Predictive Preference Learning from Human Interventions
Abstract: Learning from human involvement aims to incorporate the human subject to monitor and correct agent behavior errors. Although most interactive imitation learning methods focus on correcting the agent's action at the current state, they do not adjust its actions in future states, which may be potentially more hazardous. To address this, we introduce Predictive Preference Learning from Human Interventions (PPL), which leverages the implicit preference signals contained in human interventions to inform predictions of future rollouts. The key idea of PPL is to bootstrap each human intervention into L future time steps, called the preference horizon, with the assumption that the agent follows the same action and the human makes the same intervention in the preference horizon. By applying preference optimization on these future states, expert corrections are propagated into the safety-critical regions where the agent is expected to explore, significantly improving learning efficiency and reducing human demonstrations needed. We evaluate our approach with experiments on both autonomous driving and robotic manipulation benchmarks and demonstrate its efficiency and generality. Our theoretical analysis further shows that selecting an appropriate preference horizon L balances coverage of risky states with label correctness, thereby bounding the algorithmic optimality gap. Demo and code are available at: https://metadriverse.github.io/ppl

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-Language Summary of “Predictive Preference Learning from Human Interventions”
Overview
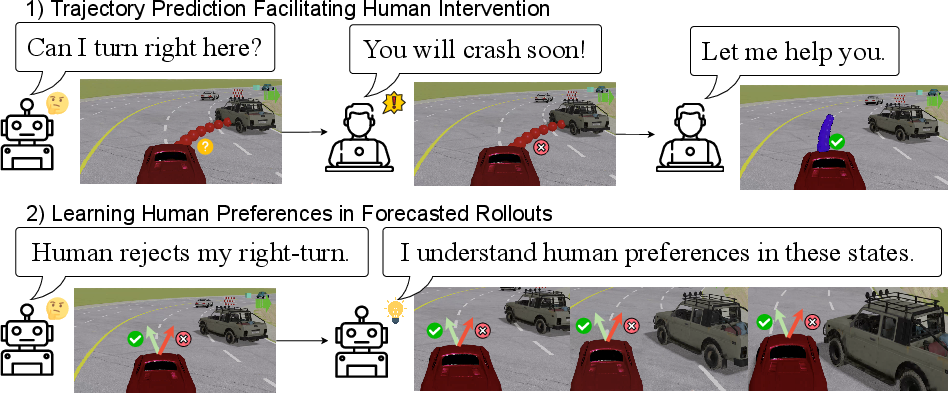
This paper is about teaching robots and self-driving cars to act safely and smartly by learning from people. Instead of waiting for a robot to make a mistake and then fixing it, the method predicts what the robot is about to do, shows that future path to a human, and learns from the human’s quick correction. The idea is to turn one human correction into many small lessons about what to do next, so the robot needs fewer corrections overall and learns faster.
Key Questions the Paper Tries to Answer
- How can we reduce the number of times a human needs to step in and fix the robot during training?
- Can we teach a robot to avoid dangerous situations before it gets into them?
- How do we make the robot learn not just what to do now, but also what to do in the next few moments?
- How long should the robot “remember” a correction into the future to learn best?
How the Method Works (Explained Simply)
Think of the robot like a beginner driver with a coach in the passenger seat.
- Predicting the future: Before the robot acts, it quickly “imagines” its next few steps (like a short GPS preview of where it’s heading). This preview is shown to a human.
- Human steps in early: If the preview looks risky (like heading toward a crash), the human takes control right away and shows the safe action.
