- The paper demonstrates that restricting policy gradient updates to the top 20% high-entropy tokens significantly enhances reinforcement learning for LLM reasoning.
- Empirical results reveal that forking tokens, which mark logical decision points, drive generalization and robust performance across various benchmarks.
- Training on low-entropy tokens leads to performance degradation, highlighting the crucial role of token-level entropy in optimizing model reasoning.
High-Entropy Minority Tokens as the Drivers of Effective RLVR in LLM Reasoning
Introduction
The paper "Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning" (2506.01939) presents a comprehensive analysis of token-level entropy patterns in Chain-of-Thought (CoT) reasoning within LLMs and their implications for Reinforcement Learning with Verifiable Rewards (RLVR). The central thesis is that a small subset of high-entropy tokens—termed "forking tokens"—are pivotal in steering reasoning trajectories and that RLVR's efficacy is primarily attributable to the optimization of these tokens. The authors demonstrate that restricting policy gradient updates to the top 20% highest-entropy tokens not only maintains but often improves reasoning performance, especially as model size increases, while optimization over the low-entropy majority is detrimental.
Token Entropy Patterns in CoT Reasoning
The analysis begins with a detailed characterization of token entropy distributions in CoT outputs. Empirical results show that the vast majority of tokens are generated with low entropy, reflecting deterministic linguistic or structural continuations, while a minority exhibit high entropy, corresponding to decision points or logical forks in reasoning.
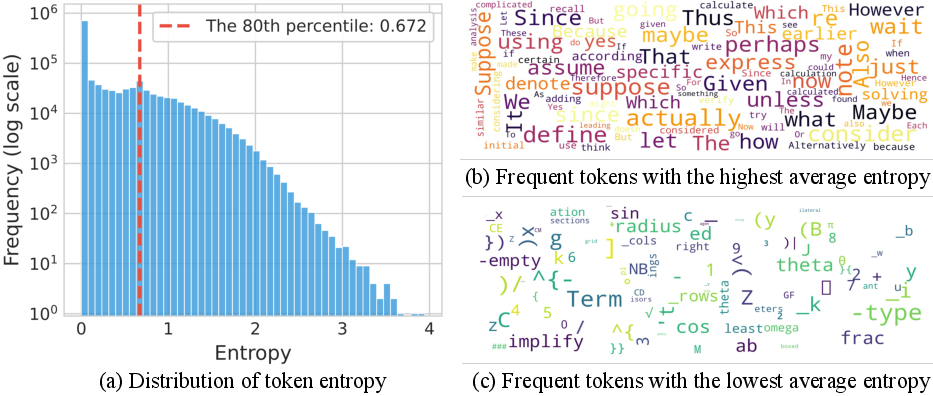
Figure 1: Token entropy distribution in CoTs, with high-entropy tokens acting as reasoning forks and low-entropy tokens executing deterministic steps.
Word cloud visualizations further clarify that high-entropy tokens are typically logical connectors or operators (e.g., "however", "thus", "suppose"), whereas low-entropy tokens are syntactic or semantic continuations (e.g., suffixes, code fragments). Controlled experiments manipulating decoding temperature at forking tokens confirm that increasing entropy at these positions enhances reasoning performance, while reducing it degrades accuracy.
RLVR Training Dynamics and Entropy Evolution
The study extends to the evolution of entropy patterns during RLVR training. The authors show that RLVR largely preserves the base model's entropy distribution, with significant changes confined to the high-entropy subset. Overlap analysis of high-entropy token positions between base and RLVR-trained models reveals >86% retention at convergence, indicating that RLVR does not fundamentally alter which tokens are uncertain, but rather amplifies their entropy.
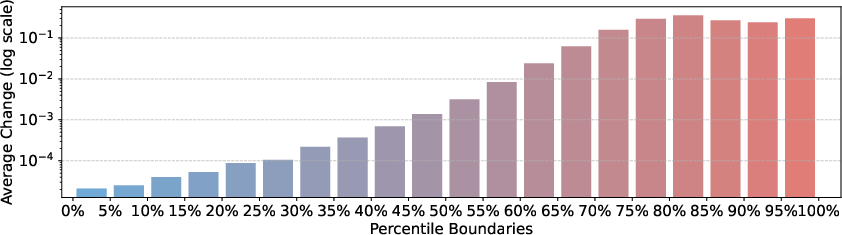
Figure 2: Entropy change after RLVR, with high-entropy tokens experiencing the largest increases.
