- The paper identifies that RL training for LLMs suffers from rapid policy entropy collapse, leading to an early performance plateau.
- It reveals an exponential relationship between policy entropy and validation performance through rigorous theoretical and empirical analysis.
- The study introduces practical techniques, Clip-Cov and KL-Cov, to control entropy and enhance downstream performance in reasoning tasks.
The Entropy Mechanism of Reinforcement Learning for Reasoning LLMs
This paper investigates the phenomenon of policy entropy collapse in RL applied to LLMs, a critical issue that hinders the effective scaling of RL for reasoning tasks. The authors identify that policy entropy tends to diminish rapidly during the early stages of training, leading to performance saturation and limiting the exploration of new strategies. Through theoretical analysis and empirical validation, the paper elucidates the dynamics of policy entropy and introduces practical techniques to mitigate its collapse.
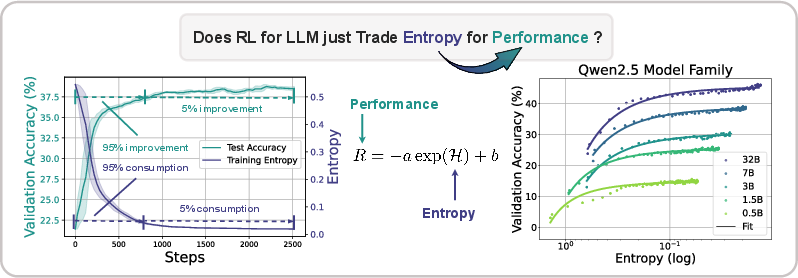
Figure 1: Left: Entropy collapse and performance saturation. Over 95% entropy drop/performance gains take place at the early stage of RL training. The model then reaches a plateau with little improvement. Right: The predictable relationship between validation performance and policy entropy. Without intervention, the policy ``trades'' entropy for performance exponentially, showing clear ceilings that hinder further policy enhancement.
