focus to produce scientifically valuable contributions that address pressing human-defined challenges. We introduce DeepScientist, a system designed to overcome this by conducting goal-oriented, fully autonomous scientific discovery over month-long timelines. It formalizes discovery as a Bayesian Optimization problem, operationalized through a hierarchical evaluation process consisting of "hypothesize, verify, and analyze". Leveraging a cumulative Findings Memory, this loop intelligently balances the exploration of novel hypotheses with exploitation, selectively promoting the most promising findings to higher-fidelity levels of validation. Consuming over 20,000 GPU hours, the system generated about 5,000 unique scientific ideas and experimentally validated approximately 1100 of them, ultimately surpassing human-designed state-of-the-art (SOTA) methods on three frontier AI tasks by 183.7\%, 1.9\%, and 7.9\%. This work provides the first large-scale evidence of an AI achieving discoveries that progressively surpass human SOTA on scientific tasks, producing valuable findings that genuinely push the frontier of scientific discovery. To facilitate further research into this process, we will open-source all experimental logs and system code at https://github.com/ResearAI/DeepScientist/.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces DeepScientist, an AI system that does science on its own for weeks at a time. Its goal is simple: start from the best human-made methods in a field and keep improving them, step by step, until it beats the current best results. The authors show that DeepScientist can do this across three tough AI problems, sometimes matching years of human progress in just a couple of weeks.
What questions were they trying to answer?
- Can an AI go beyond mixing old ideas and actually create new, valuable methods that beat the best human-designed ones?
- How should an AI plan and run long cycles of research (idea → test → analyze) when each experiment is slow and expensive?
- What does it take to guide the AI’s exploration so it doesn’t waste time, and how well does it scale with more computing power?
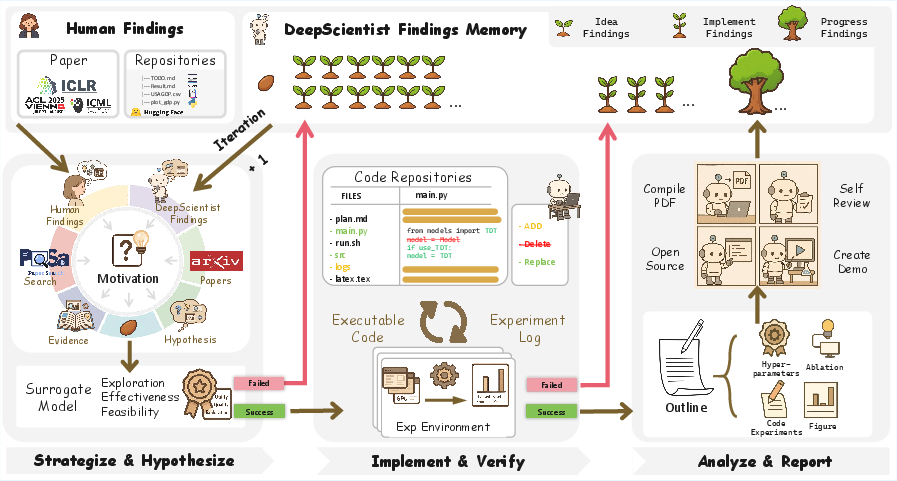
How does DeepScientist work?
The big idea: turn discovery into a smart treasure hunt
Think of scientific discovery like searching a huge, foggy landscape for treasure. You can’t dig everywhere—it’s too expensive. DeepScientist treats this as a “smart search” problem called Bayesian Optimization:
- It builds a rough “map” that guesses which ideas might be valuable (this is the surrogate model).
- It then decides where to “dig” next by balancing two goals: try the spots that seem best so far (exploitation) and also try some new places that look uncertain but promising (exploration).
In everyday terms: it’s like playing a hot-and-cold game with a clever guide who remembers where you checked, how hot it felt, and suggests the next best place to try.
A three-step research loop
To stay focused and save time, DeepScientist runs a repeatable cycle:
- Hypothesize: Generate many new ideas based on what’s known and what has already been tried.
- Verify: Pick the most promising ideas and actually test them with code and experiments.
- Analyze: If something beats the current best, run deeper tests (like ablations and extra checks) and then write up the findings.
A “Findings Memory” to learn from everything
DeepScientist keeps a growing memory bank of:
- human knowledge (papers, code),
- its own ideas (even the failed ones),
- and all experiment results. This memory helps it avoid repeating mistakes and build on what works—like a very organized lab notebook that also acts like a coach.
Choosing what to test next
When it has too many ideas to test, it uses a selection rule (Upper Confidence Bound, or UCB). In simple terms, this rule says:
- Prefer ideas that look strong so far.
- But also try some that are uncertain—you might discover something new. This keeps the system from getting stuck and helps it find breakthroughs faster.