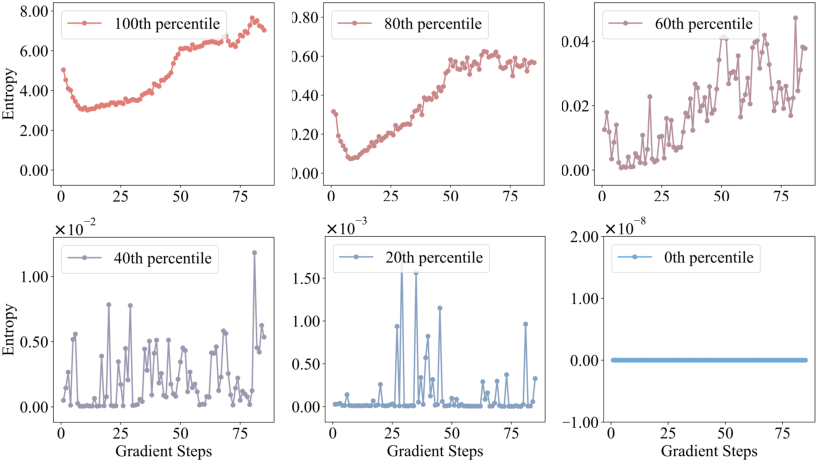
Figure 3: Evolution of entropy percentiles during RLVR, showing stability in low-entropy regions and increased entropy in high-entropy percentiles.
Selective Policy Gradient Updates: Beyond the 80/20 Rule
Building on these insights, the authors propose a modified RLVR objective that restricts policy gradient updates to the top ρ fraction of high-entropy tokens (typically ρ=20%). This is implemented by masking gradients for tokens below a batch-specific entropy threshold, as formalized in their adaptation of the DAPO algorithm.
Empirical results across Qwen3-32B, Qwen3-14B, and Qwen3-8B models demonstrate that this selective update strategy yields substantial improvements in reasoning benchmarks (AIME'24, AIME'25, AMC'23, MATH500, Minerva, OlympiadBench), with gains scaling with model size. For instance, on Qwen3-32B, restricting updates to forking tokens improves AIME'24 by +7.71 and AIME'25 by +11.04 over vanilla DAPO.
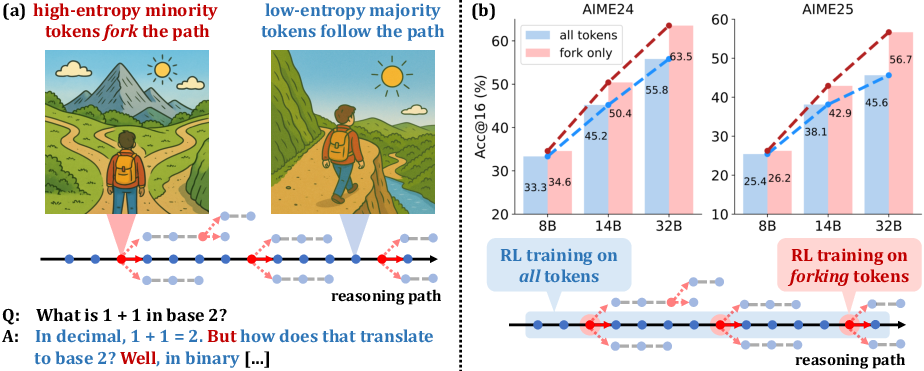
Figure 4: Only a minority of tokens are high-entropy forks; RLVR using only these tokens delivers SoTA scores and strong scaling trends.
