- The paper presents a three-stage pipeline that extracts human and object trajectories from videos, trains an RL policy with a residual action space, and enables zero-shot deployment on real robots.
- The paper demonstrates that a unified object representation and tailored interaction rewards significantly improve exploration stability and performance in complex tasks.
- The paper validates HDMI with real-world experiments, showing robust number of tasks like door traversal and box locomotion while adapting to varying environmental conditions.
HDMI: Learning Interactive Humanoid Whole-Body Control from Human Videos
The paper "HDMI: Learning Interactive Humanoid Whole-Body Control from Human Videos" introduces a novel framework called HDMI, which utilizes monocular RGB videos to endow humanoid robots with the ability to perform diverse whole-body interaction tasks. This approach leverages human demonstration videos to create a structured dataset for reinforcement learning (RL). The result is a general framework capable of producing robust and versatile humanoid-object interaction skills.
Framework Overview
HDMI comprises a three-stage pipeline designed to handle the complexity of whole-body humanoid-object interactions:
- Data Extraction and Retargeting: Human and object trajectories are extracted and retargeted from monocular RGB videos using pose estimation methods. This step generates a structured motion dataset, which includes desired contact points and reference trajectories.
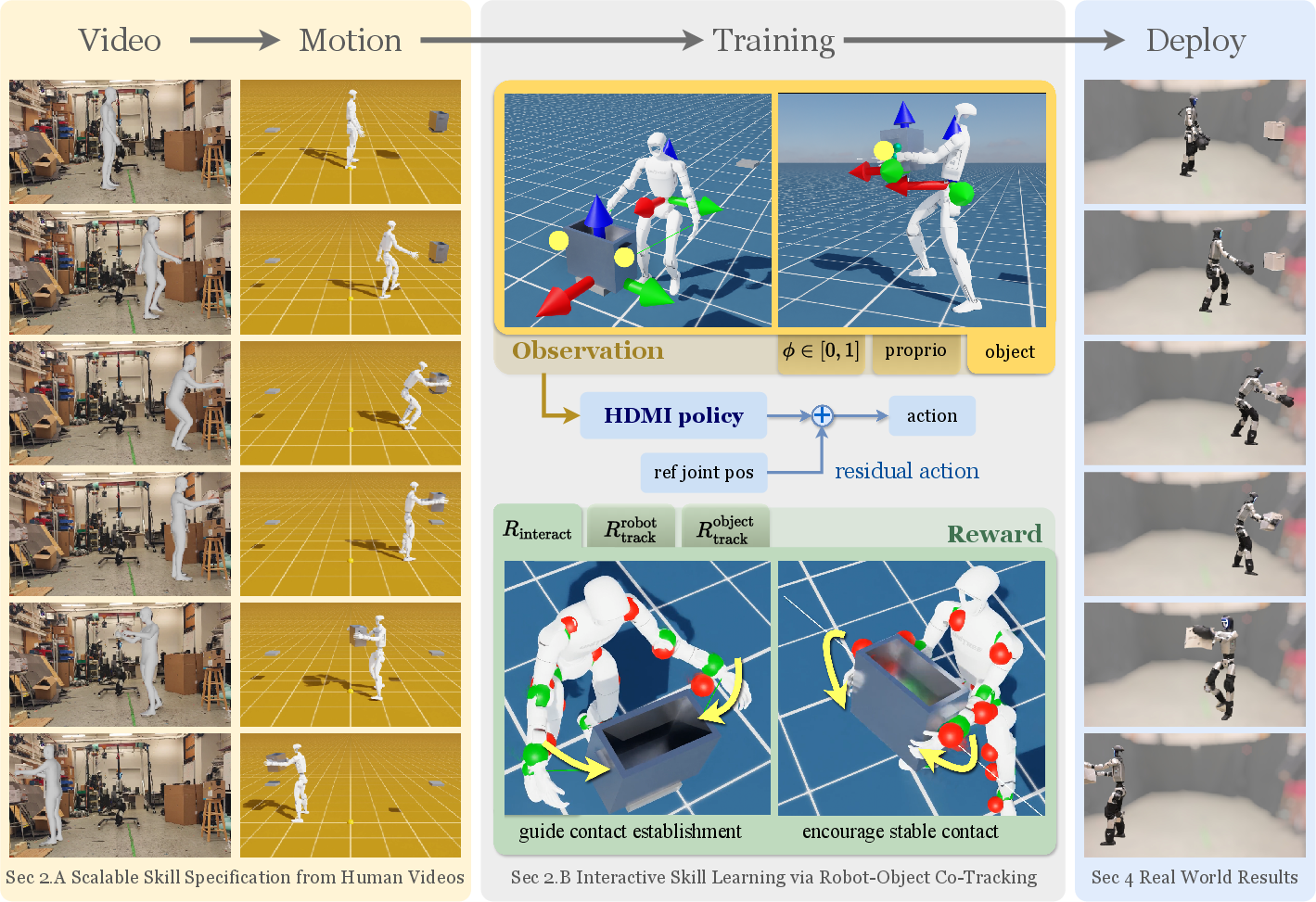
Figure 1: HDMI is a general framework for interactive skill learning. Monocular RGB videos are processed into a structured dataset as reference trajectories.