Scale and safety
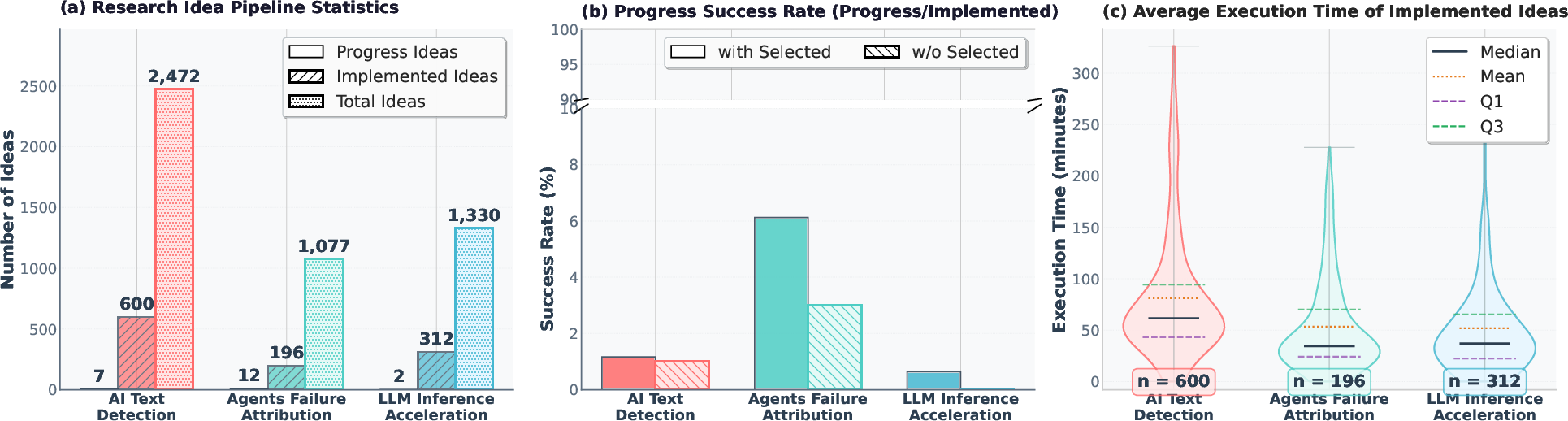
The team ran DeepScientist for weeks on powerful GPUs (special computers for AI), generating about 5,000 ideas, testing ~1,100, and turning 21 into real scientific advances. They also checked for safety risks and kept humans in the loop to verify results.
What did they discover?
Across three cutting-edge AI tasks, DeepScientist created new methods that beat the best human-made systems:
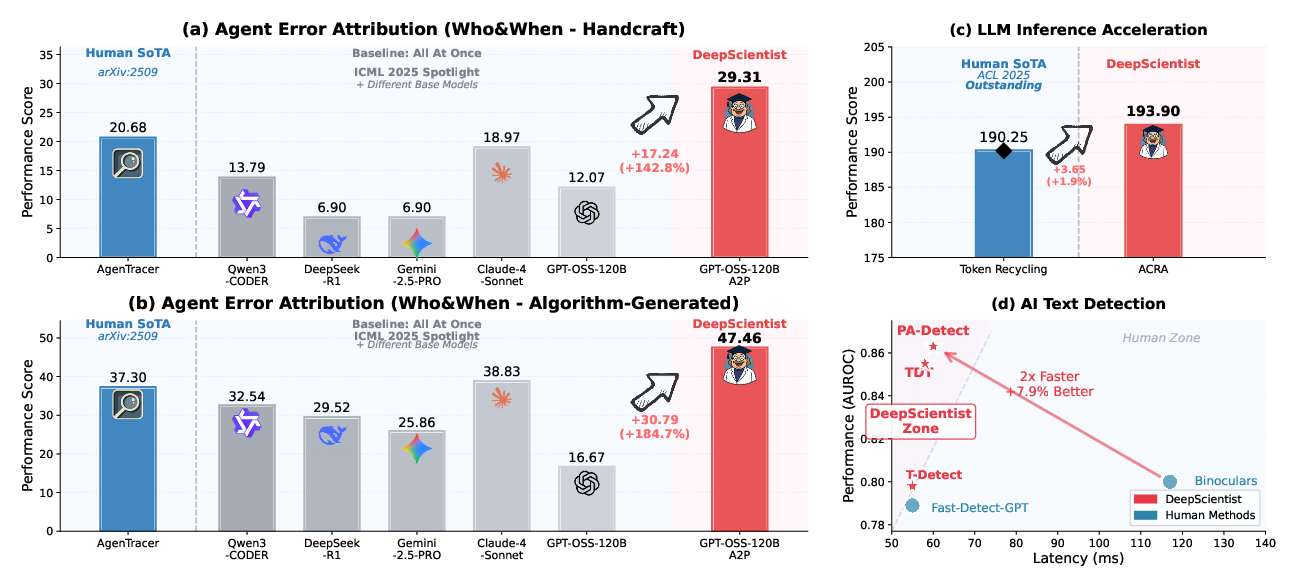
- Agent Failure Attribution (finding which AI teammate caused a failure and when it happened)
- New method: A2P (Abduction-Action-Prediction), which uses causal reasoning (asking “what if we changed this step—would it work?”) instead of just pattern matching.