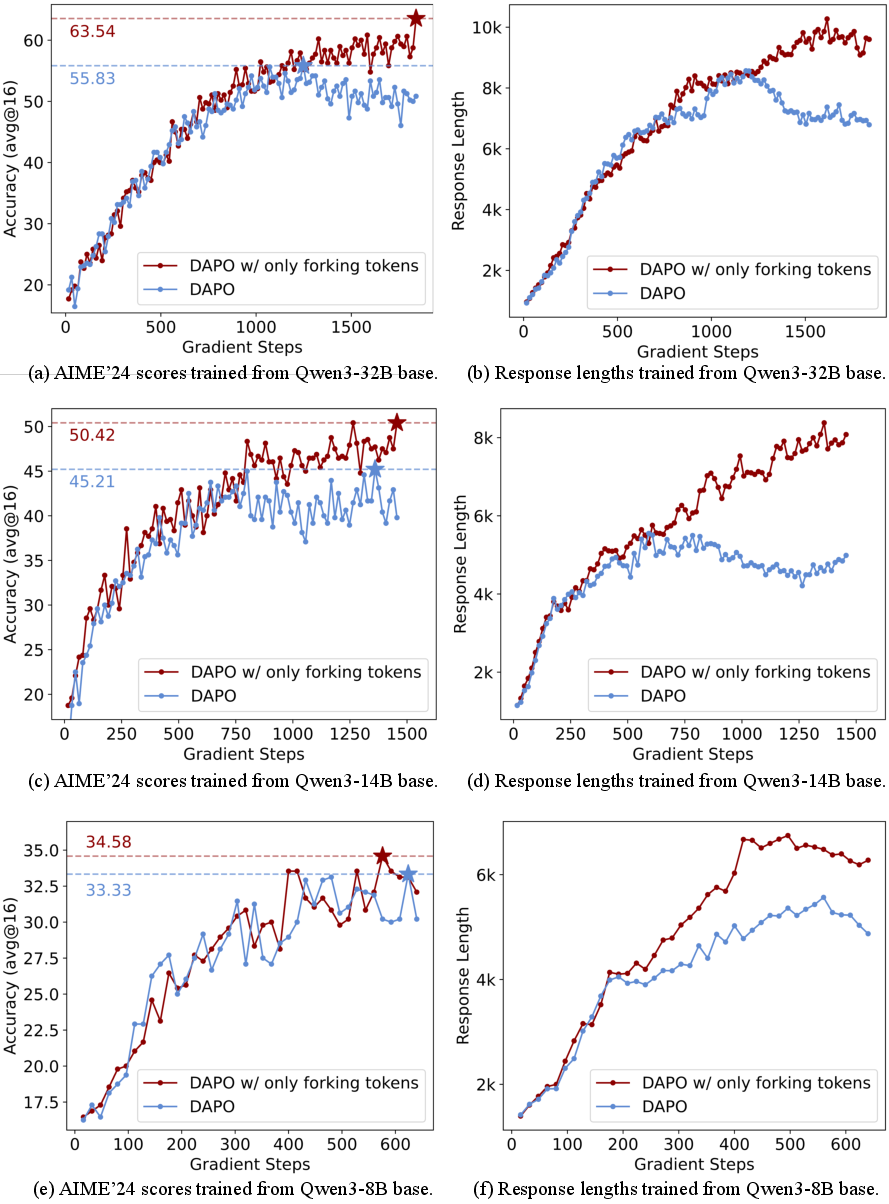
Figure 5: Dropping the bottom 80% low-entropy tokens stabilizes training and improves benchmark scores across model sizes.
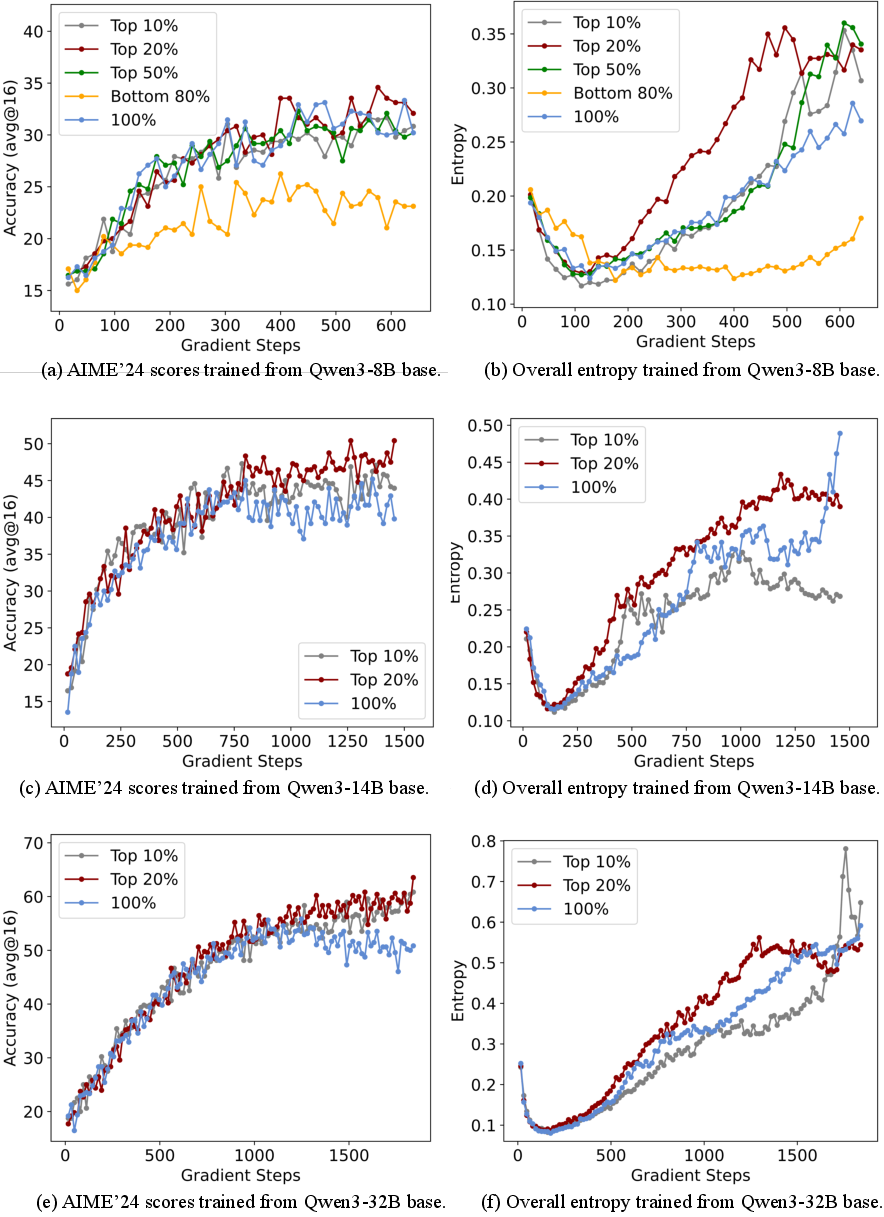
Figure 6: Performance and overall entropy for different token selection ratios in policy gradient loss.
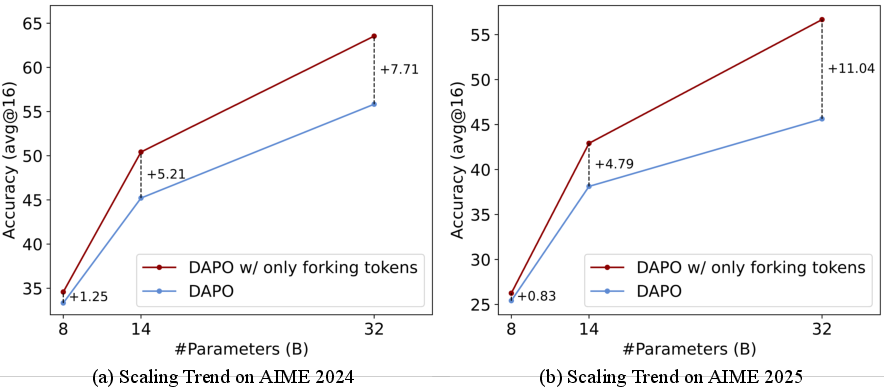
Figure 7: Scaling trend—benefits of focusing on forking tokens increase with model size.
Notably, training on the bottom 80% low-entropy tokens leads to severe performance degradation, confirming their negligible or negative contribution to reasoning optimization.
Generalization and Out-of-Distribution Robustness
The selective RLVR approach also generalizes to out-of-distribution tasks. When trained on mathematical data and evaluated on LiveCodeBench (a programming benchmark), models using only high-entropy tokens outperform those trained with all tokens, indicating that forking tokens are associated with generalization capacity.
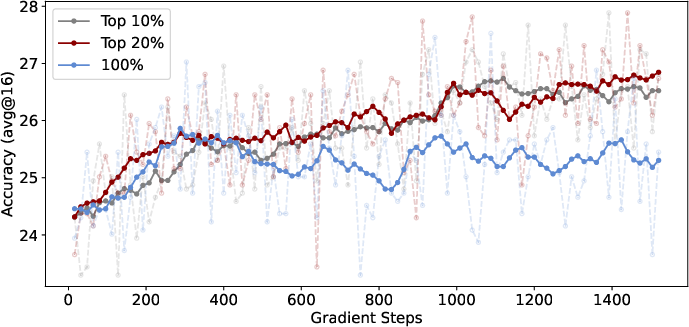
Figure 8: DAPO with only high-entropy tokens outperforms vanilla DAPO on LiveCodeBench, demonstrating generalization.