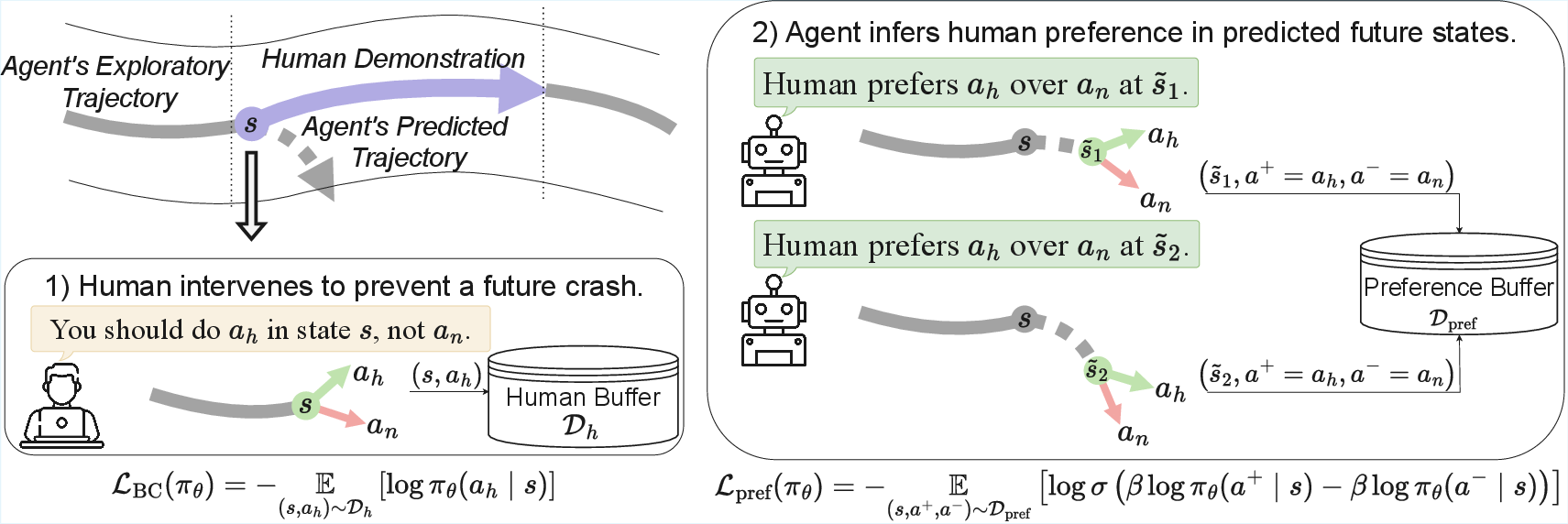
- Turning one correction into many lessons: That one correction is treated as a strong hint not just for the current moment, but also for the next few predicted moments. The method assumes that, for a short window into the future (called the preference horizon L), the safe action is better than the risky one.
- Learning from preferences: The robot is trained to “prefer” the human’s safer choice over its own unsafe choice in those predicted future states. You can think of it like giving the robot a series of thumbs-up for the safe option and thumbs-down for the unsafe one in each of those predicted steps.
- Two ways it learns at the same time:
- Behavior Cloning: Copy the human’s action when the human takes control.
- Preference Learning: In predicted future states, learn to favor the human’s kind of action over the robot’s original action.
About that horizon L: If L is too short, the robot won’t learn enough about upcoming risky places. If L is too long, the “imagined” future becomes less accurate, and the advice might not fit those states well. So picking L is a trade-off.
In more technical terms (lightweight):
- This approach sits in interactive imitation learning: the robot learns from a human coach during training.
- It uses a fast trajectory predictor to show likely future states.
- It converts human interventions into “contrastive preferences” (safe action better than unsafe action) over the next L predicted states.
- It combines a simple “copy the expert” loss with a “prefer safe over unsafe” loss to train the policy.
Main Findings and Why They Matter
From tests in driving and robot-arm tasks:
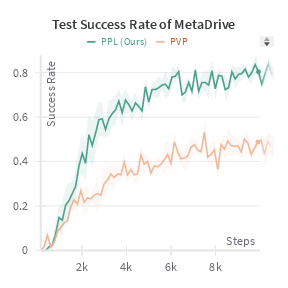
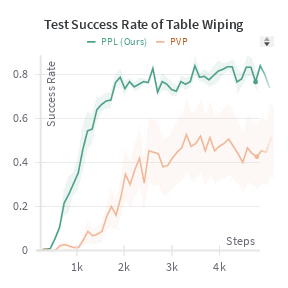
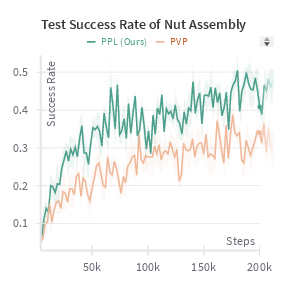
- Fewer human interventions needed: The robot learns faster and requires less human effort because it learns from predicted future mistakes, not just current ones.