- Result: Improved accuracy by about 184% over the human state-of-the-art (SOTA).
- LLM Inference Acceleration (making LLMs respond faster)
- New method: ACRA, which notices stable patterns near the end of generated text and uses them to speed up decoding.
- Result: About 1.9% higher tokens-per-second than the human SOTA. That seems small, but tiny gains matter a lot in a highly optimized area.
- AI Text Detection (telling if a piece of writing was made by a human or an AI)
- New methods: T-Detect → TDT → PA-Detect, a rapid sequence of improvements over two weeks.
- Result: About 7.9% better AUROC (a measure of detection quality) and roughly double the speed compared to the previous best.
Why this matters: These aren’t just tweaks; the system redesigned core ideas (like shifting from simple statistics to “treat text like a signal” with wavelets and phase analysis), which is a sign of real scientific creativity.
How did they test quality and reliability?
- They used 20,000+ GPU hours, ran thousands of experiments, and kept strict logs.
- Human experts reviewed the AI-written papers and found the ideas genuinely novel and valuable, with acceptance-like scores that match typical submissions to top AI conferences.
- The team found that only a small fraction of ideas succeed (about 1–3% of tested ideas), so smart filtering and careful validation are crucial.
Why is this important, and what’s the impact?
- AI can push the frontier, not just follow it: This is among the first large-scale proofs that an AI can repeatedly produce discoveries that beat the current best.
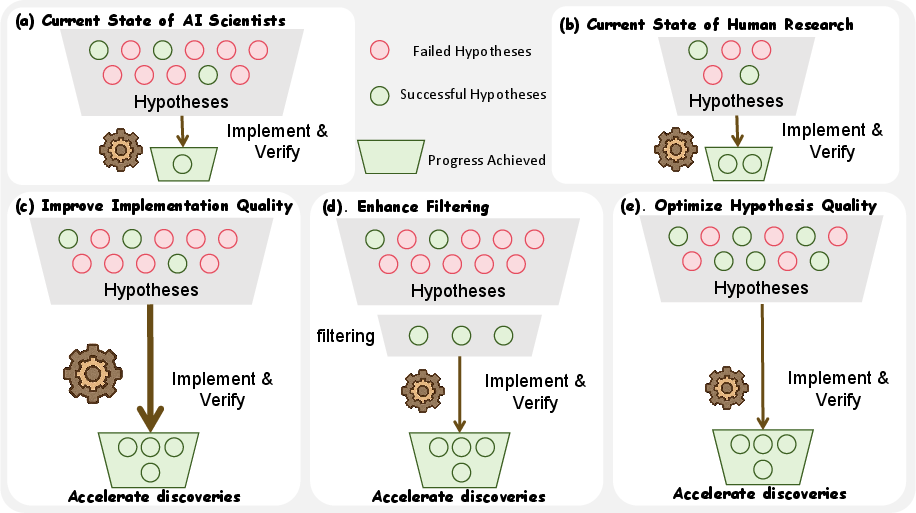
- The real bottleneck is filtering and validation: The AI can generate ideas fast, but most don’t work or fail during implementation. Efficient selection and reliable testing matter more than ever.
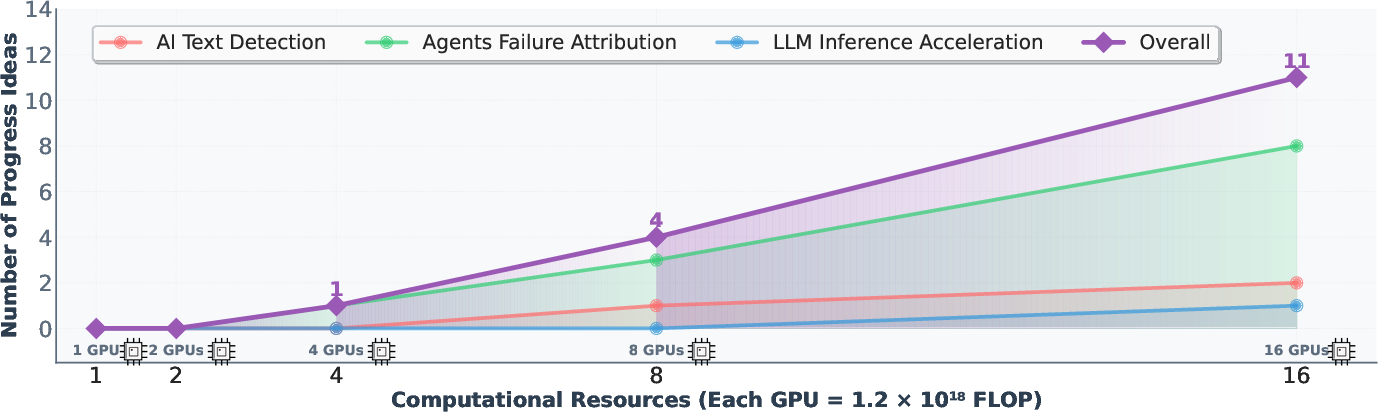
- Scaling helps—smartly: Giving the system more GPUs led to nearly linear growth in useful discoveries, especially because all parallel runs share their knowledge in the Findings Memory.