Empirical Observation of Entropy Collapse
The paper empirically demonstrates that policy entropy collapses during RL training for LLMs, which results in performance plateaus. The authors observe a consistent pattern across various models and tasks: policy entropy decreases sharply at the beginning of training, while validation performance rises rapidly and then plateaus. They quantitatively model the relationship between validation reward R and policy entropy H with the exponential function R=−aexp(H)+b. The paper highlights the predictability of policy performance from entropy and notes that the coefficients a and b reflect intrinsic properties of the policy and data. The authors show that this equation indicates that the upper bound of the policy performance is deterministic with the exhaustion of policy entropy (H=0,R=−a+b), which potentially limits the benefits of scaling training compute for RL.
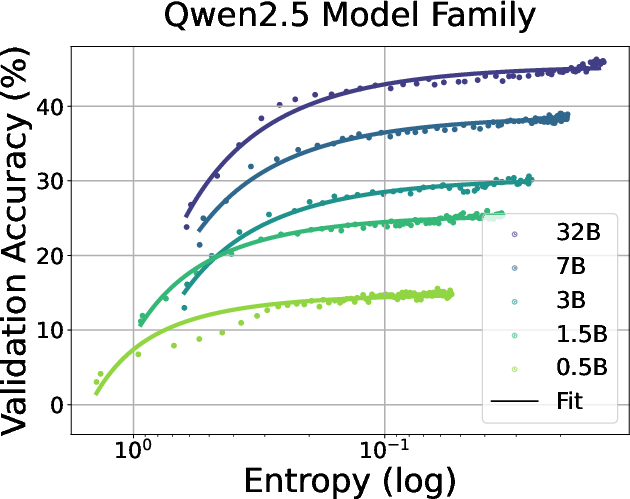
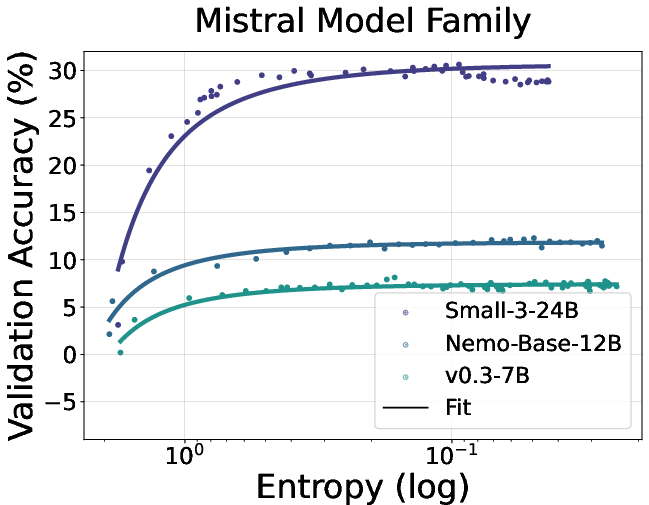
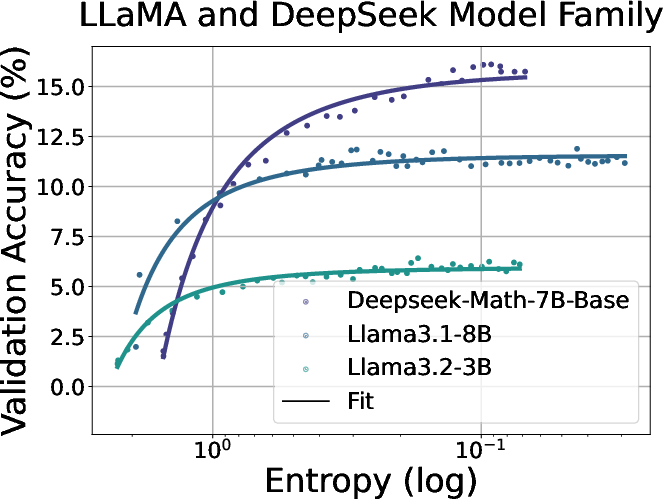
Figure 2: Fitting curves between policy entropy and validation performance on math task. We conduct validation every 4 rollout steps until convergence.
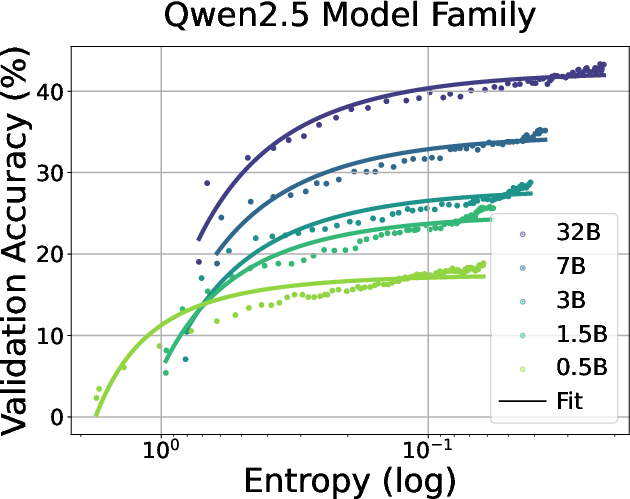
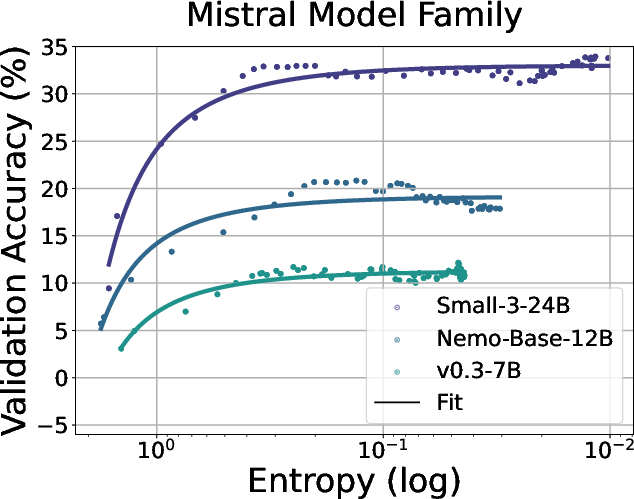
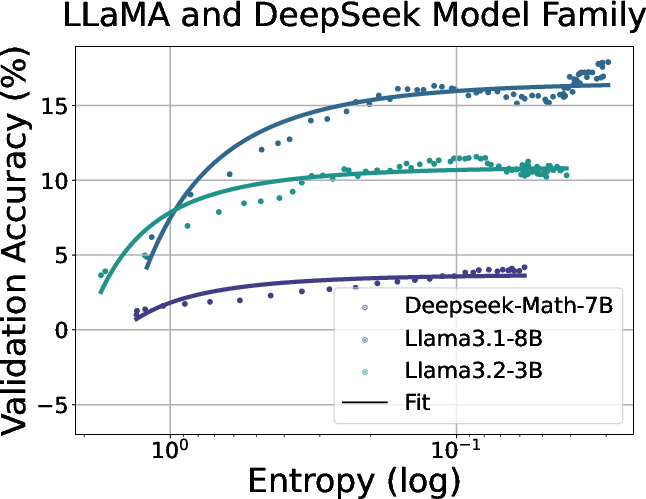
