- The paper introduces a decentralized training method that partitions data into semantic clusters to train independent diffusion experts.
- It employs a multi-expert architecture with Diffusion Transformers and a router that dynamically selects the most appropriate expert during inference.
- The approach achieves competitive performance with reduced compute and data requirements, enabling asynchronous training on heterogeneous hardware.
Paris: A Decentralized Trained Open-Weight Diffusion Model
Introduction
The Paris model introduces a fully decentralized approach to training large-scale text-to-image diffusion models, eliminating the need for synchronized gradient updates and specialized interconnects. By partitioning the training data into semantically coherent clusters and training independent expert models on each partition, Paris demonstrates that high-quality generative performance is achievable without centralized infrastructure. This paradigm shift enables training on heterogeneous, geographically distributed hardware, significantly lowering the barrier to entry for large-scale diffusion modeling.










Figure 1: Text conditioned image generation samples using Paris.
Distributed Diffusion Training Framework
Paris leverages a multi-expert architecture, where each expert is a Diffusion Transformer (DiT) trained in complete isolation on a distinct data cluster. The training pipeline consists of the following steps:
- Latent Encoding: Images are encoded into a latent space using a pretrained VAE, reducing computational requirements.
- Semantic Clustering: DINOv2 embeddings are used to partition the dataset into K clusters, each representing a distinct semantic domain.
- Expert Training: Each expert model is trained independently on its assigned cluster, optimizing a flow matching objective without any inter-expert communication.
- Router Training: A lightweight transformer-based router is trained post-hoc to dynamically select the most appropriate expert(s) during inference.
This framework is grounded in decentralized flow matching theory, allowing the global generative distribution to be approximated by the ensemble of locally optimized experts.
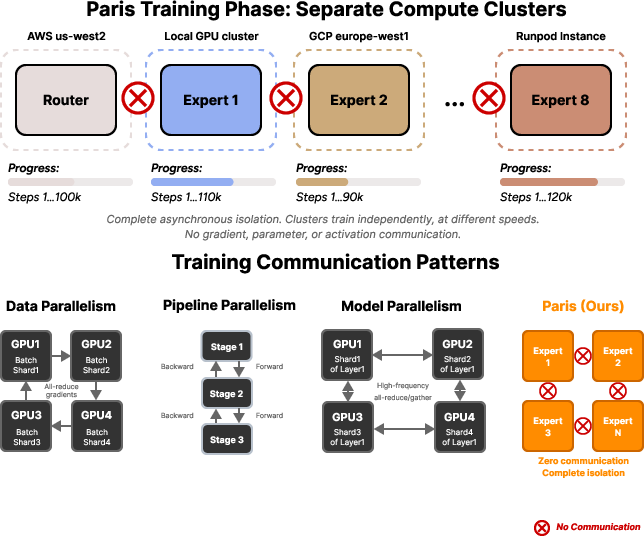
Figure 2: Multi-expert training pipeline of Paris.
Model Architecture
DiTExpert
Each expert in Paris is based on the Diffusion Transformer architecture, adapted for decentralized training. Key architectural features include:
- Latent Diffusion: Operates on 32×32×4 latent tensors, following the latent diffusion paradigm.
- Transformer Blocks: Incorporate Adaptive Layer Normalization (AdaLN) for timestep conditioning, with optional AdaLN-Single for parameter efficiency.
- Text Conditioning: Cross-attention layers enable text-to-image synthesis, using CLIP embeddings projected to the model's hidden dimension.
- Scalability: DiTExpert models are validated at two scales—DiT-B/2 (129M parameters per expert) and DiT-XL/2 (605M parameters per expert).
DiTRouter
The router is a smaller Diffusion Transformer variant, designed to process noisy latents and predict the most suitable expert(s) for each denoising step. It incorporates timestep-aware processing and is trained using cross-entropy loss against ground-truth cluster assignments.
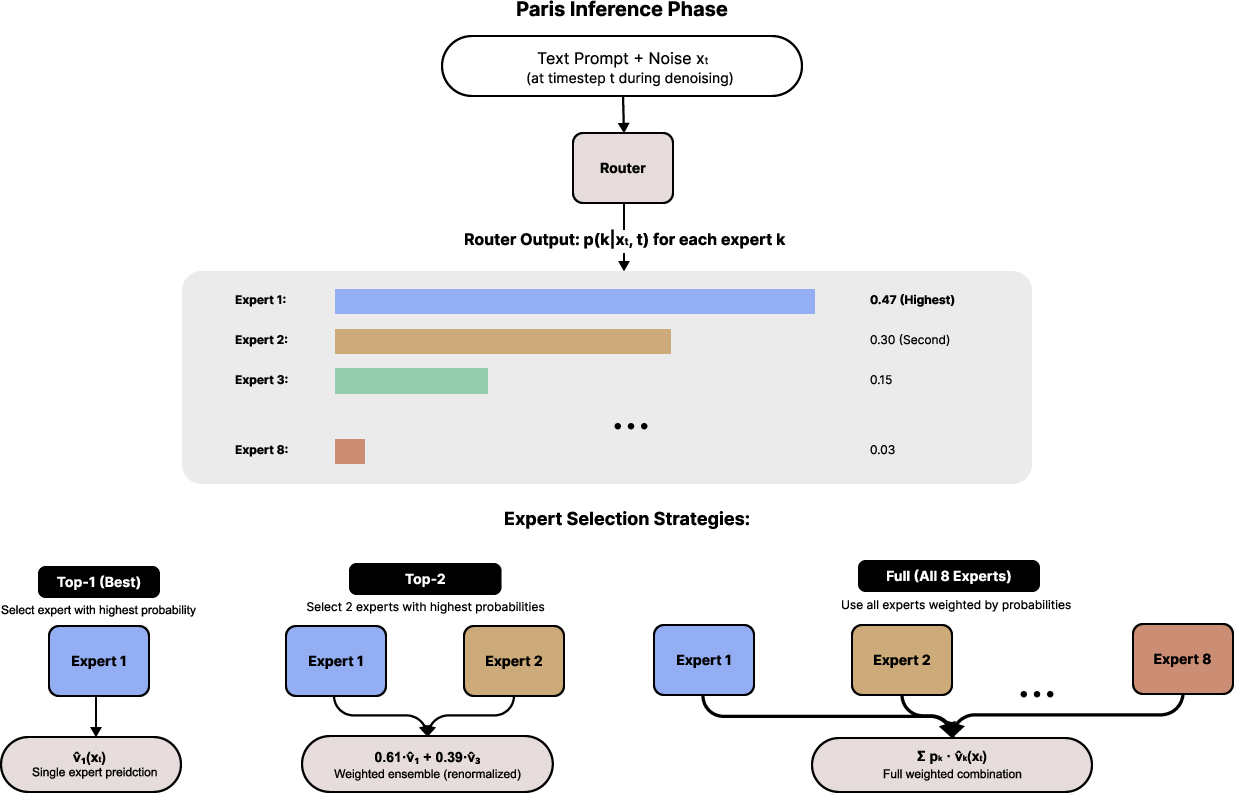
Figure 3: Multi-expert inference pipeline of Paris.