- Reinforcement Learning Policy Training: An interaction-centric RL policy is trained using the structured dataset. Key components include:
- A unified object representation for accommodating diverse object types and interactions.
- A residual action space that facilitates stable exploration and efficient learning of complex poses.
- An interaction reward designed to promote robust and precise contact behavior.
- Zero-Shot Deployment: The trained policies are deployed on real humanoid robots without additional fine-tuning, demonstrating successful execution of interaction tasks in real-world scenarios.
Key Components
Unified Object Representation
The method employs a unified object representation, leveraging spatially invariant object observations that are transformed into the robot's local frame. This representation allows HDMI to generalize across varied object geometries and operate effectively with diverse objects, ensuring wide applicability.
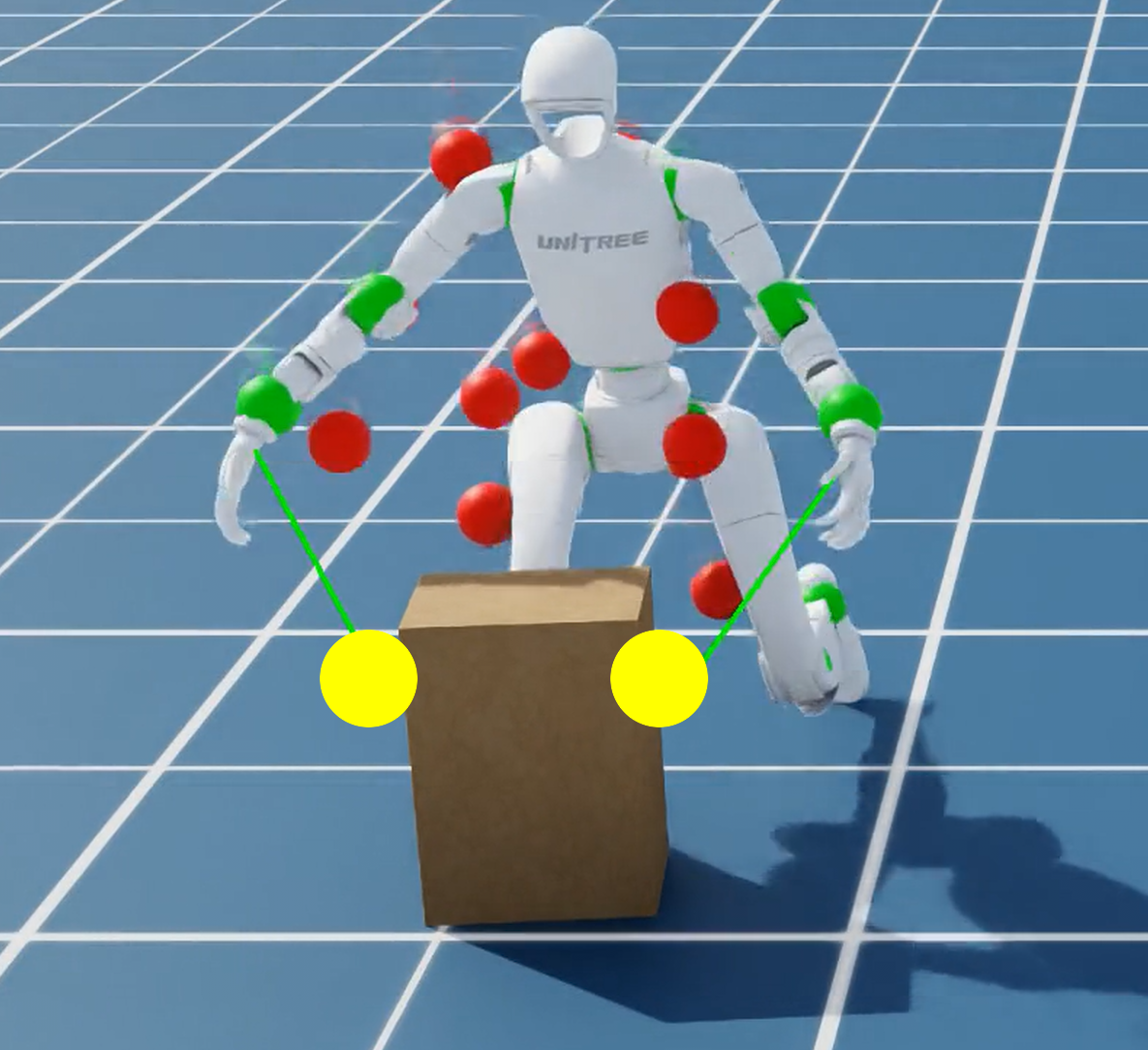
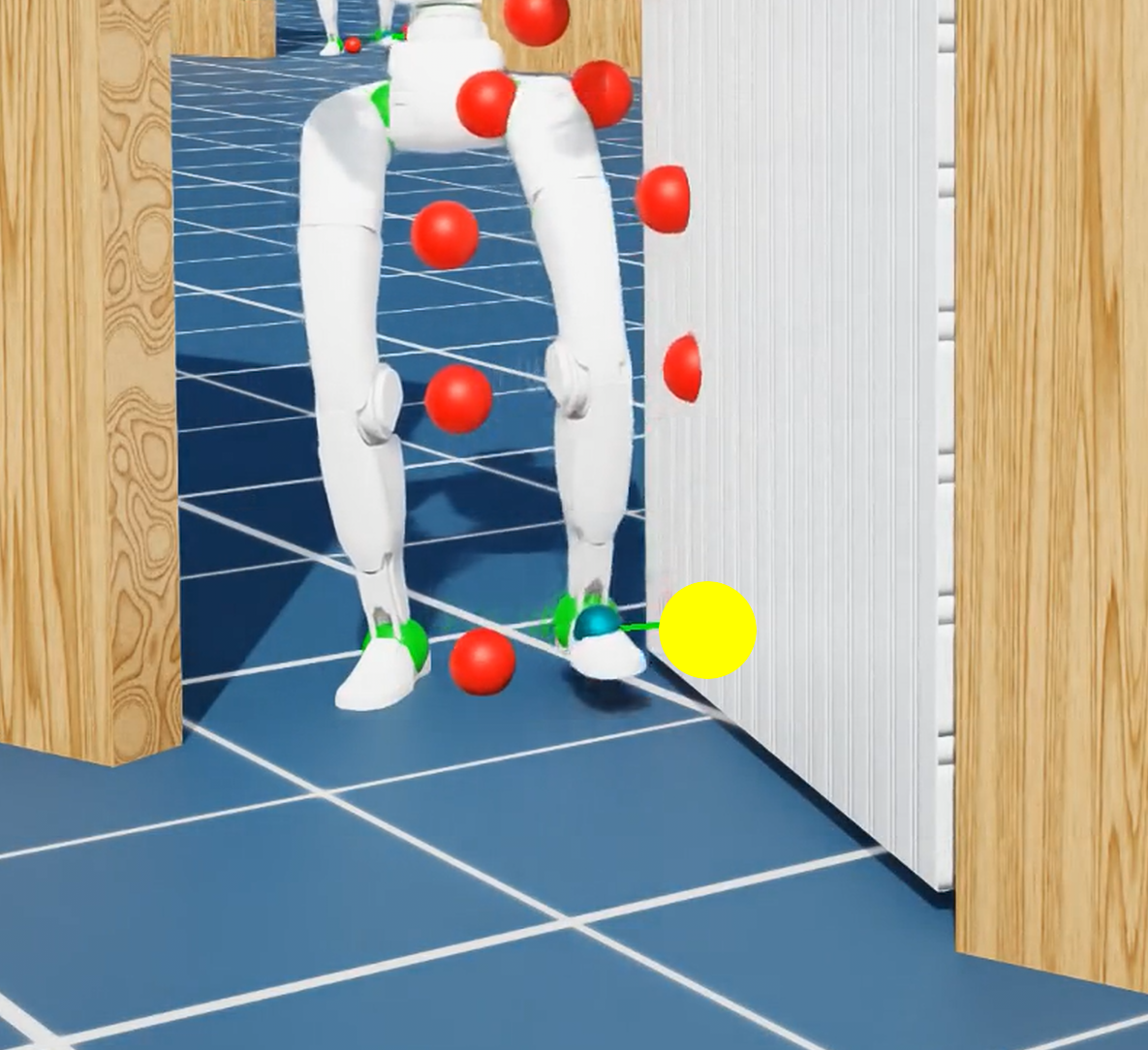
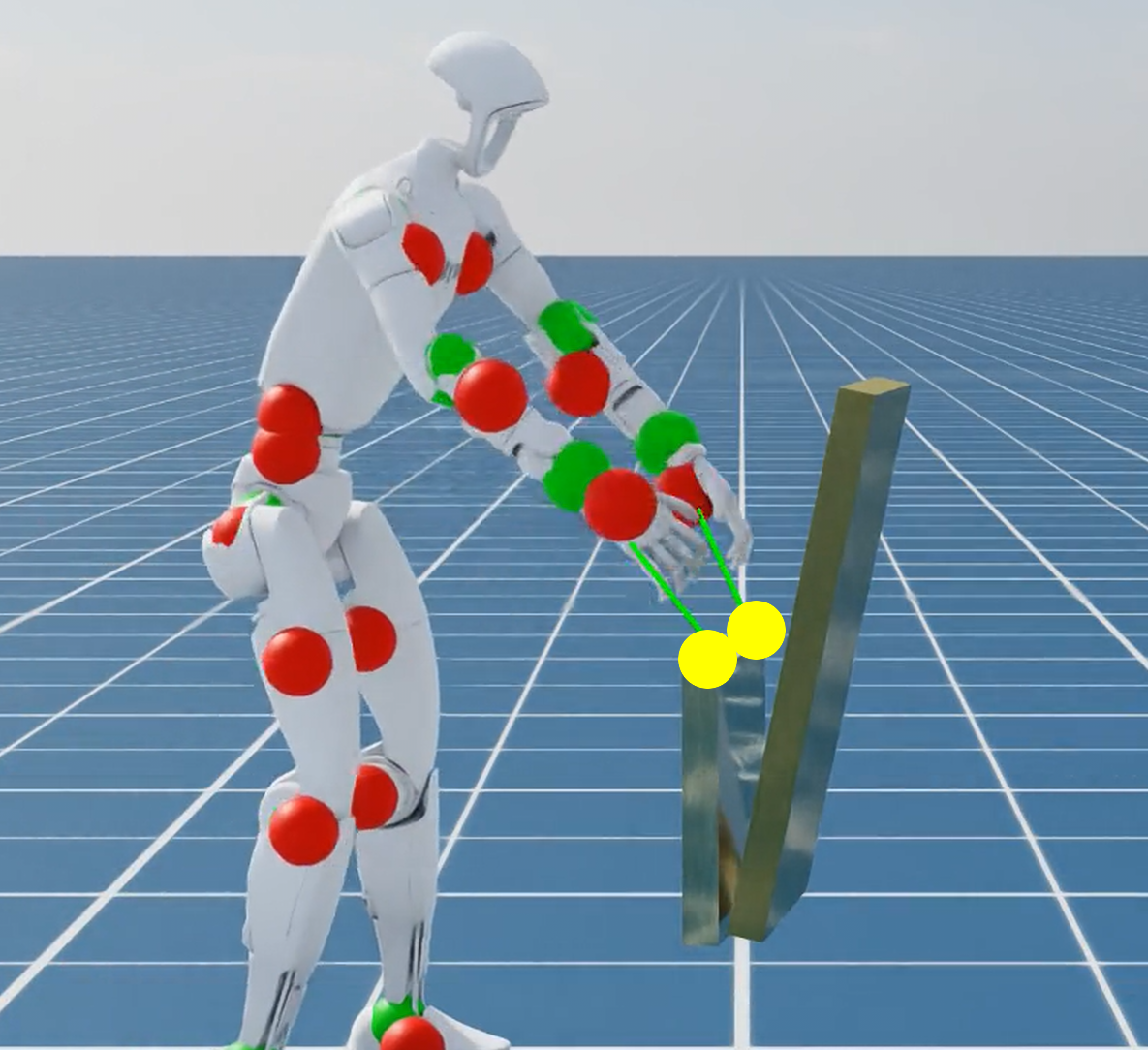
Figure 2: Reference contact position (yellow dot) in three different tasks. Policy observes these during training and deployment.
Residual Action Space
The use of a residual action space is critical for learning challenging poses such as kneeling. Instead of absolute joint targets, the policy learns offsets from reference poses, anchoring initial exploration and significantly improving training efficiency and convergence speed.
Interaction Reward
To compensate for the inherent limitations of kinematic reference trajectories, which may lack precise contact dynamics, HDMI introduces an interaction reward that incentivizes proper contact maintenance. This reward is crucial for ensuring task performance when dealing with imperfect motion references.
Real-World Evaluation
The effectiveness of HDMI is validated through a series of real-world experiments on challenging tasks such as door traversal and box locomotion. The framework demonstrated the ability to:
Simulation Ablations
Comprehensive ablation studies underscore the importance of HDMI's core components. Interaction rewards and residual action spaces are shown to be essential for handling imperfect reference motions and improving exploration stability.
