- The paper demonstrates a strong correlation between a model’s generative performance and its tendency to prefer its own outputs.
- It employs pairwise evaluations across benchmarks like MATH500, MMLU, and MBPP+ to distinguish between legitimate and harmful self-preference.
- The study reveals that using a chain-of-thought approach during evaluation can significantly reduce harmful self-preference bias.
"Do LLM Evaluators Prefer Themselves for a Reason?"
The paper "Do LLM Evaluators Prefer Themselves for a Reason?" (2504.03846) investigates the self-preference bias among LLMs used as evaluators. This bias tends to make LLMs prefer their own generated responses, a phenomenon that intensifies with increasing model size and capability. The study leverages verifiable benchmarks across mathematical reasoning, factual knowledge, and code generation to objectively assess whether this bias reflects genuinely superior model outputs or is indicative of a harmful evaluation bias.
Introduction and Motivation
LLMs serve as automatic evaluators in numerous applications, including benchmarking, reward modeling, and AI oversight. Their scalability, consistency, and cost-effectiveness make them appealing for assessing model outputs at scale. However, the reliability of LLMs as evaluators is brought into question due to a self-preference bias, particularly pronounced in larger models. This study addresses whether self-preference reflects true model superiority or signifies a detrimental bias by examining verifiable benchmarks that permit objective assessment.
Experimental Setup
Measurement of Self-Preference
The study adopts and extends the LLM-as-a-Judge pairwise evaluation format. LLM evaluators are presented with a user query and two anonymous responses from different models. The evaluator provides a three-way verdict to assess which response is superior. The self-preference ratio (SPR) is defined to quantify the propensity of LLM evaluators to favor their own outputs over others.
Evaluation Models:
The evaluators consist of 11 models from the Qwen, Llama, and Gemma families, spanning various model scales. The evaluatees include models from both open-source and proprietary domains, encapsulating a wide range of capabilities.
Tasks Utilized:
- Mathematical Reasoning – MATH500 datasets, accuracy as the metric.
- Factual Knowledge – MMLU benchmark, evaluated by accuracy.
- Code Generation – MBPP+ benchmark, evaluated using Pass@1.
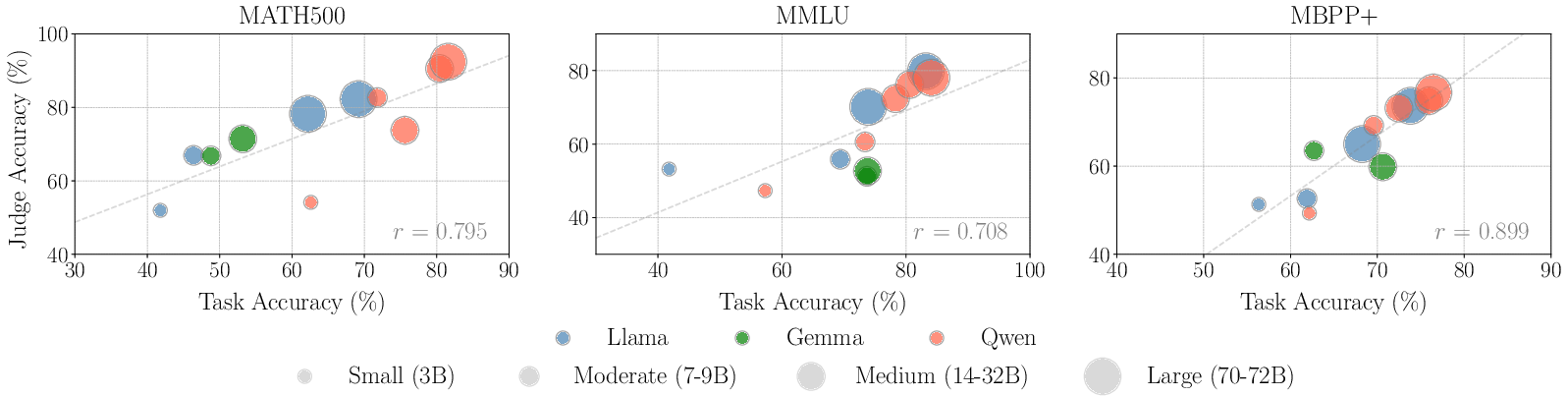
Figure 1: Correlation between judge accuracy (LLMs as evaluators) and task accuracy (LLMs as generators) measured by Pearson correlation coefficient r~\citep{cohen2009pearson}.
Findings on Self-Preference
The results exhibit a strong positive correlation between a model's task performance as a generator and its evaluation accuracy as a judge across all benchmarks. This correlation implies that models with high generative capabilities generally make more accurate evaluations, aligning their self-preference with objectively superior performance.