- Better performance with less data: It succeeds more often on test tasks than several existing methods that also involve humans.
- Robust to imperfect predictions: Even when the future predictions are a bit noisy, the method still works well.
- The horizon matters: A medium-length preference horizon (for example, L around 4 steps in their driving tests) worked best—long enough to cover risky areas, short enough to keep labels accurate.
- Smoother, safer behavior: The learned control (like steering) becomes smoother and more human-like, especially near obstacles.
Why this is important:
- Safety: The robot avoids dangerous situations earlier.
- Efficiency: Humans don’t have to watch every moment or constantly jump in; one correction teaches many lessons.
- Practicality: It works across different tasks (driving and robot manipulation) and doesn’t require designing complicated reward functions.
What This Could Mean Going Forward
- Training real-world robots and self-driving systems could become safer, cheaper, and faster because humans won’t need to provide as many demonstrations.
- The idea of learning from predicted futures could be combined with other training methods to further reduce risks.
- Picking the right future horizon L is a key design choice—future systems could learn to adjust L automatically.
Limitations and Future Work
- Assumes the human’s correction is good: If the human makes mistakes or is inconsistent, learning can suffer.
- Mostly tested in simulation: Real-world trials (with real cars or robots) are still needed to confirm safety and reliability.
- Needs a quick prediction model: If predictions are very wrong, the benefits decrease, though the method showed some robustness to noise.
In short: This paper shows a smart way to use one human correction to teach a robot many small lessons about the near future, leading to safer and more efficient learning with less human effort.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed as actionable directions for future research.
- Lack of real-world validation: All experiments are in simulation; the safety, reliability, latency, and human-in-the-loop feasibility of deploying PPL on physical robots or real vehicles remain untested.
- Assumption of optimal, consistent expert behavior: The method and theory assume the expert always knows and executes the optimal corrective action; robustness to suboptimal, noisy, delayed, or inconsistent human interventions is not analyzed.
- Static takeover window: Interventions control the agent for a fixed H steps; the effects of variable-length, partial, or intermittent takeovers (and how to model or learn them) are not studied.
- Cross-state action labeling assumption: Preference pairs assign the current corrective action a_h to predicted future states s̃i; how to mitigate the mismatch when the optimal corrective action changes with state (beyond tuning L) is not addressed.
- No mechanism to learn corrective actions for imagined future states: The method does not infer a human policy conditioned on s̃i; learning a state-conditional model of “what the expert would do at s̃i” is left unexplored.
- Choice of preference horizon L is manual: There is no principled, adaptive procedure to choose L based on predictor uncertainty, state novelty, or label quality; formal dependence of δpref and δdist on L is not quantified.
- Theory leaves key quantities uninstantiated: The bound relies on δpref and δdist (TV distances) that are hard to estimate; no practical estimators or regularizers are provided to control these terms during training.
- Loose or restrictive theoretical assumptions: The analysis requires bounded Q* differences and “small enough” β; the tightness, necessity, and practical verification of these assumptions are unclear.
- No finite-sample or sample-complexity guarantees: The theory is asymptotic in flavor and does not relate dataset size, intervention frequency, or predictor error to performance with finite data.
- Predictor assumptions are unrealistic in multi-agent domains: The driving predictor treats other agents as stationary and applies the same action a_n repeatedly; effects of interactive dynamics, reaction of others, and closed-loop mismatch are not addressed.
- Predictor is not learned or adapted: There is no joint learning of the trajectory predictor, no calibration of its uncertainty, and no active improvement of the predictor in regions where PPL relies on it most.
- Limited robustness analysis of predictor errors: Noise is injected into predicted states, but structured errors (e.g., biased dynamics, delayed forecasts, multi-agent mispredictions) and their impact on safety and label correctness are not evaluated.
- Safety guarantees are absent: There is no formal guarantee on constraint satisfaction, intervention frequency bounds, or safe-set invariance under prediction errors or incorrect preference propagation.
- Cognitive load not directly measured: Claims of reduced cognitive burden are proxied by intervention counts; user studies (e.g., NASA-TLX), learning curves with/without rollout visualization, and timing/attention metrics are missing.