Figure 3: Fitting curves between policy entropy and validation performance in coding task. We conduct validation every 4 rollout steps until convergence.
Theoretical Analysis of Entropy Dynamics
To understand the mechanism behind entropy collapse, the paper analyzes the dynamics of policy entropy from a theoretical perspective. The authors derive that, for softmax policies such as those used in LLMs, the change in policy entropy between two consecutive steps is proportional to the covariance between the log-probability and the change in logits for an action. They further show that under Policy Gradient and Natural Policy Gradient algorithms, the change in logits is proportional to the action advantage. This implies that a high-probability action with high advantage would reduce policy entropy, while a rare action with a high advantage would increase policy entropy. The paper validates these theoretical conclusions through experimental results, demonstrating that the covariance term closely matches the entropy differences throughout training.
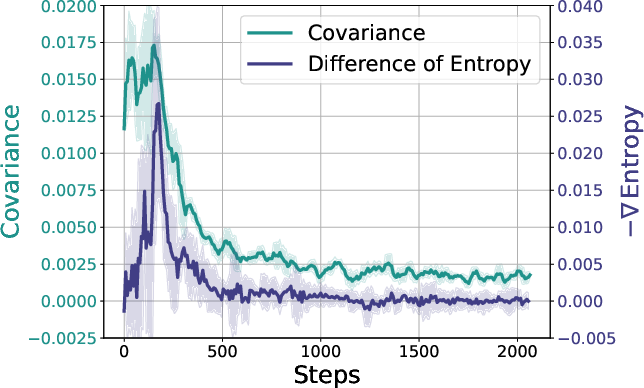
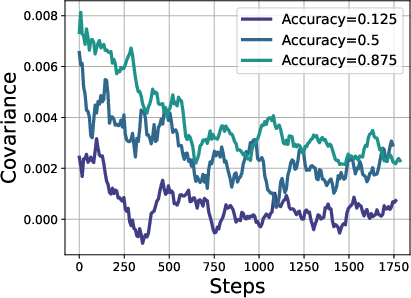
Figure 4: Left: The dynamics of policy entropy (step-wise entropy difference) and covariance during on-policy GRPO training. They show similar trends as expected from the theoretical results. Right: Different prompt groups show distinct covariance behaviors. Easier prompts with higher accuracy have higher covariances as well, while harder prompts have lower covariances.