Legitimate vs. Harmful Self-Preference
Legitimate Self-Preference:
The legitimate self-preference ratio (LSPR) captures instances where self-preference aligns with objective superiority. The analysis indicates that stronger models display higher LSPR values, suggesting their self-preferring behavior is often justified by genuinely improved output quality.
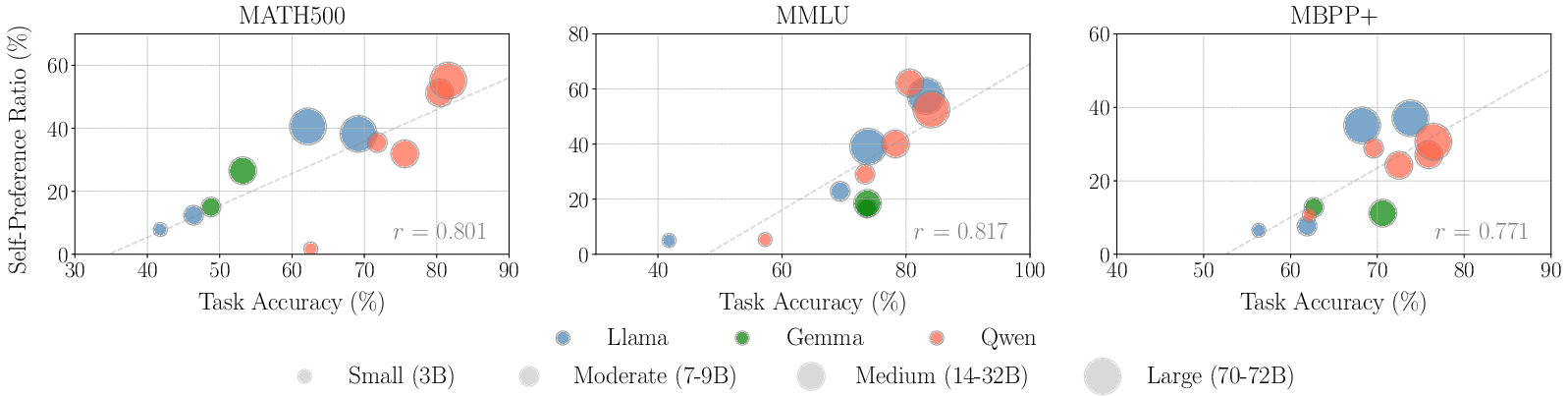
Figure 2: Correlation between self-preference ratio and task accuracy. The clear positive correlation suggests that better generators typically prefer themselves more as evaluators.
Harmful Self-Preference Bias
Harmful self-preference, wherein a model mistakenly favors its own incorrect outputs, persists even in stronger models, albeit such instances are rarer but more pronounced with increased model capabilities. This suggests that strong models, despite generating fewer erroneous outputs, show greater bias in incorrect instance assessments.
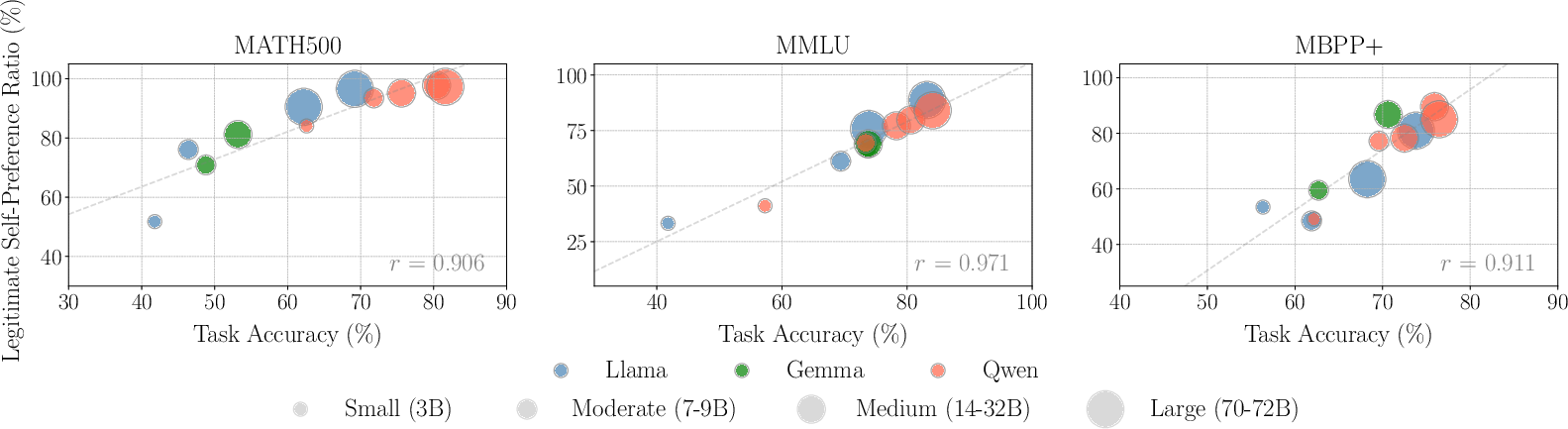
Figure 3: Correlation between harmful self-preference propensity and task accuracy. The positive correlation, particularly on MATH500 and MMLU, implies that when strong models are objectively incorrect, they prefer themselves more often.