- Human–AI teamwork is the future: Humans set high-level goals and check results; the AI does massive, tireless exploration. This can compress years of trial-and-error into weeks.
- Ethics and safety: The authors emphasize safeguards to prevent misuse (like harmful research), keep humans accountable, and avoid flooding science with unverified papers.
In short, DeepScientist shows a powerful new way to do science: goal-driven, memory-informed, and looped through continuous hypothesize–test–analyze cycles. It suggests a future where humans guide the mission, and AI accelerates the journey—turning long, slow climbs into faster, safer ascents.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Formalization of the hypothesis space: the paper does not specify a principled representation of the conceptual space of candidate methods (𝓘) beyond free-form LLM text; future work should define structured parameterizations or programmatic grammars that enable measurable coverage, diversity, and controllability during search.
- Surrogate model calibration: no quantification of how well the LLM Reviewer’s valuation vector V = ⟨v_u, v_q, v_e⟩ predicts realized scientific value f(I); researchers should report calibration curves, rank correlations, and predictive metrics, and study failure modes of the surrogate.
- Uncertainty modeling: v_e (exploration value) is LLM-assigned rather than derived from a probabilistic uncertainty estimate; integrate and compare GP-based uncertainty, Bayesian neural nets, or ensemble predictive variance with the current LLM scoring.
- Acquisition function design: UCB on LLM-generated scores is ad hoc; conduct sensitivity analyses on w_u, w_q, κ, compare against EI/PI/Thompson sampling, and evaluate multi-objective BO formulations that explicitly trade off value, novelty, and implementation risk.
- Noise and repeatability in f(I): evaluations are treated as deterministic, yet scientific metrics are noisy; add repeated trials, bootstrapping, error bars, and robust BO under heteroscedastic noise to avoid over-selecting spurious gains.
- Multi-fidelity optimization: the three-stage pipeline implies nested fidelities but lacks a formal multi-fidelity BO model; implement and benchmark MF-BO that leverages cheap proxies (ablation subsets, smaller models, synthetic datasets) before high-cost runs.
- Findings Memory retrieval: Top-K selection mechanisms and retrieval models are not characterized; quantify retrieval precision/recall, memory growth/decay policies, and how retrieval quality influences downstream success rates.
- Memory management and bias: no strategy for pruning, weighting, or de-biasing accumulated findings; study recency bias, confirmation bias, and catastrophic forgetting, and design memory governance (e.g., aging, de-duplication, contradiction handling).
- Idea quality vs. implementation correctness: ~60% failures are attributed to implementation errors; evaluate self-debugging tools, test-driven development agents, static/dynamic analysis, and sandbox instrumentation to reduce execution failure rates.
- Autonomy vs. human supervision: three human experts supervise and filter hallucinations without quantified intervention frequency or impact; report oversight load, inter-annotator agreement, and ablate the system under stricter autonomy to assess reliability.
- Generalization across domains: results are limited to three ML-centric tasks with fast feedback; test domains with slower or physical evaluations (e.g., robotics, chemistry) and quantify how discovery efficiency degrades with evaluation latency/cost.
- External validity of SOTA claims: SOTA comparisons use specific baselines and settings (e.g., Falcon-7B for detection); broaden baselines, models, and datasets (different LLMs, languages, genres), include adversarial and paraphrase robustness, and report statistical significance.
- Reproducibility of performance metrics: tokens/second and latency are sensitive to hardware/software stacks; publish detailed environment specs (GPU model, kernel, batching, KV-cache settings), standardize benchmarking harnesses, and provide repeatable scripts.
- Statistical rigor: no p-values, confidence intervals, or multiple-hypothesis corrections are reported; incorporate formal statistical testing and power analyses, especially when improvements are small (e.g., +1.9% throughput).
- Detection task robustness: the “non-stationarity” insight is hypothesized but not stress-tested; evaluate across diverse generators, detectors, domains, and perturbations (noise, edit distance, paraphrasing, translation) to confirm generality.
- Avoidance of engineering combinations: the deliberate exclusion of known optimizations (e.g., layer skipping, PageAttention) conflates “scientific novelty” with “performance”; study principled ways to combine novel ideas with best-known engineering for a fair utility assessment.
- Scaling law characterization: the near-linear scaling claim over one week and up to 16 GPUs lacks uncertainty quantification; extend to longer horizons, more resources, randomized seeds, and report confidence intervals, saturation points, and negative interaction effects.
- Synchronization frequency: global memory sync every five cycles is fixed; probe the effect of sync cadence on convergence, diversity, and redundancy, and design adaptive or topology-aware synchronization policies.
- Cost–benefit analysis: 20,000 GPU hours yielded 21 progress findings; formalize expected value per GPU-hour, include opportunity costs, and study trade-offs with improved surrogate accuracy or implementation reliability.