- Preference data is intervention-triggered only: The method collects preferences only when the expert intervenes; the value of also collecting approvals (positive labels when no intervention is needed) or active querying is unexplored.
- Bias in preference dataset: D is concentrated near unsafe or near-intervention states; how this bias affects generalization to nominal states, and methods to debias or reweight D, are not explored.
- Loss design and weighting: The combined BC + CPO objective lacks analysis of gradient conflicts, loss weighting schedules, or stability; sensitivity to β and any BC/CPO weighting hyperparameters is not studied.
- Limited comparison across preference-learning objectives: Only a few alternatives (DPO/IPO/SLiC-HF) are tried; no analysis of when each is preferable, or how to leverage a learned reward model vs direct policy optimization.
- No adaptive intervention policy modeling: I(s, a_n) is deterministic and immediate; modeling human reaction times, missed detections, false positives, or heterogeneous expert policies is not considered.
- Fixed prediction horizon H: Sensitivity to H (distinct from L) and trade-offs between frequency of visualization, compute, human reaction time, and labeling quality are not analyzed.
- Observation modality constraints: All policies use low-dimensional state vectors; scalability to high-dimensional sensory inputs (e.g., vision, LiDAR) and the effect on prediction, preference labeling, and runtime are untested.
- Inter-expert variability and aggregation: The approach is not evaluated with multiple humans, and methods for aggregating inconsistent preferences or reconciling stylistic differences are absent.
- Non-Markovian preferences: Human preferences may depend on trajectory history or intent; the method labels only state-action pairs and does not model temporally extended preferences.
- Real-time systems considerations: End-to-end latency (prediction, visualization, human response, control handoff) and failure modes under communication delays or dropped frames are not characterized.
- Generalization scope: Tasks are limited in diversity; transfer to more complex, long-horizon, multi-stage tasks, or to settings with combinatorial action spaces, is not demonstrated.
- Intervention criteria in proxy-human experiments: Neural “experts” use reward or rule thresholds to decide interventions; how closely these criteria approximate real human preferences and how this affects conclusions is unclear.
- Handling incorrect interventions: The effect of occasional harmful or adversarial interventions on learned preferences and safety is not explored; no mechanisms for outlier detection, preference revision, or rollback exist.
- Data management and replay: The paper does not specify sampling strategies, balancing of D vs Dh over time, or how to handle duplication/ageing of labels; curriculum or prioritization strategies are unexplored.
- Multi-objective or risk-sensitive preferences: Preferences beyond “avoid failure” (comfort, efficiency, fairness, risk aversion) are not modeled; extending PPL to handle multi-criteria or constraint-aware preferences remains open.
- Integration with other IIL/RL paradigms: Combining PPL with confidence-based querying, shielded control, or model-based planning to further reduce interventions and improve safety is not studied.
Practical Applications
Immediate Applications
Below are actionable uses that can be deployed today or with minimal engineering, drawing on this paper’s Predictive Preference Learning from Human Interventions (PPL) workflow, models, and theory.
- Autonomous driving R&D: training and safety-oversight tooling
- Sector: automotive software, robotics
- What: Integrate short-horizon trajectory visualization and preference bootstrapping into AV training loops in simulation; convert safety driver (or neural expert) takeovers into contrastive preferences, train with BC + CPO to reduce interventions and improve sample efficiency.
- Tools/products/workflows:
- Dev dashboard showing predicted rollouts (H-step) in sim (e.g., MetaDrive, CARLA), with one-click takeover that auto-logs (s, a_h, a_n) and generates L-horizon preference tuples.
- Training pipeline with CPO loss + BC regularization; kinematic bicycle predictor for real-time inference; intervention analytics (takeover rate, route completion).
- Assumptions/dependencies: Reliable short-horizon predictor (H≈10) in sim or simple rule-based vehicle model; human supervisor availability; safety cages in sim; choice of preference horizon L calibrated (e.g., 3–6) to balance coverage vs. label drift.
- Industrial robot teaching in simulation
- Sector: manufacturing robotics
- What: Speed up policy acquisition for table-wiping, pick-place, nut assembly by visualizing predicted end-effector trajectories and converting operator takeovers into preference labels across predicted states.
