How Diffusion Models Memorize
Abstract: Despite their success in image generation, diffusion models can memorize training data, raising serious privacy and copyright concerns. Although prior work has sought to characterize, detect, and mitigate memorization, the fundamental question of why and how it occurs remains unresolved. In this paper, we revisit the diffusion and denoising process and analyze latent space dynamics to address the question: "How do diffusion models memorize?" We show that memorization is driven by the overestimation of training samples during early denoising, which reduces diversity, collapses denoising trajectories, and accelerates convergence toward the memorized image. Specifically: (i) memorization cannot be explained by overfitting alone, as training loss is larger under memorization due to classifier-free guidance amplifying predictions and inducing overestimation; (ii) memorized prompts inject training images into noise predictions, forcing latent trajectories to converge and steering denoising toward their paired samples; and (iii) a decomposition of intermediate latents reveals how initial randomness is quickly suppressed and replaced by memorized content, with deviations from the theoretical denoising schedule correlating almost perfectly with memorization severity. Together, these results identify early overestimation as the central underlying mechanism of memorization in diffusion models.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
How Diffusion Models Memorize — A Simple Explanation
What is this paper about?
This paper studies why and how diffusion image generators (like Stable Diffusion) sometimes “memorize” pictures from their training data and accidentally recreate them. That’s a problem because it can copy private or copyrighted images. The authors dig into the model’s step‑by‑step “unnoising” process to find the root cause.
What questions are the researchers asking?
- When a diffusion model memorizes, what exactly is happening inside it during generation?
- Is memorization just “overfitting” (being too tailored to the training set), or is something else going on?
- Which part of the generation process pushes the model to recreate a training image, and why?
How did they study it? (Methods in everyday language)
Think of image generation as unblurring a photo over many steps:
- The model starts from pure noise (like TV static).
- At each step it removes some noise and adds details to match the prompt (the text you give it).
Key ideas translated:
- Latent: The model’s “internal canvas” where it builds the image before decoding it into pixels.
- Denoising steps: The small, repeated moves that turn noise into a clear picture.
- Classifier-free guidance (CFG): A “steering knob” that makes the model follow the text prompt more strongly. A higher guidance scale means a stronger pull toward what the prompt describes.
What they did:
- Used popular models (Stable Diffusion v1.4/v2.1, RealisticVision).
- Generated many images per prompt from different random starts to see how outputs change (or don’t).
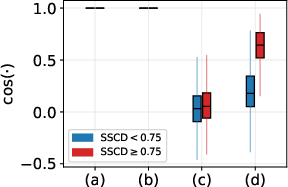
- Measured “copy-likeness” using SSCD, a tool that detects if two images are basically the same. They checked:
- Similarity to the original training image.
- Similarity among the model’s own generated images for the same prompt (to catch cases where all outputs look the same, even if they don’t exactly match the training picture).
- Analyzed the model’s internal steps:
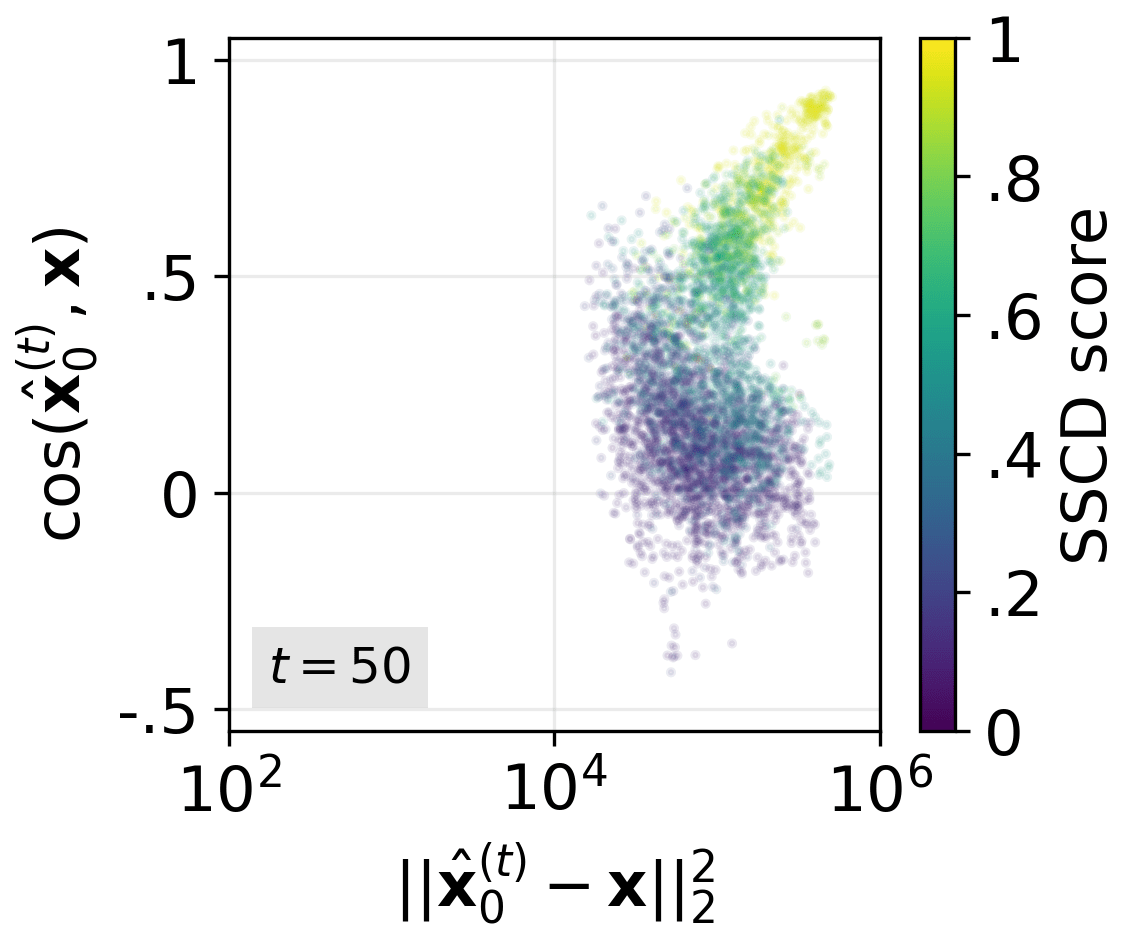
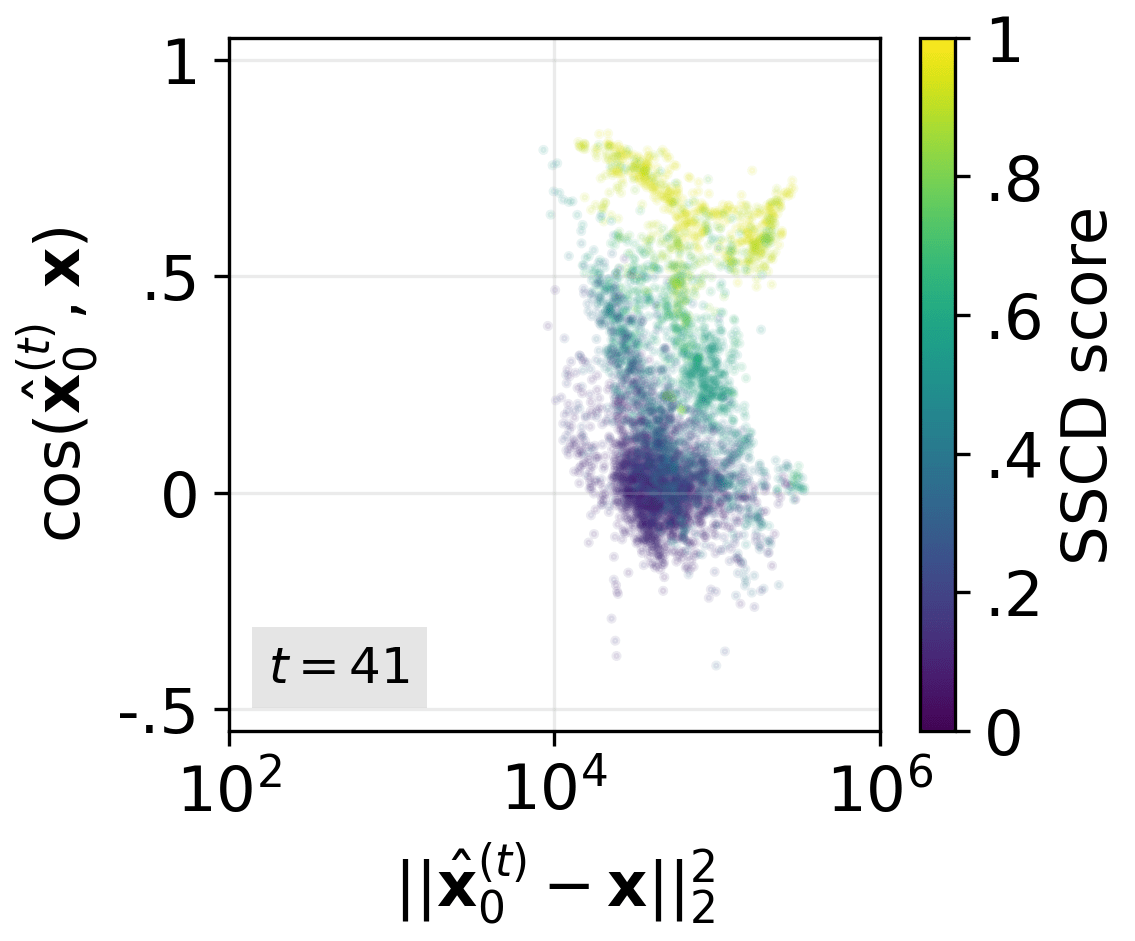
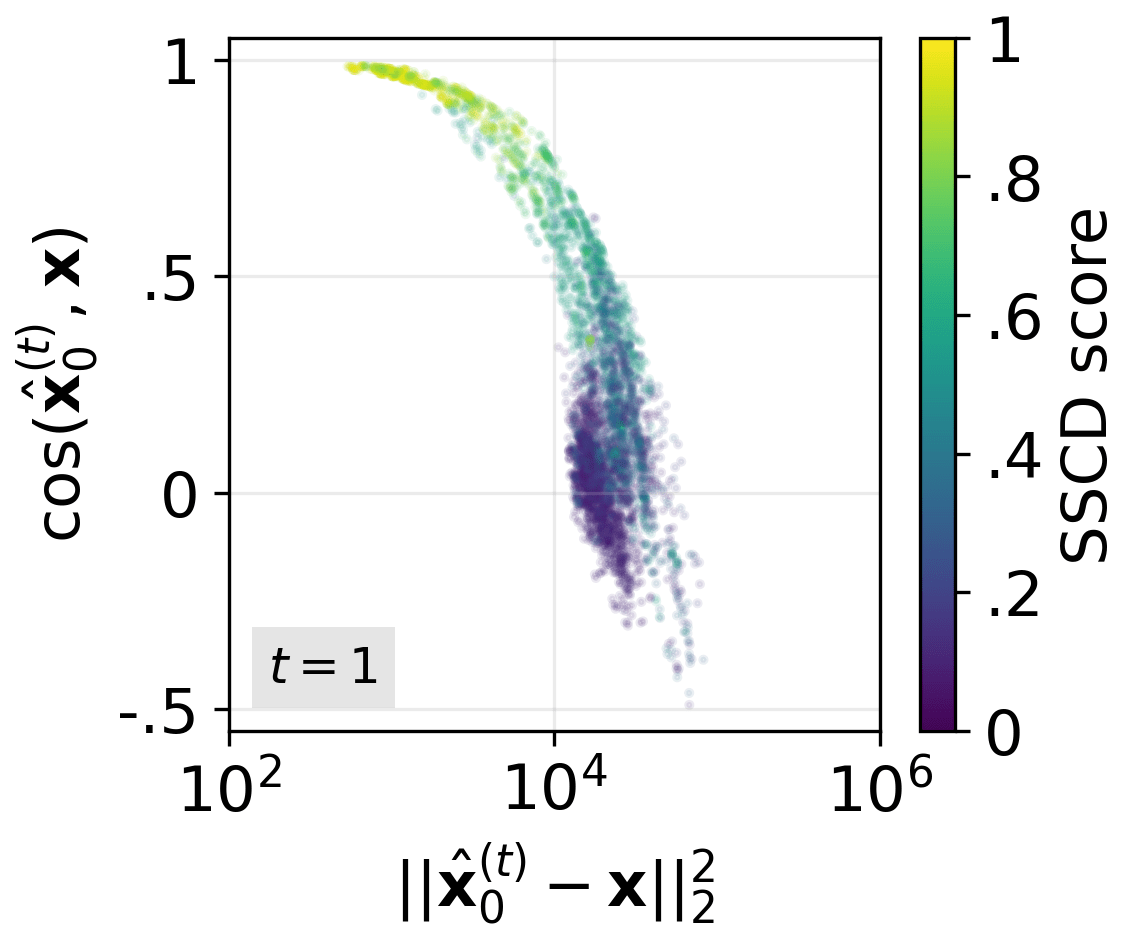
- Compared early guesses of the final image to the real training image.
- Looked at “noise predictions” with and without guidance to see how much the prompt pushes the model.
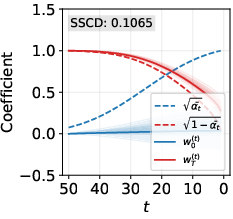
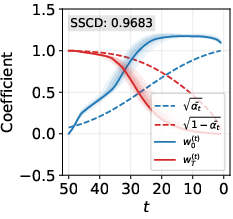
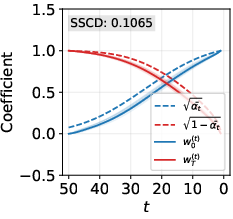
- Broke down the model’s internal canvas at each step into two parts: how much comes from the original random noise vs. how much looks like the training image. Think of it like mixing two ingredients and tracking how quickly each dominates.
What did they discover?
Here are the main findings, explained simply:
- Memorization is not just “overfitting.”
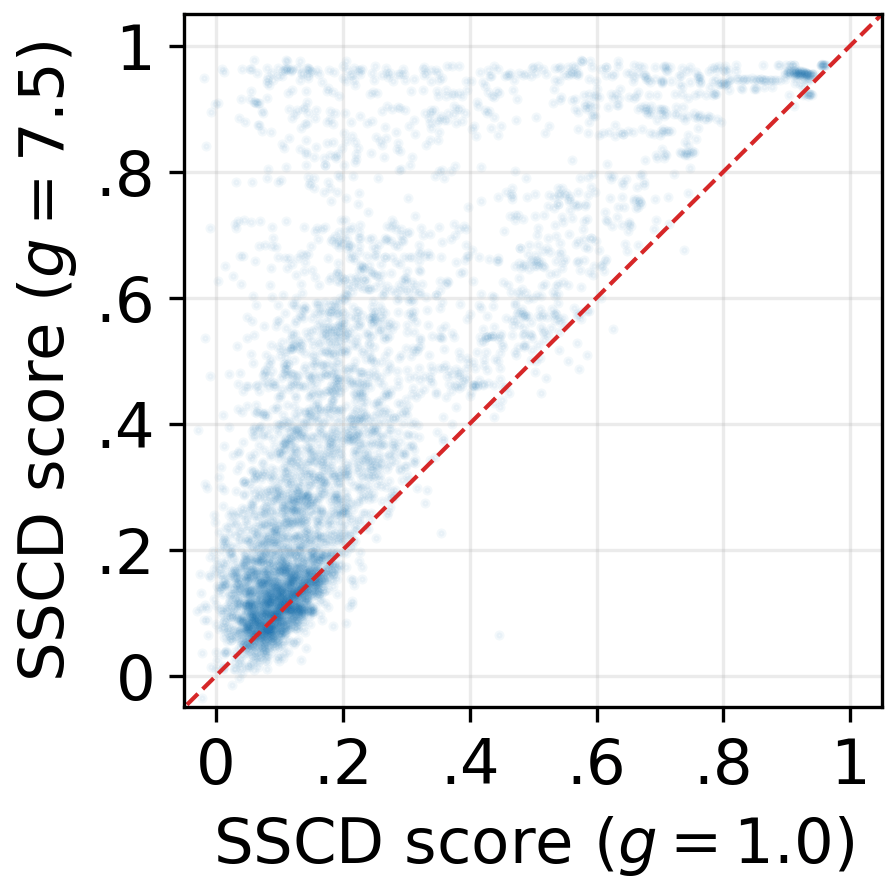
- Without extra guidance, memorized cases do look like overfitting (the model’s errors are small).