- Surrogate training and adaptation: the LLM Reviewer is untrained for prediction fidelity; explore fine-tuning on historical outcomes (pairwise preferences, ordinal regression), online learning, and active learning to improve guidance over time.
- Safety and dual-use evaluation: red-teaming is limited to malware-like tasks on specific models; broaden to other high-risk domains (bio, cyber-physical), define quantitative safety auditing protocols, and test under weaker model alignments or open-source LLMs.
- Transparency of code and modules: the “Analyze {paper_content} Report” module is withheld; provide auditable artifacts, provenance metadata, and reproducibility checklists for the discovery and validation phases to support independent verification.
- Benchmark leakage and overfitting: repeated exploration on fixed benchmarks (e.g., RAID, MBPP, WhoWhen) risks overfitting; use held-out suites, time-split datasets, and cross-benchmark generalization tests.
- Failure taxonomy: the 300-trial failure analysis is summarized but not systematized; publish a detailed taxonomy (design flaw, data misuse, metric misalignment, code defect types), and link failure classes to targeted mitigations.
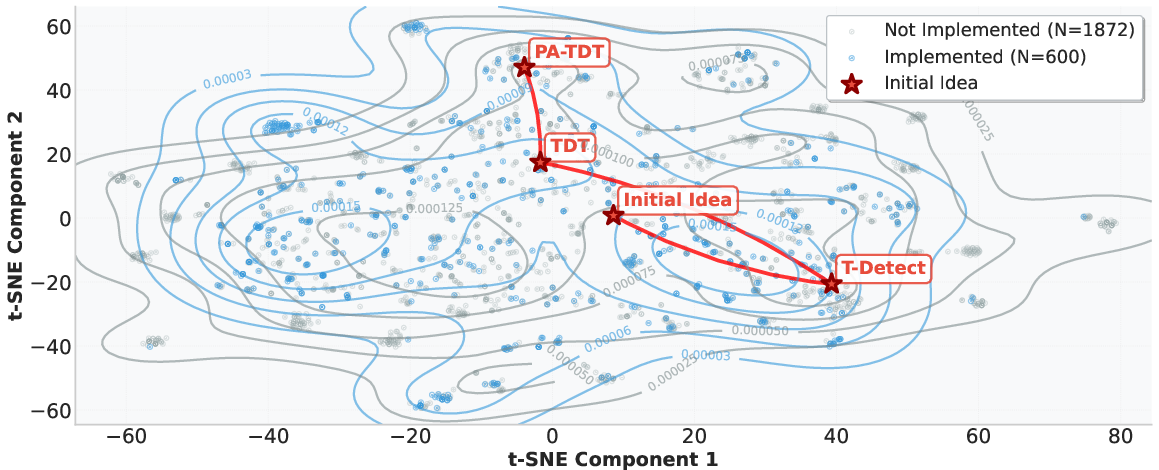
- Idea diversity measurement: the t-SNE plot is qualitative; quantify idea diversity, coverage, and novelty (e.g., embedding distance metrics, cluster entropy), and relate diversity to success probability.
- Evaluation alignment: v_q (quality) and v_u (utility) definitions are opaque; formalize rubric criteria, inter-rater reliability for LLM reviewers, and investigate prompt variance and anchoring effects.
- Theoretical grounding: treating discovery as BO over an unstructured, creative hypothesis space lacks theoretical guarantees; develop theory for BO with language-generative surrogates, including convergence under biased proposal distributions.
- Multi-agent coordination: agent roles and tool usage are described but not compared; ablate agent architectures, role specialization, toolchains (MCP variants), and quantify their contributions to throughput and success rates.
- Data and codebase reuse policies: implementing on top of baseline repositories may introduce dependency biases; study cross-repo portability, codebase heterogeneity, and the effect of repository quality on discovery outcomes.
- Language/model dependence: core logic uses Gemini-2.5-Pro and code generation uses Claude-4-Opus; assess portability to open models (e.g., Llama, Qwen), quantify performance deltas, and the impact of model choice on discovery efficiency.
- Ethical license enforcement: proposed license addendums are untested; investigate practical enforceability, potential chilling effects, and community governance mechanisms that balance openness with responsible use.
- Human comparative baselines: claims of compressing “years of human exploration into weeks” lack controlled comparisons; run matched human–AI discovery studies with identical budgets and goals to quantify relative efficiency and outcome quality.
- Long-horizon discovery dynamics: the month-long timeline is promising but short; study stability, drift, forgetting, and cumulative impact over multi-month cycles, including how early biases propagate through the memory and selection pipeline.
Glossary
- Ablation: A controlled experiment that removes or alters components to test their contribution to performance. "deeper analytical experiments (e.g., ablations, evaluations on new datasets)"
- Abduction: A form of inference that proposes the most plausible explanation for observed data. "Named for its Abduction-Action-Prediction process"
- Acquisition Function: A strategy in Bayesian optimization that guides which candidate to evaluate next by trading off exploration and exploitation. "the system employs an Acquisition Function ()."