Entropy Control via Covariance Regularization
Based on the theoretical analysis, the paper proposes two techniques for entropy control by restricting the update of tokens with high covariances: Clip-Cov and KL-Cov. Clip-Cov randomly selects a small portion of tokens with positive covariances and detaches their gradients. KL-Cov applies a KL penalty to tokens with the largest covariances. Experimental results demonstrate that these methods effectively control policy entropy, prevent entropy collapse, and achieve better downstream performance in mathematical reasoning tasks.
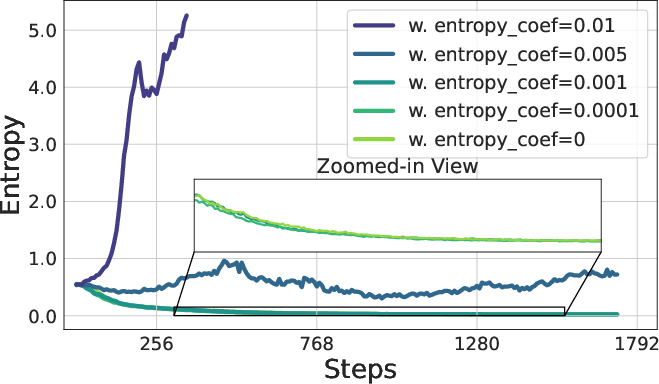
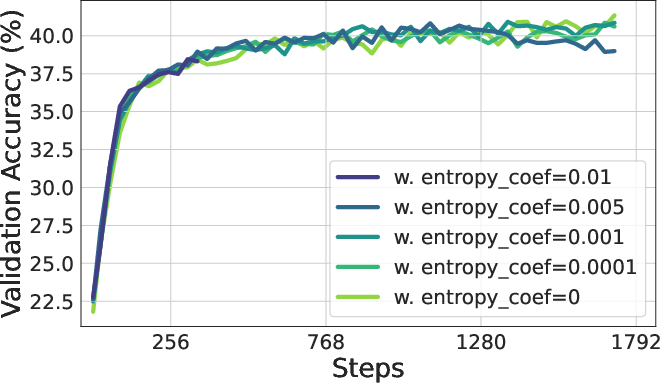
Figure 5: The policy entropy and validation accuracy of adding entropy loss where Lent is the original loss and α is the coefficient of entropy loss.
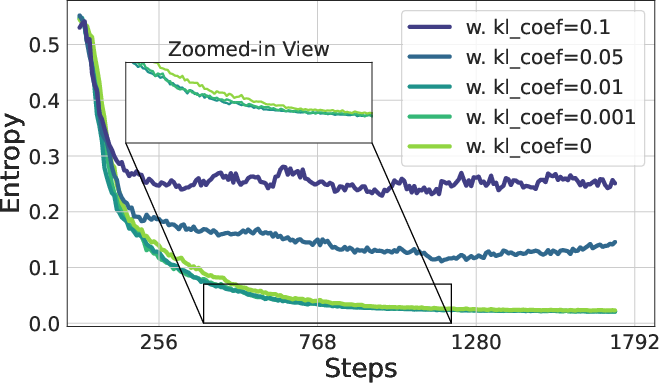
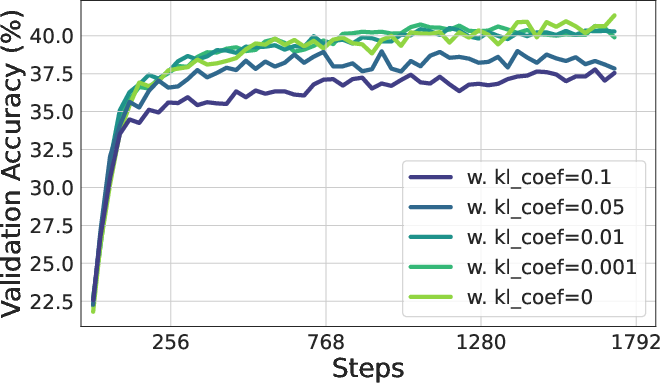
Figure 6: The policy entropy and validation accuracy of adding KL penalty between policy and reference model where LKL is the original loss and β is the coefficient of KL loss.