- But with strong guidance (the common setting people actually use), the model’s early errors get bigger, not smaller. That’s surprising—and it means memorization isn’t only caused by classic overfitting during training.
- Early “overestimation” is the real culprit.
- Guidance acts like turning the “prompt-following” knob too high, too early.
- In the first steps, the model doesn’t just head toward the right image—it overshoots it, acting as if it’s extra sure the training image is the answer.
- Technically, the conditional prediction (the part that uses the text prompt) injects a lot of information from the training image into the process right away. The stronger the guidance scale, the stronger this injection.
- This creates a “gravitational pull” toward the memorized image.
- Because the model stuffs in too much of the training image very early, different random starts quickly become similar. The “internal canvases” from different seeds collapse onto nearly the same path.
- The model loses randomness too soon, so there isn’t enough variety to explore different possible images. Everything gets pulled toward the memorized picture.
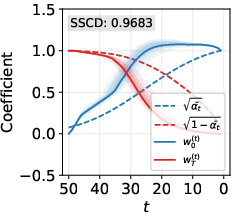
- A step-by-step breakdown shows randomness vanishes too fast.
- In theory, early steps should still be mostly random, and the training‑image-like content should grow gradually.
- In memorized cases with strong guidance, the training‑image part grows much faster than it should, while the random part disappears too early.
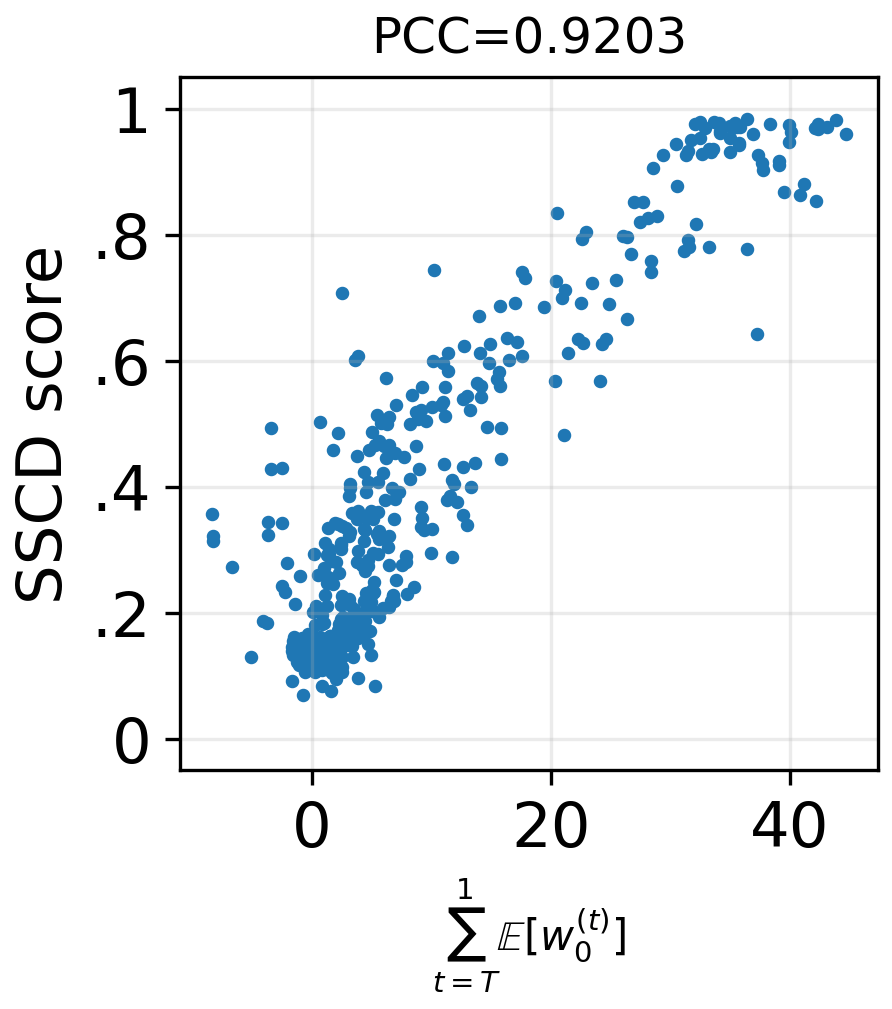
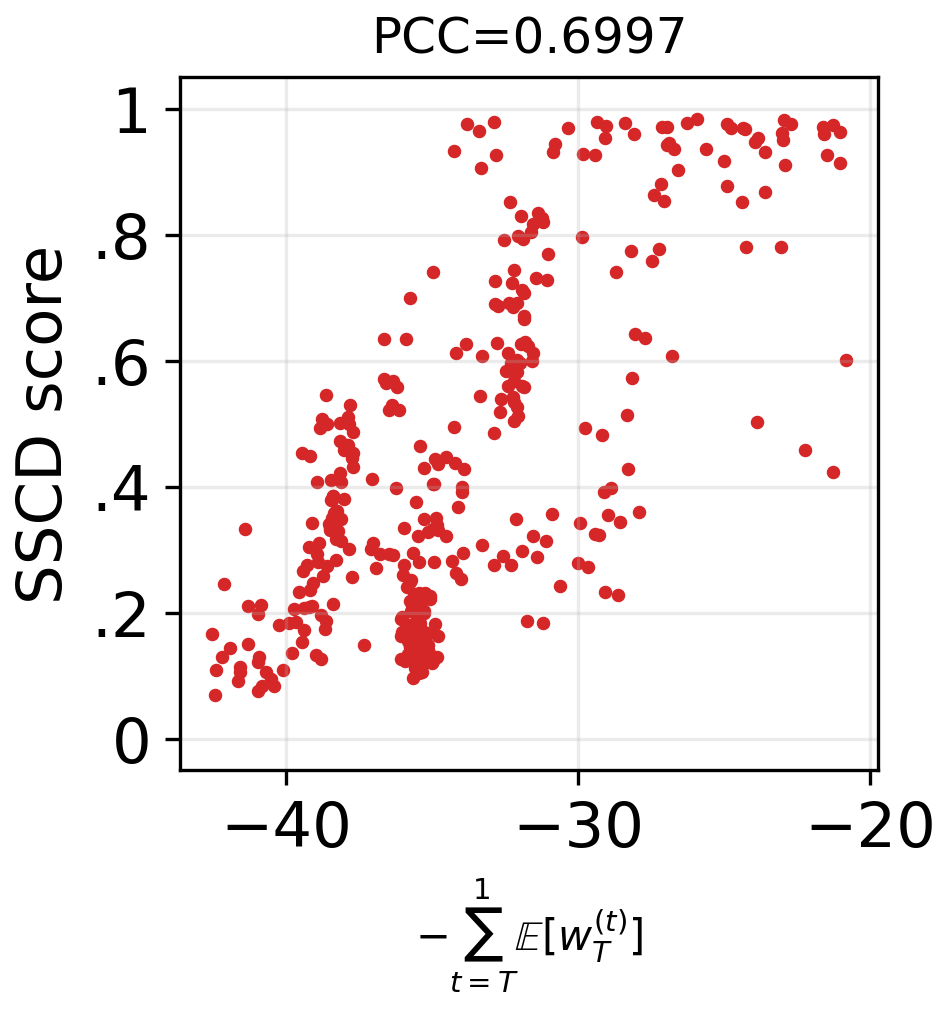
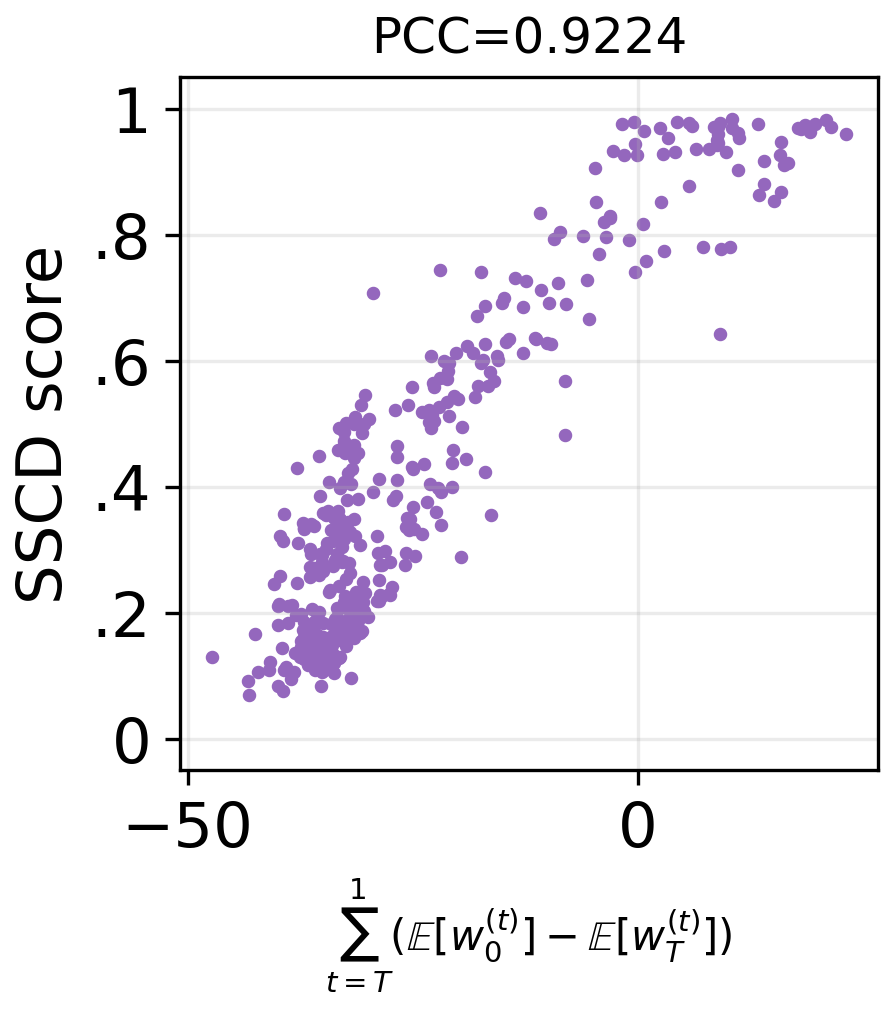
- These deviations match how severe the memorization is: the bigger the early shove toward the training image (and the quicker randomness is suppressed), the more likely the output is a near-copy.