- AUROC: Area Under the Receiver Operating Characteristic; a scalar measure of binary classifier performance across thresholds. "establishing a new SOTA with a 7.9\% higher AUROC while also doubling the inference speed."
- Bayesian Optimization: A global optimization method for expensive black-box functions using a probabilistic surrogate to guide sampling. "We formally model the full cycle of scientific discovery as a goal-driven Bayesian Optimization problem"
- Black-box function: A function whose internal workings are unknown, evaluated only via inputs and outputs. "This value is determined by a latent, black-box true value function, "
- Causal reasoning: Reasoning about cause and effect to determine how changes lead to outcomes. "elevates failure attribution from pattern recognition to causal reasoning"
- Counterfactual reasoning: Considering alternate scenarios to assess what would have happened under different actions. "lacks the counterfactual reasoning capabilities essential for attribution."
- Exploration–exploitation trade-off: The balance between trying new options and leveraging known good ones in optimization. "balance the trade-off between exploiting promising avenues (represented by and ) and exploring uncertain ones (represented by )"
- Findings Memory: A structured, accumulating knowledge base of ideas, results, and analyses that guides subsequent exploration. "The architecture of DeepScientist actualizes the Bayesian Optimization loop through a multi-agent system equipped with an open-knowledge system and a continuously accumulating Findings Memory."
- FLOPs: Floating-point operations; a measure of computational cost. "on the order of FLOPs for a frontier LLM problem"
- Kalman Filter: A recursive estimator that fuses noisy measurements to track dynamic states. "such as using a Kalman Filter \citep{zarchan2005progress} to dynamically adjust an adjacency matrix"
- Krippendorff's alpha: A reliability coefficient that quantifies inter-rater agreement across multiple annotators. "Inter-rater reliability for Rating: Krippendorff's = 0.739."
- Layer skipping: An inference-time technique that omits certain neural network layers to accelerate computation. "one could likely achieve greater performance gains by combining ACRA with an established technique like layer skipping \citep{wang2022skipbert} or PageAttention \citep{kwon2023efficient}"
- MCP tools: Tools following the Model Context Protocol to enable agents to interact with external resources consistently. "capable of utilizing a suite of MCP \citep{hou2025model} tools."
- Non-stationarity: Statistical properties that change over position or time rather than remaining constant. "reveals the \"non-stationarity\" of AI-generated text"
- PageAttention: An attention optimization method for efficient inference by managing memory pages. "one could likely achieve greater performance gains by combining ACRA with an established technique like layer skipping \citep{wang2022skipbert} or PageAttention \citep{kwon2023efficient}"
- Phase congruency analysis: A signal-processing approach that detects features based on alignment of phase information across scales. "use wavelet and phase congruency analysis to pinpoint anomalies."
- Retrieval model: A model used to select relevant items (e.g., prior findings) from a large corpus given a query. "we use a separate retrieval model \citep{wolters2024memoryneedoverviewcomputeinmemory} when needed to select the Top-K Findings as input."
- Sandboxed environment: A restricted execution context that isolates processes for safety and reproducibility. "This agent operates within a sandboxed environment with full permissions"
- Scaling laws: Empirical relations describing how performance or outcomes change with resource scale. "Scaling Laws in DeepScientist's Scientific Discovery."
- Semantic embeddings: Vector representations that encode the meaning of text or concepts for similarity and visualization. "The plot shows a t-SNE visualization of the semantic embeddings for all 2,472 generated ideas."
- SOTA: State-of-the-art; the best-known performance or method in a field at a given time. "DeepScientist exceeds their respective human SOTA methods by 183.7\% (Accuracy), 1.9\% (Tokens/second), and 7.9\% (AUROC)"
- Surrogate model: A cheaper-to-evaluate model that approximates an expensive objective in optimization. "The surrogate model (an LLM Reviewer) is first contextualized with the entire Findings Memory."
- t-distribution: A statistical distribution robust to outliers, often used when sample sizes are small or variances are unknown. "This began with T-Detect fixing core statistics with a robust t-distribution"
- t-SNE visualization: A technique (t-distributed Stochastic Neighbor Embedding) for projecting high-dimensional data into 2D/3D for visualization. "The plot shows a t-SNE visualization of the semantic embeddings for all 2,472 generated ideas."
- Upper Confidence Bound (UCB): An acquisition strategy that selects points with high estimated reward plus uncertainty. "Specifically, it uses the classic Upper Confidence Bound (UCB) algorithm to select the most promising record."
- Valuation vector: A structured set of scores (e.g., utility, quality, exploration) used to rank candidate ideas. "produces a structured valuation vector "
- Wavelet Subspace Energy: A method that analyzes energy in wavelet-transformed subspaces to detect signal anomalies. "exploring approaches like Volatility-Aware and Wavelet Subspace Energy methods."
- Zero-shot: Performing a task without task-specific training by leveraging generalization from pretraining. "All zero-shot methods, including the system-generated T-Detect, TDT, and PA-Detect, uniformly adopt Falcon-7B \citep{almazrouei2023falcon} as the base model."