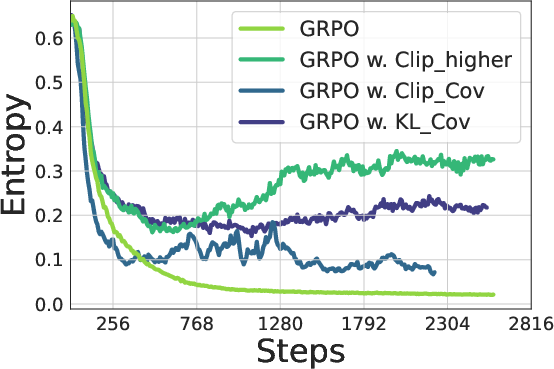
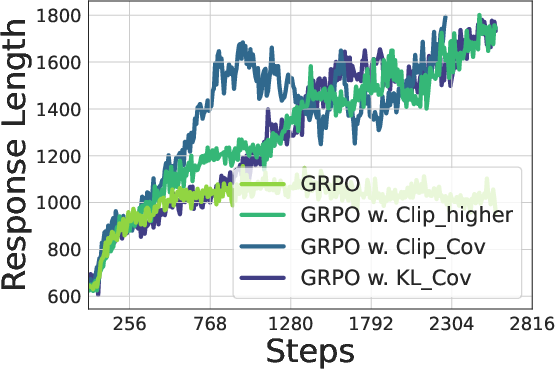
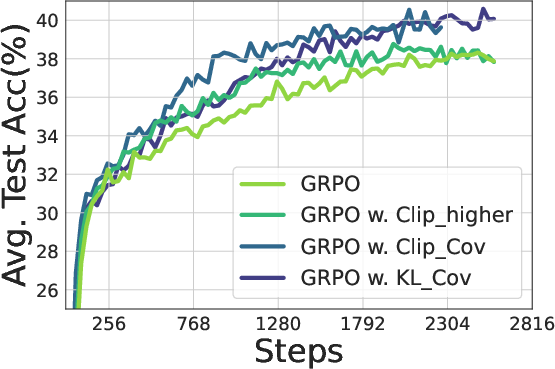
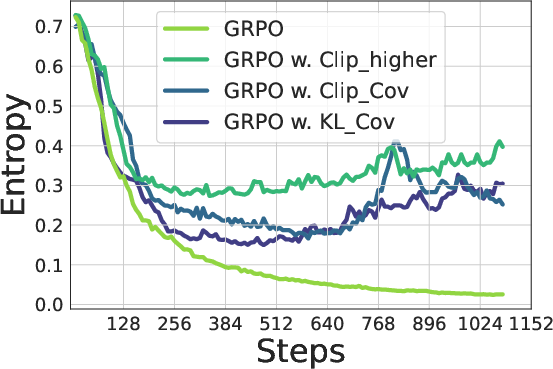
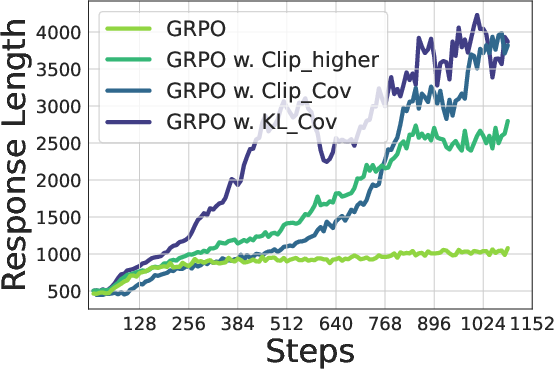
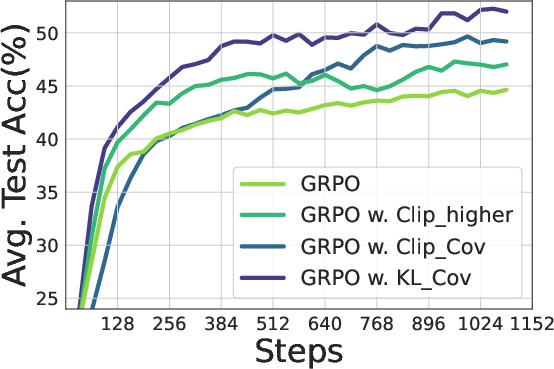
Figure 7: Training Qwen2.5-7B (Top) / Qwen2.5-32B (bottom) with GRPO with/without our methods. Left: Entropy dynamics. Our methods uplift policy entropy from collapse, enabling sustained exploration. Middle: Our method also incentivizes longer responses compared with vanilla GRPO. Right: The policy model consistently outperforms the baseline on testsets, avoiding performance plateaus.