- Tools/products/workflows:
- Robosuite/Isaac Sim plugins that render predicted rollouts and capture interventions; auto-generate preference datasets; training with BC + CPO.
- Assumptions/dependencies: Accurate simulator dynamics for short rollouts; task-appropriate H and L; operator can provide corrective action consistently.
- Warehouse/mobile robot navigation prototyping
- Sector: logistics robotics
- What: Use PPL during navigation policy development to reduce crashes in narrow aisles and dynamic scenes by visualizing risky forecasted paths and propagating preferences to future states.
- Tools/products/workflows: Lightweight 2D/SE(2) motion model predictor; UI overlay in RViz/WebUI; preference logging service + training job that periodically refits policy.
- Assumptions/dependencies: Short-horizon motion models adequate for local planning; reliable human overseer; synthetic crowd models in sim.
- Human-in-the-loop teleoperation training
- Sector: robotics software
- What: During teleop sessions, automatically transform operator overrides into preference pairs on predicted rollouts to gradually reduce intervention frequency.
- Tools/products/workflows: Teleop UI (gamepad/keyboard) with predicted path overlay; background trainer running CPO updates; intervention rate as KPI.
- Assumptions/dependencies: Low-latency UI; logging infrastructure; stable teleop mapping from UI to actions.
- Preference dataset creation for control
- Sector: academia, ML tooling
- What: Generate D_PO-like datasets for control (states plus positive/negative actions) at scale without exhaustive pairwise annotations, leveraging interventions + trajectory prediction.
- Tools/products/workflows: Data schemas for (s, a_h, a_n, rollout snippets), scripts to export to DPO/CPO/IPO formats; shared benchmarks (MetaDrive, Robosuite).
- Assumptions/dependencies: Licensing for environments; consistent intervention rules; reproducible seeds.
- Human-factors studies on cognitive load
- Sector: academia (HRI, HCI)
- What: Evaluate how rollout visualization reduces supervisor burden and improves timing/quality of interventions versus baseline IIL in lab user studies.
- Tools/products/workflows: Experiment protocols, metrics (intervention latency, error rate), ablation on presence/absence of forecast overlays and different L.
- Assumptions/dependencies: IRB approval; participant cohort; standardized tasks.
- Internal safety governance for labs/companies
- Sector: policy within organizations
- What: Adopt internal best practices that require predictive visualization during human-in-the-loop training and track metrics like intervention rate and distribution shift between training and preference states.
- Tools/products/workflows: Safety checklists; dashboards tracking δ_dist, takeover rate, near-miss counts; guidance for selecting L based on observed label drift.
- Assumptions/dependencies: Ability to instrument training runs; simple estimators for distribution shift and label noise.
- Education and training
- Sector: education
- What: Course modules and assignments demonstrating how to adapt RLHF-style objectives (CPO/DPO) to control with trajectory predictors and interventions.
- Tools/products/workflows: Open-source notebooks, starter code, small lab tasks (e.g., cartpole with rollout visualization).
- Assumptions/dependencies: Access to GPUs/CPUs; student familiarity with IL/RL.
Long-Term Applications
These opportunities require further research, robustification, scaling, or regulatory alignment before widespread deployment.
- On-road AV learning with safety drivers
- Sector: automotive
- What: Use predictive overlays in real vehicles to preempt unsafe maneuvers, and convert safety driver interventions into preference signals that propagate across likely future states.
- Tools/products/workflows: In-cabin supervisor UI; certified short-horizon predictors incorporating other actors; fleet-scale preference logging and periodic policy updates.
- Assumptions/dependencies: Regulatory approval; strong model-based or learned predictors for multi-agent traffic; rigorous safety cases; privacy-preserving data pipeline; online/offline validation gates.
- Collaborative robots (cobots) learning from line operators
- Sector: manufacturing
- What: Operators correct robot motions when predicted paths risk collisions or ergonomic violations; preferences propagate to similar future contexts, reducing teaching time.
- Tools/products/workflows: AR overlays on teach pendants; standards-compliant safety interlocks; preference horizon scheduling based on task phase.