Practical Applications
Immediate Applications
Below is a concise set of deployable use cases derived from the paper’s findings and methods, grouped by sector and noting key dependencies or assumptions.
- Software and AI Engineering
- A2P-based agent failure attribution for LLM Ops
- Application: Integrate A2P (Abduction–Action–Prediction) into multi-agent LLM pipelines to pinpoint which agent and step caused failure; auto-suggest counterfactual fixes and retests.
- Sector: Software, robotics, autonomous systems.
- Tools/products/workflows: “AgentTracer” plugin for orchestration frameworks (LangChain, AutoGen, CrewAI), LLM Ops dashboards with counterfactual replay, RCA (root-cause analysis) reports in CI pipelines.
- Assumptions/dependencies: Access to detailed agent logs and action traces; stable base models for counterfactual prediction; privacy-preserving logging; calibration on target domain (Who-When-like benchmarks may not fully represent production variability).
- ACRA decoding “memory” for inference servers
- Application: Ship ACRA (adaptive context recall for decoding) as an optional decoding strategy to slightly improve tokens/sec without retraining.
- Sector: Software (inference infrastructure), cloud AI.
- Tools/products/workflows: Plugins for vLLM, TGI, TensorRT-LLM; “Turbo Decode” flag in Chat/Inference APIs; auto-profiling and rollback if quality regresses.
- Assumptions/dependencies: Compatibility with target hardware and model family; performance depends on suffix pattern stability in real workloads; guardrails for quality/latency trade-offs.
- Media, Education, and Platform Integrity
- PA-Detect/TDT/T-Detect for AI text detection
- Application: Deploy detector APIs with phase congruency and wavelet features to flag likely AI-generated text in publishing workflows, LMS assignments, social platforms, and enterprise compliance.
- Sector: Education, publishing, social media, enterprise compliance, public sector.
- Tools/products/workflows: “Authenticity Scanner” API (≤60 ms latency); LMS and CMS integrations; newsroom dashboards; moderation queues; forensic reports with calibrated thresholds.
- Assumptions/dependencies: Domain-specific calibration to manage false positives; model/version drift; adversarial evasion awareness; legal/process policies for how detections are acted upon.
- Research Operations (Industry and Academia)
- Findings Memory + UCB-based research scheduler
- Application: Adopt the hierarchical “Hypothesize–Verify–Analyze” loop to triage ideas, run low-cost surrogate reviews, and promote only promising hypotheses to expensive experiments.
- Sector: R&D labs, ML research groups, research tooling vendors.
- Tools/products/workflows: “Discovery Orchestrator” with LLM Reviewer surrogate; a structured Findings Memory database; UCB-based experiment queue; MCP tool integration for reproducible experimentation.
- Assumptions/dependencies: Tasks with relatively fast feedback loops; governance to prevent model hallucinations; reproducible code/eval harnesses; human-in-the-loop verification.
- Research CRM for hypothesis lifecycle tracking
- Application: Use the Findings Memory schema as a “Research CRM” to record idea valuations, experiment logs, ablations, and paper-quality synthesis.
- Sector: Corporate knowledge management, academic groups.
- Tools/products/workflows: Knowledge graph + retrieval; Top-K idea surfacing; report generation for project reviews; cross-team synchronization.
- Assumptions/dependencies: Consistent metadata and experiment standards; data retention and IP policies; team buy-in for disciplined logging.
- Cloud and Compute Management
- Parallel exploration planning with shared memory
- Application: Schedule N parallel exploration paths per identified limitation, periodically synchronize Findings Memory to increase discovery yield per GPU-hour.
- Sector: Cloud providers, large labs, platform teams.
- Tools/products/workflows: GPU cluster orchestration with “shared knowledge” sync; ROI dashboards tracking progress findings/week; auto-scaling policies for discovery workloads.
- Assumptions/dependencies: Sufficient compute; workloads conducive to parallel ideation; robust synchronization without knowledge conflicts; cost monitoring.
- Policy and Governance
- Operational guardrails and audit trails for autonomous discovery
- Application: Enforce human supervision and audit logging (per paper’s licensing stance) when adopting autonomous research loops in organizations.
- Sector: Public policy, enterprise governance, academia.
- Tools/products/workflows: Policy templates, compliance checklists, capability/red-teaming gates; license addenda mirroring “human oversight required”.
- Assumptions/dependencies: Organizational willingness to implement governance; legal review; transparency in logging and decision traces.
- Daily Life / End-User Tools
- Authenticity browser extension and document checker
- Application: Lightweight client-side text authenticity checker that leverages PA-Detect/TDT for personal use (e.g., verifying emails, resumes, essays).
- Sector: Consumer software.
- Tools/products/workflows: Browser extension and desktop app; privacy-preserving local inference where feasible; actionable confidence scores and caveats.
- Assumptions/dependencies: On-device model performance/cost; clear UX on uncertainty and false positives; regular updates to handle model drift.
Long-Term Applications
These use cases require additional research, scaling, or cross-domain integration—especially where experiments are costly or physical.