Scaling, Context Length, and Model Families
Increasing the maximum response length further unlocks performance gains, with the Qwen3-32B model's AIME'24 score rising from 63.54 to 68.12 when the context is extended from 20k to 29k tokens.
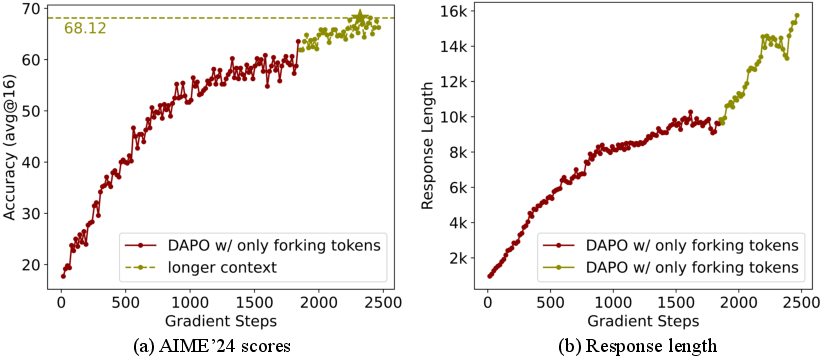
Figure 9: Extending response length boosts AIME'24 scores and response length.
Experiments on Llama-3.1-8B, after cold-start SFT, show similar trends, though overall performance is lower, suggesting that model architecture and pretraining corpus may influence the effectiveness of entropy-based RLVR.
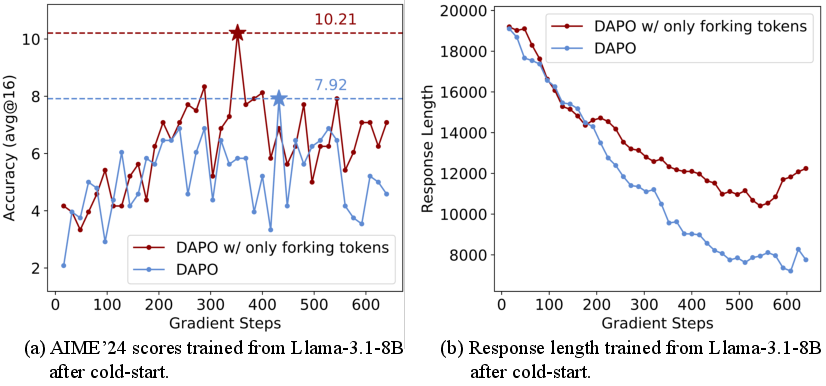
Figure 10: DAPO with forking tokens yields longer responses and higher scores than vanilla DAPO on Llama-3.1-8B.
Theoretical and Practical Implications
The findings have several implications:
- RL Generalization vs. SFT Memorization: RLVR preserves or increases entropy at forking tokens, maintaining flexibility in reasoning paths and supporting generalization, whereas SFT reduces entropy, leading to memorization and poor out-of-distribution performance.
- Distinctive Entropy Patterns in LLMs: Unlike traditional RL, where action entropy is uniform, LLM CoTs are shaped by prior knowledge and readability constraints, resulting in a bimodal entropy distribution.
- Entropy Bonus vs. Clip-Higher: Uniform entropy bonuses are suboptimal for LLM reasoning, as they disrupt low-entropy tokens. The clip-higher mechanism selectively increases entropy at forking tokens, aligning with the observed patterns.
Visualization of Token Entropy
The paper provides extensive visualizations of token entropy across long CoT responses, illustrating the sparse distribution of high-entropy forks and the predominance of low-entropy continuations.

Figure 11: Visualization of token entropy (part 1).

Figure 12: Visualization of token entropy (part 2).

Figure 13: Visualization of token entropy (part 3).

Figure 14: Visualization of token entropy (part 4).

Figure 15: Visualization of token entropy (part 5).

Figure 16: Visualization of token entropy (part 6).
Conclusion
This work establishes that the optimization of high-entropy minority tokens is the principal driver of RLVR's success in LLM reasoning. Selective policy gradient updates focused on forking tokens yield superior performance and scaling trends, while low-entropy tokens are largely irrelevant or detrimental. The token-entropy perspective offers a principled framework for designing more efficient RLVR algorithms and suggests new directions for enhancing generalization, scaling, and cross-domain robustness in LLMs. Future research should extend these findings to broader model families, domains, and training paradigms, and explore the integration of entropy-based strategies in SFT, distillation, and multi-modal reasoning.