- Assumptions/dependencies: ISO/IEC safety compliance; accurate human/obstacle tracking for predictions; explainability of learned preferences.
- Healthcare and surgical robotics
- Sector: healthcare
- What: Surgeons’ micro-corrections during simulated procedures become high-value preferences to guide autonomous assistance in instrument positioning and retraction.
- Tools/products/workflows: High-fidelity patient/task simulators; credentialed training loops; preference uncertainty quantification.
- Assumptions/dependencies: Extremely reliable predictors; clinical validation; liability frameworks; robust handling of suboptimal/noisy human inputs.
- UAVs and aerial swarms
- Sector: aerospace/defense
- What: Ground pilots use predictive previews to shape swarm behavior via sparse interventions; preferences propagate across multi-vehicle futures.
- Tools/products/workflows: Multi-agent predictors; deconfliction-aware preference generation; mission-time adaptation.
- Assumptions/dependencies: Scalable prediction for many agents; comms latency constraints; safety in GNSS-denied or windy conditions.
- Assistive mobility and personal robotics
- Sector: consumer robotics, accessibility
- What: Power wheelchairs and home robots show near-term planned motions; user nudges become preferences that tailor navigation and manipulation styles to household norms.
- Tools/products/workflows: Mobile UI with clear planned path; preference profiles per user/environment; safe incremental policy updates.
- Assumptions/dependencies: Robust perception in clutter; intuitive UIs; strong on-device safety layers; guardrails against preference misgeneralization.
- Smart appliances and domestic autonomy
- Sector: consumer electronics
- What: Robot vacuums/lawn mowers preview planned coverage; user corrections translate into preferences (e.g., avoid rugs, follow edges) propagated across similar future states.
- Tools/products/workflows: Lightweight onboard predictors; episodic PPL updates; homeowner-friendly calibration of L via simple sliders.
- Assumptions/dependencies: Edge compute limits; map reliability; safe failure modes.
- Standardization and certification of preference-based training for control
- Sector: policy/regulation
- What: Develop standards for logging, auditing, and validating preference data and predictors, including recommended ranges for L and reporting of label-quality/shift metrics.
- Tools/products/workflows: Conformance test suites; third-party audits; standardized telemetry schemas for interventions and predicted rollouts.
- Assumptions/dependencies: Consensus on metrics (δ_dist, δ_pref); stakeholder alignment; integration with existing safety standards (e.g., ISO 26262, ISO 13482).
- Cross-domain embodied AI preference learning
- Sector: general-purpose AI/robotics
- What: Unify language-model RLHF and control PPL into multi-modal agents that learn consistent user preferences across dialogue and physical actions, using imagined futures for both.
- Tools/products/workflows: Joint predictors over language plans and motion; hierarchical preference propagation from high-level intent to low-level control.
- Assumptions/dependencies: Reliable multi-modal prediction; scalable data/compute; strong safeguards for out-of-distribution generalization.
- Developer platforms for predictive preference learning
- Sector: software tooling
- What: IDE-like environments for embodied agents: live rollout previews, one-click intervention-to-preference pipelines, horizon tuning assistants, label-noise diagnostics.
- Tools/products/workflows: SDKs for CPO/DPO training loops; plug-ins for simulators (Isaac, Gazebo, Webots); fleet experiment management.
- Assumptions/dependencies: Broad simulator support; ergonomic UIs; enterprise integration (data governance, MLOps).
- Safety analytics and oversight frameworks
- Sector: policy, compliance
- What: Organizational policies that require predictive visualization during training, quantitative monitoring of intervention rates and distribution shift, and gates based on theoretical bounds before deployment.
- Tools/products/workflows: Reports with empirical δ_dist, δ_pref proxies; risk dashboards; auto-alerting when horizons degrade label quality.
- Assumptions/dependencies: Validated proxies for theoretical terms; change-management processes; datasets for periodic re-evaluation.
Notes on common assumptions and dependencies across applications:
- Corrective-action consistency: PPL assumes the corrective action a_h at the current state remains a good proxy over the preference horizon L; choosing L too large increases label drift (δ_pref).
- Predictor fidelity: Short-horizon rollouts must be accurate enough to reveal imminent risks; noise degrades performance but PPL shows robustness up to moderate noise in experiments.