Mitigating Harmful Self-Preference
The study explores inference-time scaling strategies; generating a long Chain-of-Thought (CoT) before verdict pronouncement reduces harmful self-preference bias effectively. Increasing the number of reasoning tokens guides evaluators to reassess their initial judgment critically, augmenting verdict accuracy.
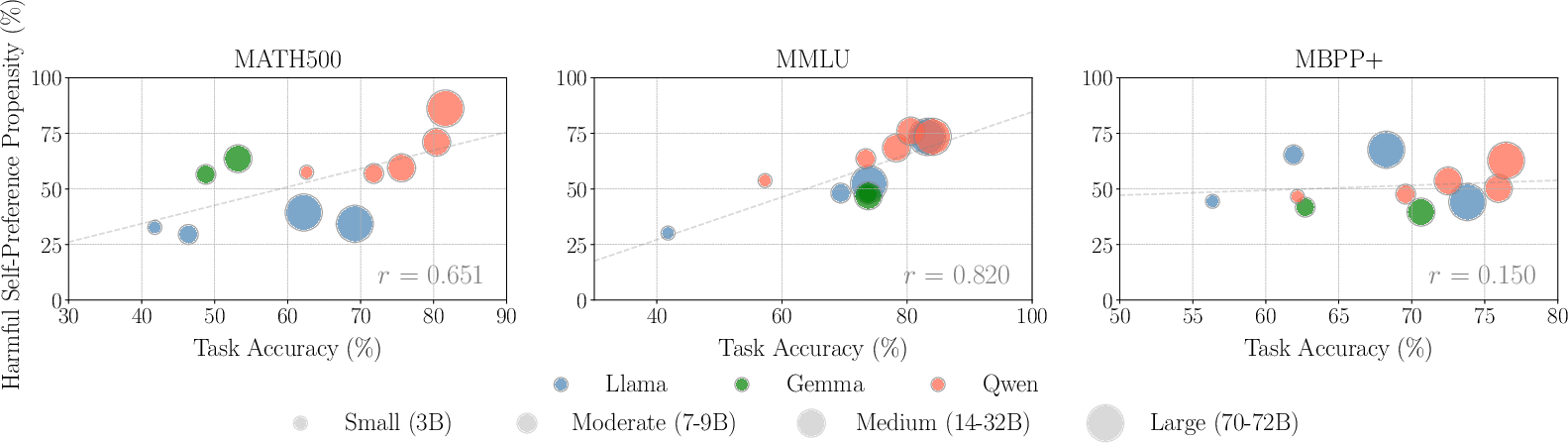
Figure 4: The harmful self-preference propensity at varying levels of evaluator reasoning. More accurate verdicts are achieved by generating more reasoning tokens prior to judgment.
Conclusion
This research provides a nuanced evaluation of self-preference bias in LLM evaluators, underpinning efforts to assess model effectiveness objectively using ground-truth references. The study establishes that self-preference in more capable models is often aligned with objective superiority, albeit with a potential bias in incorrect high-confidence outputs. Using reasoning-augmented evaluation provides a practical method to mitigate the adverse impacts of such biases, offering a path towards more reliable LLM-based evaluation frameworks. Future work can explore additional forms of bias and extend these evaluations to less defined, subjective tasks, ensuring broader applicability and enhanced trust in LLMs as evaluators. Further research into diverse inference-time scaling techniques may also yield fruitful results in improving LLM evaluator reliability and robustness.
In conclusion, while self-preference bias in LLM evaluators does exist, this paper's findings emphasize how it can often be a reflection of a model's genuine evaluative accuracy, given their generating capabilities. The problems posed by harmful self-preference, especially in more capable models, suggest a need for an innovative approach in inference-time reasoning strategies to mitigate these biases and enhance evaluator reliability. These insights are integral for future advancements in scalable AI oversight, which seeks to balance automated and human evaluations for complex tasks.