Why is this important?
- It pinpoints the mechanism: Memorization mainly happens because the model gets too confident too early when guidance is strong—it overestimates the training image in its first steps.
- It explains practical observations:
- Turning guidance up improves prompt matching but also increases memorization risk.
- Disabling guidance in the earliest steps (and turning it on later) helps prevent copying. This matches other researchers’ fixes and explains why they work: keeping early steps more random preserves diversity and avoids the “magnet pull” toward a training image.
- It guides better tools:
- A known memorization detector measures how much the conditional (prompt-based) prediction differs from the unconditional one. This paper explains why that works: the size of that difference reflects how much training-image information is being injected.
What’s the takeaway for the future?
If we want safer, less copy-prone generators:
- Be careful with strong guidance in the early steps. Keep the “prompt-following knob” lower at the start and raise it later.
- Monitor how quickly randomness disappears during denoising. A healthy process gradually transitions from noise to structure, rather than jumping straight toward a specific training image.
- Use detection tools that watch how strongly the prompt is steering the model; big early pushes are a warning sign.
In short: Memorization happens because guidance makes the model too sure, too soon. That early overconfidence collapses variety and drags the model toward a training image. Controlling that early phase can dramatically reduce copying.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and unresolved questions that future work could address:
- Generalization beyond the tested models: Validate the proposed mechanism on a broader set of architectures (e.g., SDXL, PixArt, EDM/VDM, consistency models), training regimes (from-scratch vs. distilled), and modalities (audio, video, 3D diffusion), not only latent diffusion with VAE backbones.
- Sampler and schedule dependence: Systematically assess whether the “early overestimation” mechanism persists across samplers (DDPM, Euler(a), DPMSolver++, UniPC, Heun), noise schedules (cosine, EDM, linear), step counts, and stochasticity levels (DDIM eta > 0), and quantify any shifts in the “critical” early timesteps.
- Guidance variants and rescaling: Test whether the effect holds for alternative guidance strategies (classifier guidance, guidance rescaling, dynamic thresholding, ratio-preserving CFG, noise-offset), and quantify which formulations mitigate overestimation without degrading fidelity.
- Guidance scale sweep and tipping point: Empirically map memorization risk as a function of guidance scale g (fine-grained sweep) to identify critical thresholds, saturation regimes, and interactions with prompt specificity and model size.
- Negative prompts and multi-conditioning: Evaluate how negative prompts, multiple condition streams (e.g., ControlNet, T2I-Adapters), or structured conditioning (layouts, sketches) alter the injection of memorized content and diversity collapse.
- Text encoder effects: Study whether the mechanism depends on the choice of text encoder (e.g., CLIP vs. T5 in SDXL) or tokenizer, and how embedding anisotropy or prompt length influences overestimation.
- Pixel-space vs. latent-space diffusion: Test whether VAE compression accentuates the linear decomposability and overestimation; replicate analyses in pixel-space diffusion to isolate VAE-induced biases.
- Data scale, duplication, and frequency: Quantify how dataset size, duplicates, near-duplicates, caption quality, and instance frequency interact with early overestimation and memorization probability.
- Personalization and fine-tuning: Examine if DreamBooth/LoRA/HyperNetworks amplify or attenuate early overestimation and whether mitigation strategies transfer to personalized or domain-specific fine-tunes.
- Training-time factors: Probe how unconditional dropout rate, loss weighting over timesteps, noise schedule used in training, and data augmentation affect early-step overestimation at inference.
- Causality vs. correlation: Go beyond correlations by performing controlled interventions (e.g., per-step guidance scheduling, targeted attenuation of conditional components) to causally demonstrate that reducing early overestimation lowers memorization at comparable image quality.
- Theoretical guarantees: Provide formal analysis bounding the relationship between guidance scale g, denoising schedule, and the expected deviation of and from their theoretical curves, and connect these bounds to a provable increase in memorization risk.
- Layer- and mechanism-level attribution: Localize where in the UNet (e.g., cross-attention vs. residual blocks) the “ injection” arises, and determine whether early-step attention maps or feature channels are necessary/sufficient for the effect.
- Decomposition method robustness: Validate the linear decomposition under broader conditions (non-memorized prompts, different seeds, noise levels), quantify estimation error, and test alternative (possibly nonlinear) decompositions.
- Early-step detection and runtime control: Develop prompt- and step-adaptive monitors (e.g., thresholds on , cosine alignments, covariance-trace collapse) to flag impending memorization and automatically schedule guidance off/on.
- Metric robustness and calibration: Cross-validate SSCD with other replication detectors (e.g., copy-detection embeddings, perceptual hashes, crop/transform-resilient matchers), calibrate thresholds across domains, and analyze false positives/negatives and sensitivity to seed count.
- Privacy-risk quantification: Translate SSCD-based findings into concrete extraction/membership-inference risks (attack success rates, precision/recall), and assess how guidance scheduling changes privacy leakage under adversarial prompt optimization.
- Prompt properties and ambiguity: Characterize how prompt specificity, length, rare tokens, and semantic ambiguity modulate early overestimation and the probability of trajectory collapse to a single training instance.
- Temporal boundary of “early” denoising: Precisely estimate the transition timestep (or distribution over timesteps) where overestimation becomes harmful, and design algorithms to select a per-prompt transition point in real time.