- Human expertise and availability: Supervisors must recognize unsafe forecasts and provide timely takeovers; UI design affects cognitive load.
- Safety scaffolding: Real-world deployment requires hard safety constraints independent of learned policy (e.g., geofencing, emergency stop).
- Compute and latency: Real-time prediction and visualization require high-fps models (rule-based or learned) and efficient logging/training loops.
- Transfer from simulation to reality: Sim2real gaps necessitate careful validation and possibly domain randomization or hybrid model-based predictors.
Glossary
- Algorithmic optimality gap: The difference in performance between the learned algorithm and the optimal policy. "selecting an appropriate preference horizon balances coverage of risky states with label correctness, thereby bounding the algorithmic optimality gap."
- Behavioral Cloning (BC): Supervised imitation of expert actions by directly learning a policy to map states to expert actions. "We test two imitation learning baselines: Behavior Cloning (BC) and GAIL~\citep{ho2016generative}."
- Contrastive Preference Optimization (CPO): A preference-based objective that trains policies via a contrastive classification loss over preferred versus dispreferred actions. "The Contrastive Preference Optimization method~\citep{xu2024contrastive} uses the following objective to train an agent policy from the preference dataset ."
- Deterministic intervention policy: A rule that deterministically specifies whether a human takes over given the current state and agent action. "We use the deterministic intervention policy to model the human's intervention behavior."
- Direct Preference Optimization (DPO): A preference-learning approach that directly optimizes the policy to satisfy human preferences without an explicit reward model. "Alternatively, methods such as Direct Preference Optimization (DPO)~\citep{rafailov2023direct}, Contrastive Preference Optimization (CPO)~\citep{xu2024contrastive}, and related variants~\citep{azar2024general, meng2024simpo} bypass explicit reward-model training..."
- Discount factor: A scalar in (0,1) that geometrically weights future rewards in RL objectives. "a discount factor "
- Discounted state distribution: The distribution over states visited by a policy, weighted by the discount factor across time. "We also define the discounted state distribution under policy as $d_{\pi_n}(s) = (1 - \gamma) \limits_{\tau\sim P_{\pi_n}[ \sum\limits_{t=0}^{\infty} \gamma^t \mathbb{I}[s_t = s]].$"
- Distributional shift: A change in the state-action distribution between training data and deployment, often harming imitation performance. "IL agents are susceptible to distributional shift because the offline dataset may lack corrective samples in safety-critical or out-of-distribution states~\citep{ross2010efficient, ravichandar2020recent, chernova2022robot, zare2024survey}."
- EGPO: An interactive learning method that designs proxy costs to reduce human interventions. "EGPO~\citep{peng2021safe}, PVP~\citep{peng2024learning}, and AIM~\citep{cai2025robot} design proxy cost or value functions to suppress the frequency of human involvement."
- Ensemble-DAgger: A variant of DAgger that uses ensemble uncertainty to request demonstrations during training. "Ensemble-DAgger~\citep{menda2019ensembledagger}"
- Expert Intervention Learning (EIL): An IIL method that learns from expert interventions to correct agent behavior. "Expert Intervention Learning (EIL)~\citep{spencer2020learning}"
- Generative Adversarial Imitation Learning (GAIL): An imitation method that trains policies adversarially to match expert behavior. "We test two imitation learning baselines: Behavior Cloning (BC) and GAIL~\citep{ho2016generative}."
- Human-AI Copilot Optimization (HACO): An IIL approach where a human and AI copilot jointly optimize behavior via interventions. "Human-AI Copilot Optimization (HACO)~\citep{li2021efficient}"
- Human-Gated DAgger (HG-DAgger): A DAgger variant where human gating determines when demonstrations are collected. "For instance, in \text{HG-DAgger}~\citep{kelly2019hg}, the agent is optimized to mimic human actions solely at the states where interventions occur."
- Implicit Preference Optimization (IPO): A preference-learning objective that uses a reference policy to implicitly encode preferences. "For DPO and IPO, we use a reference policy trained by Behavior Cloning from 10K expert demonstrations."