- Autonomous Science in Physical and Wet Labs
- Closed-loop discovery for materials, energy, and chemistry
- Application: Integrate DeepScientist’s loop with robotic labs to discover novel materials (e.g., photovoltaics, batteries), catalysts, or chemical pathways.
- Sector: Energy, materials science, chemical engineering.
- Tools/products/workflows: Robotics + MCP integration; high-fidelity surrogate modeling; Bayesian experiment design; lab data pipelines; automated ablations.
- Assumptions/dependencies: High-cost experiments; reliable simulators; safety protocols; strong domain priors; regulatory compliance.
- Drug discovery and bioengineering loops
- Application: Hypothesis generation + triage for targets, scaffolds, and synthesis conditions; incrementally validated with wet-lab automation.
- Sector: Healthcare, pharma, biotech.
- Tools/products/workflows: Multi-fidelity evaluation (in silico → in vitro → in vivo), ethical and safety gates, data governance for sensitive biosafety.
- Assumptions/dependencies: Extremely high evaluation cost; safety and ethics oversight; data availability; translational validity of surrogates.
- Safety-Critical Systems
- Causal failure attribution for autonomous vehicles and robots
- Application: Extend A2P to multicomponent systems (perception, planning, control) to identify failure causes and counterfactual fixes in simulation.
- Sector: Robotics, automotive, aerospace.
- Tools/products/workflows: High-fidelity digital twins; counterfactual scenario generation; compliance-ready RCA reporting.
- Assumptions/dependencies: Accurate simulators; extensive telemetry; standards for safety certification; limits of counterfactual validity.
- AI System Design and Hardware–Software Co-Optimization
- Decoding architectures with persistent memory
- Application: Generalize ACRA into new decoder architectures and compiler/runtime support for memory-infused decoding (beyond suffix patterns).
- Sector: Software, semiconductor/accelerator vendors.
- Tools/products/workflows: Runtime schedulers; compiler passes; model–hardware co-design; benchmark suites for quality and speed.
- Assumptions/dependencies: Model changes may affect quality; hardware constraints; standardized evaluation to ensure fairness and reproducibility.
- National Research Infrastructure and Policy
- AI discovery clusters and compute governance
- Application: Establish national or consortium-level “AI Discovery Clusters” with shared Findings Memory across institutions; compute governance that ties scale to oversight and audit.
- Sector: Public policy, academic consortia, national labs.
- Tools/products/workflows: Cross-institution knowledge bases; reproducibility registries; audit trails; safety gates for dual-use risk.
- Assumptions/dependencies: Interoperable standards; secure data-sharing; funding and governance frameworks; legal harmonization.
- Provenance standards for AI-generated content
- Application: Combine robust detection (PA-Detect/TDT) with watermarking and cryptographic provenance in media and public communications.
- Sector: Media, civic information, education.
- Tools/products/workflows: Content authenticity protocols; interoperable metadata; escalation policies for detected content.
- Assumptions/dependencies: Broad ecosystem adoption; adversarial robustness; careful balancing of privacy and verification.
- Enterprise Discovery Platforms and Marketplaces
- Productization of an “Autonomous Discovery Platform”
- Application: Offer DeepScientist-like platforms via cloud providers for enterprise R&D with built-in governance, licensing, and reproducibility.
- Sector: Cloud, enterprise software.
- Tools/products/workflows: Managed service with UCB scheduler, surrogate reviewers, MCP toolchains, compliance modules; “Findings Marketplace” for sharing vetted progress.
- Assumptions/dependencies: IP management, credit attribution, secure knowledge exchange, third-party validations.
- Education and Scientific Ecosystem Evolution
- AI-augmented research curricula and lab workflows
- Application: Train students and researchers to formulate goals and guide autonomous exploration engines; reorienting human roles toward strategy and synthesis.
- Sector: Education, academia.
- Tools/products/workflows: Courseware around hypothesis selection, experiment governance, failure analysis; shared repositories for idea triage.
- Assumptions/dependencies: Cultural shifts in research practice; institutional support; safeguards against unverified paper generation (as highlighted in the ethics section).
- AI Safety and Red-Teaming Frameworks
- Continuous capability evaluation and dual-use risk gates
- Application: Institutionalize autonomous red-teaming loops that escalate only under human approval, with system-level refusals for harmful objectives.
- Sector: AI safety, governance.
- Tools/products/workflows: Capability cards; refusal audits; human oversight triggers; standardized safety benchmarks.
- Assumptions/dependencies: Strong safety alignment in foundation models; enforceable policies and licensing; external audits.
In summary, DeepScientist’s core innovations—goal-oriented Bayesian optimization for discovery, a hierarchical multi-fidelity loop, and a cumulative Findings Memory—yield immediately deployable tools in AI engineering and integrity, while opening a pathway to autonomous science at scale in the physical world. Feasibility hinges on compute availability, fast feedback loops, robust governance, and careful calibration to domain specifics.
Collections
Sign up for free to add this paper to one or more collections.