- Quality–safety trade-offs: Quantify how proposed mitigations (e.g., reduced early guidance, rescaling) affect image quality, diversity, faithfulness to prompts, and downstream task performance to map actionable Pareto frontiers.
- Cross-resolution behavior: Test whether the mechanism strengthens or weakens at higher resolutions or multi-scale generation (e.g., SDXL refiner), where early-step latents may encode different amounts of structure.
- Generalization to non-memorized collapse: Distinguish memorization-driven collapse from benign mode collapse by testing whether similar diversity reductions occur without high SSCD-to-train and whether the proposed indicators can disambiguate them.
- Reproducibility and breadth: Expand beyond the 436-prompt subset by evaluating random prompt samples, different domains (photography, art, logos, medical), and broader seeds to assess external validity and boundary conditions.
- Open-source tooling: Release code to compute the proposed decomposition metrics and covariance-trace diagnostics so others can replicate, extend, and integrate early-overestimation monitoring during generation.
Glossary
- autoencoders: Neural networks that learn to encode data into a compressed latent representation and decode it back, often used to reduce dimensionality for diffusion. "latent space of well-trained autoencoders"
- CLIP embeddings: Vector representations produced by CLIP that encode text (or images) for conditioning generative models. "CLIP embeddings of text prompt and an empty string "
- classifier-free guidance: A conditioning technique that blends unconditional and conditional predictions to steer generation toward a prompt without using an external classifier. "using classifier-free guidance"
- conditional noise predictions: The model’s predicted noise when conditioned on a text prompt, used to guide denoising. "unconditional and conditional noise predictions, respectively"
- cosine similarity: A measure of directional alignment (angle) between vectors in latent space. "cosine similarity"
- cross-attention maps: Attention maps linking text tokens to image features, used for analyzing or detecting memorization. "analyzing cross-attention maps"
- decomposition of intermediate latents: Expressing an intermediate latent as a weighted sum of the clean latent and initial noise to study denoising dynamics. "a decomposition method for intermediate latents"
- denoised latents: Latent vectors at intermediate steps after partial denoising, used to analyze trajectory and diversity. "across denoised latents"
- denoising schedule: The theoretical time-dependent weights for how much signal versus noise should be present during denoising. "the theoretical denoising schedule"
- denoising trajectories: The paths that latents follow through space as noise is progressively removed. "causes denoising trajectories to converge quickly to "
- DDIM: Denoising Diffusion Implicit Models; a deterministic sampler that can speed up generation by skipping steps. "We use DDIM for sampling"
- DDPM: Denoising Diffusion Probabilistic Models; a stochastic diffusion sampler/framework for image generation. "DDPM sampling"
- diffusion probabilistic models: Generative models that learn to reverse a noising process to synthesize data. "diffusion probabilistic models"
- forward process: The procedure of progressively adding noise to data to produce a noised latent at a specified timestep. "a forward process gradually adds noise to "
- Gaussian distribution: The assumed distribution for transitions or noise in diffusion steps. "modeled as a Gaussian distribution with mean and variance "
- guidance scale: A scalar that controls the strength of conditional guidance relative to unconditional predictions. "where is the guidance scale"
- latent diversity: The variability across denoised latents from different noise seeds; its collapse indicates convergence toward memorization. "diminishes latent diversity"
- latent representations: Compressed vector encodings of images used by latent diffusion instead of pixels. "the notation refers to latent representations"
- latent space: The lower-dimensional vector space in which diffusion operates when using autoencoders. "a lower-dimensional latent space"
- latent space dynamics: The behavior and evolution of latent vectors across denoising steps. "analyze latent space dynamics"
- latent trajectories: Sequences of latent vectors across timesteps for a single generation. "forcing latent trajectories to converge"
- least-squares problem: An optimization to fit weights in a linear decomposition of latents. "least-squares problem "
- Markovian: A process where the next state depends only on the current state, not the history. "the forward process is a fixed Markovian"
- memorized prompts: Text prompts that cause the model to reproduce training images or highly similar outputs. "Memorized prompts inject into their noise predictions"
- noise predictor: The network component that estimates the noise present in a latent at a given timestep. " is a noise predictor trained to minimize the loss"
- overestimation: Excessively amplifying the contribution of a training image in early denoising, often due to guidance. "overestimation of the training image "
- Pearson correlation coefficient: A statistic measuring linear correlation between two variables. "Pearson correlation coefficient "
- principal component: A direction of maximal variance used to summarize collective denoising updates. "the first principal component of "
- probability landscape: The geometric view of the model’s learned data distribution in parameter or output space. "sharp regions of the probability landscape"
- reparameterization: A technique to express sampling as a deterministic transform of noise, aiding training and analysis. "via reparameterization"
- replication detectors: Tools that detect near-duplicate or copied images in outputs. "one of the strongest replication detectors"
- reverse process: The denoising procedure that reconstructs data from noise by inverting the forward process. "a reverse process generates "
- SSCD: A self-supervised descriptor used to measure image similarity for copy detection and memorization analysis. "we use SSCD"
- SSCD score: The aggregated similarity metric used to quantify memorization strength. "SSCD score"
- squared ℓ2 distance: The squared Euclidean distance, used to quantify errors between predicted and target latents. "Squared distance"
- stochasticity: Randomness in sampling procedures that can affect trajectory variability. "may introduce stochasticity"
- trace of the covariance matrix: The sum of variances across dimensions; here used to measure diversity across latents. "Trace of the covariance matrix of "
- transition timestep: A chosen step in denoising where guidance is toggled to mitigate memorization. "a transition timestep in denoising"
- unconditional noise predictions: The model’s predicted noise without conditioning on a text prompt. "unconditional and conditional noise predictions"
- variance schedule: The per-timestep variance parameters controlling how much noise is added/removed. " is the variance schedule"
Practical Applications
Immediate Applications
Below are concrete, deployable applications that leverage the paper’s findings about early-step overestimation and classifier-free guidance (CFG) as the mechanism behind diffusion memorization. Each item notes sectors, likely tools/workflows, and feasibility assumptions.