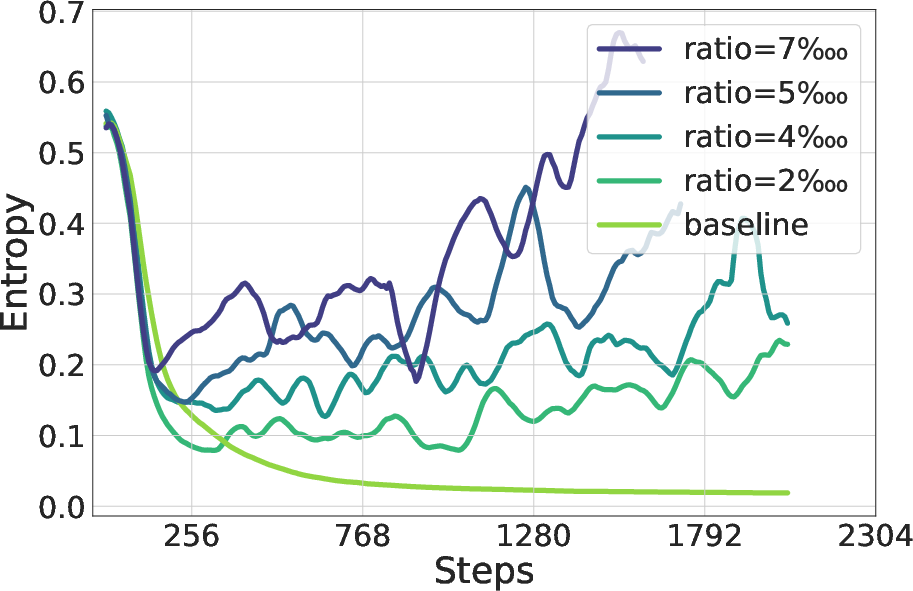
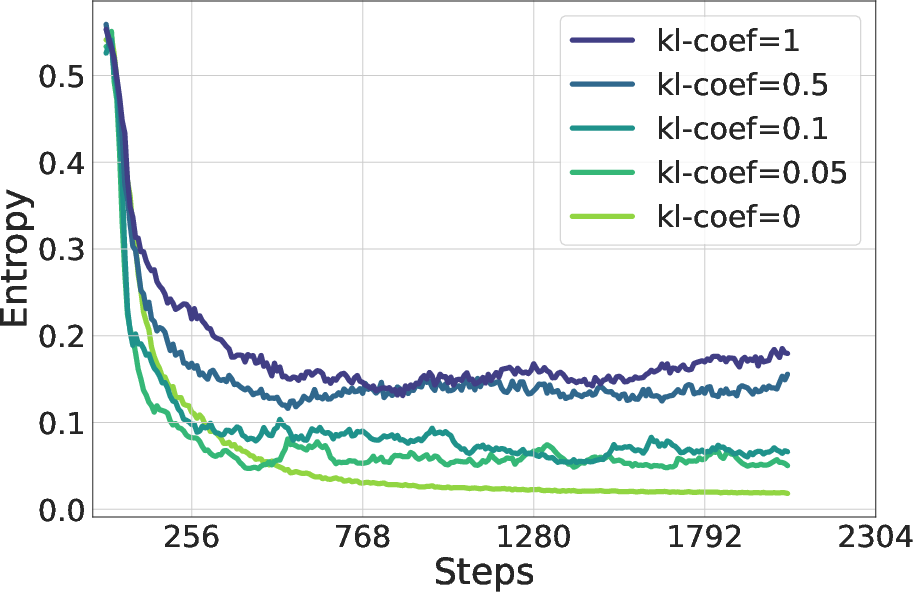
Figure 8: Differences in entropy dynamics of Qwen2.5-7B under varying KL coefficients and Clip ratios, evaluated Clip-Cov (left) and KL-Cov (right) settings, respectively.