Decentralized Flow Matching Objective
The decentralized training objective decomposes the standard flow matching loss across K experts, each optimizing:
Lexpert(k)=Ex0∈Sk,t[∥vθk(xt,t)−(x0−xt)∥2]
where Sk is the data cluster for expert k, vθk is the predicted velocity field, and xt is the noisy latent at timestep t. The router learns to approximate the posterior pt(k∣xt), enabling dynamic expert selection during inference.
Inference Strategies
Paris supports several inference strategies:
- Top-1 Expert Selection: Routes each denoising step to the single most confident expert, offering computational efficiency and strong empirical performance.
- Top-K Weighted Ensemble: Combines predictions from the K′ most relevant experts, weighted by router probabilities, balancing quality and cost.
- Full Ensemble Integration: Aggregates all expert predictions, weighted by router probabilities; however, this approach often yields inferior results due to interference from less-relevant experts.
Empirical results indicate that selective expert collaboration (Top-2) outperforms both monolithic and full ensemble approaches.
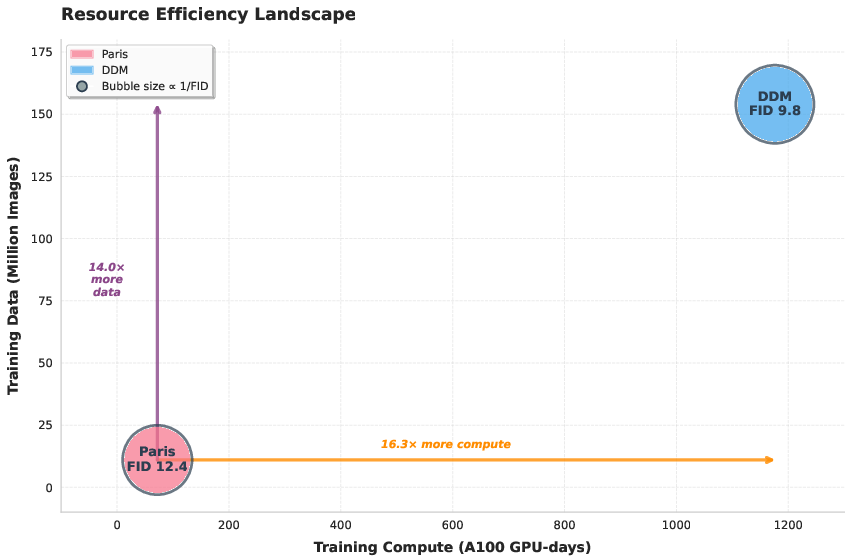
Resource Efficiency and Parallelization
Paris's decentralized training eliminates all synchronization overhead, enabling asynchronous training on heterogeneous hardware. Unlike traditional data, model, or pipeline parallelism, Paris experts train independently, with no blocking or topology constraints. This allows for efficient utilization of commodity GPUs and fragmented compute resources.
Experimental Results
Paris achieves competitive generation quality with dramatically reduced resource requirements:
Practical and Theoretical Implications
Paris demonstrates that decentralized training is a viable alternative to centralized approaches for large-scale generative modeling. The elimination of synchronization requirements enables broader participation in model development, democratizing access to high-quality diffusion models. The modular expert architecture facilitates specialization and extensibility, while the router enables dynamic, noise-aware expert selection.
The modest quality gap relative to centralized baselines suggests that further optimization—such as improved clustering, expert distillation, or advanced routing mechanisms—could close the performance gap while retaining resource efficiency. The framework is readily extensible to other modalities (e.g., video, audio) and supports future research in scalable, decentralized generative modeling.
Conclusion
Paris establishes a practical blueprint for fully decentralized diffusion model training, achieving competitive text-to-image synthesis with dramatically reduced data and compute requirements. The multi-expert architecture, combined with dynamic routing, enables efficient, high-quality generation on heterogeneous hardware. This work paves the way for scalable, democratized generative modeling and invites further exploration into decentralized architectures, expert specialization, and cross-modal extensions.