- Interactive Imitation Learning (IIL): Imitation learning with online human involvement to provide interventions and demonstrations. "Interactive Imitation Learning (IIL)~\citep{cai2025robot, reddy2018shared, kelly2019hg, spencer2020learning,peng2024learning, seraj2024interactive, liu2022robot, liu2024multi} incorporates human participants to intervene in the training process and provide online demonstrations."
- Intervention Weighted Regression (IWR): An imitation method that weights learning updates by whether an intervention occurred. "Intervention Weighted Regression (IWR)~\citep{mandlekar2020human}"
- Kinematic bicycle model: A simplified vehicle dynamics model used for fast trajectory prediction. "Following this approach, we use the kinematic bicycle model~\citep{polack2017kinematic} to simulate steps, assuming all other traffic participants remain stationary."
- Markov decision process (MDP): A formalism for sequential decision-making with states, actions, transitions, and rewards. "We use the Markov decision process~(MDP) to model the environment"
- Operational-space control: A robot control method that commands motion in task space with specified impedance. "the simulated UR5e robot arm uses fixed-impedance operational-space control to achieve the commanded pose."
- PPO-Lagrangian: A reinforcement learning algorithm that enforces constraints via Lagrangian methods on PPO. "The neural experts are trained using PPO-Lagrangian~\citep{ray2019benchmarking} for 20 million environment steps."
- Preference-based RL: Learning policies from human preference data rather than explicit rewards. "In summary, our approach bridges preference-based RL and imitation learning by demonstrating that DPO-style alignment techniques can be effectively adapted to control problems within an interactive imitation learning framework."
- Preference horizon: The number of future steps over which preferences inferred from an intervention are applied. "bootstrap each human intervention into future time steps, called the preference horizon, with the assumption that the agent follows the same action and the human makes the same intervention in the preference horizon."
- Predictive Preference Learning from Human Interventions (PPL): The proposed IIL algorithm that learns preferences over predicted trajectories from interventions. "Training process of PPL in the MetaDrive environment with the human expert over 20K steps."
- Proxy human policy: A neural policy used to approximate human behavior for experiments. "we report experiments with the neural policy as the proxy human policy in the MetaDrive, Table Wiping, and Nut Assembly tasks, respectively."
- Proxy Value Propagation (PVP): An IIL method that propagates proxy values to reduce risky behavior and interventions. "Proxy Value Propagation~\citep{peng2024learning}"
- Q-function: The expected return of taking an action in a state and following a policy thereafter. "We denote the Q-function of the human policy as ."
- Reference policy: A fixed policy used as a baseline in preference-optimization objectives. "For DPO and IPO, we use a reference policy trained by Behavior Cloning from 10K expert demonstrations."
- Reinforcement Learning (RL): Learning to act in an environment by optimizing cumulative reward. "Effectively leveraging human demonstrations to teach and align autonomous agents remains a central challenge in both Reinforcement Learning (RL)~\citep{xue2023guarded} and Imitation Learning (IL)~\citep{li2021efficient}."
- Reinforcement Learning from Human Feedback (RLHF): Training RL agents using human preference or feedback signals to shape rewards. "In the literature of RL and more recent RL from Human Feedback (RLHF), the agent explores the environment through trial and error or under human feedback guidance..."
- Rollout: A simulated trajectory obtained by applying a sequence of actions from a state. "we employ an efficient rollout-based trajectory prediction model to forecast the agent's future states."
- Shared behavior policy: The effective policy combining agent actions and human interventions during training. "the agent's actual trajectories during training are derived from the following shared behavior policy"
- Sigmoid function: A logistic function used to map values into probabilities in classification losses. "where is the Sigmoid function, and is a hyperparameter."
- SLiC-HF: A preference-based objective variant used in RLHF-style training. "SLiC-HF~\citep{zhao2023slic}"
- Total variation distance (TV distance): A metric for distribution divergence equal to half the L1 difference. "Here, $D_{\text{TV}(P, Q)=\tfrac{1}{2}|P-Q|_1$ is the total variation distance between two distributions."
- Trajectory prediction model: A model that predicts the agent’s future states given the current state and action. "Trajectory Prediction Model. In this work, we allow the agent to access a short-term trajectory prediction model ."
Collections
Sign up for free to add this paper to one or more collections.