Implications and Future Directions
This research highlights the importance of entropy management in scaling RL for LLMs. The predictability of performance saturation due to entropy collapse suggests that simply increasing training compute may not lead to significant gains without addressing the underlying exploration issues. The proposed Clip-Cov and KL-Cov techniques offer practical ways to control policy entropy and improve the performance of RL-trained LLMs. Future research could explore more sophisticated methods for entropy control, investigate the interplay between entropy and other factors influencing RL performance, and examine the applicability of these techniques to a broader range of tasks and model architectures.
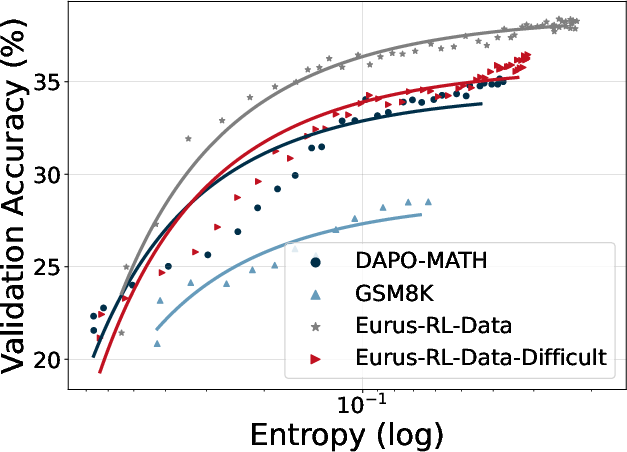
Figure 9: Training Qwen2.5-7B with different data.
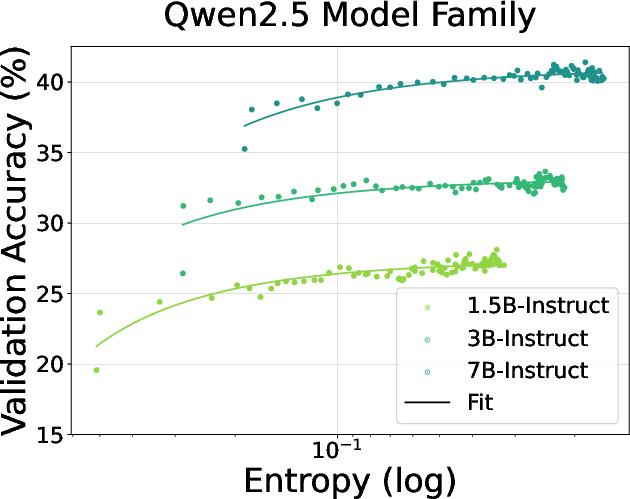
Figure 10: Training Qwen2.5 instruct models on math task.
Conclusion
This paper provides valuable insights into the entropy mechanism of RL for LLMs and offers practical solutions to mitigate the problem of policy entropy collapse. By understanding and addressing this critical issue, researchers and practitioners can unlock the full potential of RL for training LLMs and achieve significant advancements in AI reasoning capabilities.