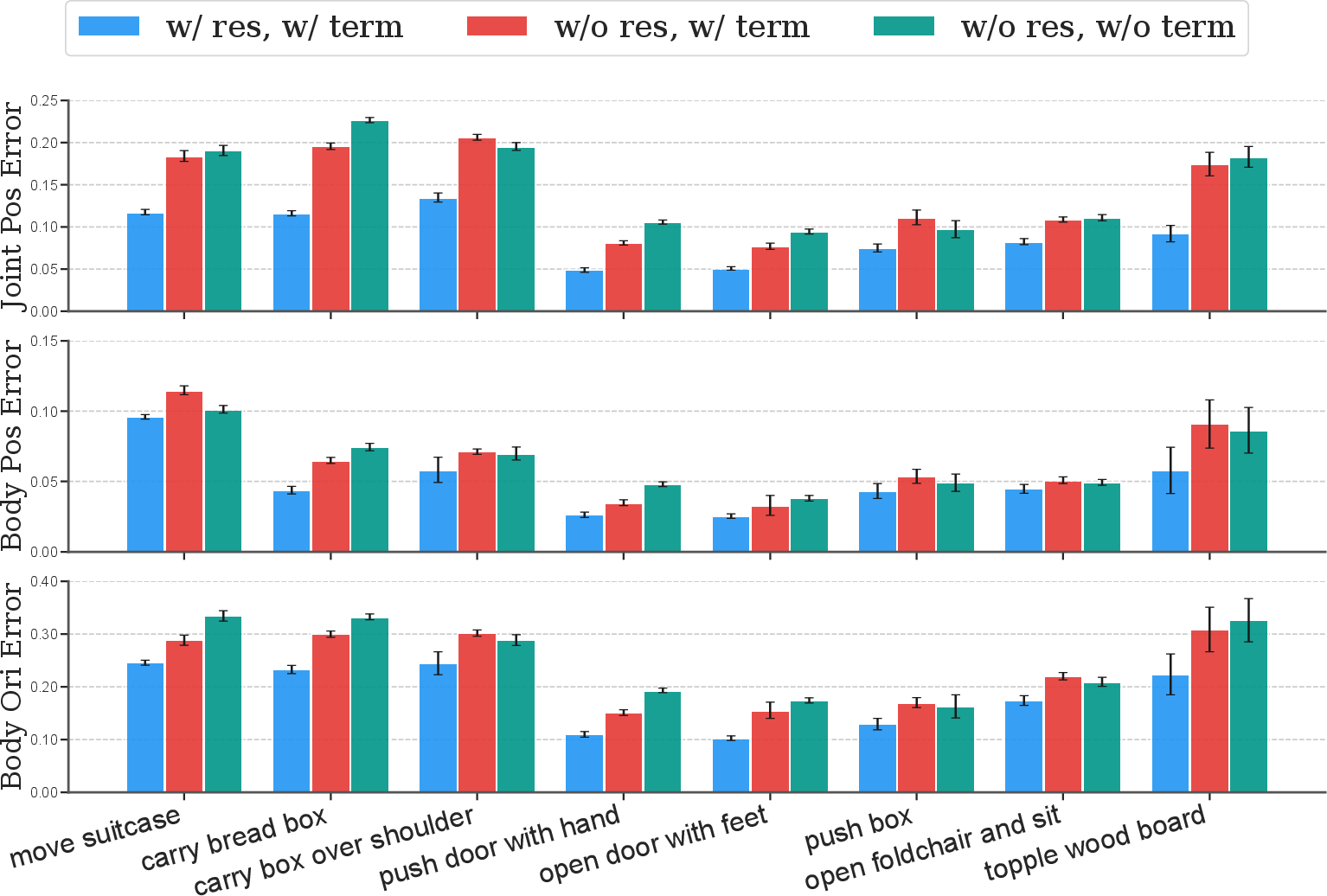
Figure 4: Final success rate across 8 tasks, highlighting the critical role of interaction reward and contact-based termination.
Conclusion and Future Directions
The HDMI framework marks a significant advancement in enabling humanoids to learn complex interaction skills from RGB videos. Looking ahead, future work will aim to reduce the reliance on motion capture and explore the development of generalized models capable of handling multiple interaction tasks with a single policy. This would enhance the robot’s adaptability in real-world, uninstrumented environments and broaden the framework's applicability in practical settings.
The research offers promising avenues for integrative humanoid control, laying the groundwork for deploying robust interactive humanoids in dynamic human environments.