- CFG scheduler to reduce early overestimation (disable or downscale guidance in early steps)
- Sectors: software, creative industries, healthcare, education
- What: Introduce an inference-time schedule that sets g≈0 for the first K denoising steps, then gradually increases to the user-specified g (or uses lower g early and ramps up), preventing excessive injection of training content too soon.
- Tools/workflows: Diffusers/ComfyUI/AUTOMATIC1111 plugins; “Safe CFG” toggle in product UIs; presets like “anti-memorization mode.”
- Assumptions/dependencies: Access to per-timestep guidance control; may slightly reduce prompt adherence/“pop” in early steps and might need prompt-strength compensation.
- Prompt-level memorization risk scoring at inference-time
- Sectors: software, platform safety, compliance
- What: Score prompts by measuring the magnitude of text guidance signal ||εθ(xt, ec) − εθ(xt, e∅)|| at early timesteps (e.g., t=T), as justified by the paper’s theory; or by SSCD_generate collapse across seeds when internals are unavailable.
- Tools/workflows: On-the-fly UNet probe at t=T; n-seed sampling to check for collapse; deny/flag/auto-switch to Safe CFG if score exceeds threshold.
- Assumptions/dependencies: Access to conditional/unconditional predictions (white-box) or budget to sample multiple seeds (black-box); thresholds calibrated per model.
- Safety auditing dashboards for generative pipelines
- Sectors: software, MLOps, governance
- What: Continuous monitoring of memorization indicators: SSCD_train, SSCD_generate, Wen-style guidance magnitude, variance/trace of latent diversity, and the paper’s decomposition deviations (excess w0(t), premature wT(t) drop).
- Tools/workflows: “Memorization Monitor” integrated into CI for model updates; batch auditing of high-risk prompts; regression tests before releases.
- Assumptions/dependencies: Instrumentation access; curated prompt suites (e.g., prompts with known training exposure); SSCD or similar descriptor index.
- Auto-fallback generation policy for high-risk prompts
- Sectors: platform safety, product
- What: If risk score is high, apply mitigations: reduce early g, increase sampling steps modestly, add small stochasticity, or alter the text-conditioning schedule until collapse disappears.
- Tools/workflows: Policy engine in inference service; user-visible “re-rendering to avoid replication” notices; logs for compliance.
- Assumptions/dependencies: Acceptable latency overhead; business buy-in for adaptive safety policies.
- Model vetting before release or fine-tune deployment
- Sectors: industry R&D, academia, healthcare
- What: Use the paper’s metrics to compare base vs. fine-tuned models; flag LoRA/adapters that increase early overestimation and collapse across seeds.
- Tools/workflows: Pre-deployment checklist: compute decomposition-based deviations and SSCD_generate distributions on test prompts; reject or retrain risky variants.
- Assumptions/dependencies: Access to inference internals; representative probe prompts.
- Legal/compliance artifacts demonstrating anti-memorization controls
- Sectors: policy, legal, enterprise procurement
- What: Generate audit reports showing memorization risk scores, CFG schedules used, and before/after comparisons; archive evidence of safeguards against verbatim reproduction.
- Tools/workflows: Compliance exports from safety dashboards; signed model cards noting CFG schedules and SSCD thresholds.
- Assumptions/dependencies: Stakeholder agreement on metrics (e.g., SSCD threshold ≥0.75); compatibility with internal governance.
- “Diversity-preserving” presets for creative tools
- Sectors: creative industries, advertising, design
- What: Offer user-facing modes that increase output variation across seeds by preserving early randomness (reduced early g; optional slight noise reintroduction).
- Tools/workflows: UI toggles; gentle default schedules tuned per model to balance diversity and fidelity.
- Assumptions/dependencies: Users accept minor changes in style/faithfulness; presets validated on common use-cases.
- Red-teaming playbooks focused on early-step behavior
- Sectors: security, platform safety, academia
- What: Attack simulations that try to elicit memorization; evaluate first-step estimate x̂0(T) similarity, trajectory collapse, and guidance magnitude spikes to detect risky prompts/models.
- Tools/workflows: Red-team scripts that probe early denoising; reports with the paper’s correlation-backed metrics.
- Assumptions/dependencies: Instrumented inference; compute to run multi-seed tests.
- Fine-tune hygiene for sensitive domains (e.g., medical, enterprise proprietary data)
- Sectors: healthcare, enterprise software
- What: During and after fine-tuning, audit early overestimation on domain prompts; ship with safer default CFG schedules; optionally block high-risk prompt templates.
- Tools/workflows: Fine-tune pipelines that include early-step probes and risk thresholds; deployment gates.
- Assumptions/dependencies: Organizational policy to prioritize privacy over slight quality loss; domain-specific prompt libraries.
- Black-box API guardrails using output-collapse detection
- Sectors: SaaS platforms, education
- What: For APIs without UNet access, detect memorization risk by measuring SSCD_generate across a small number of seeds; if collapse is detected, reissue with safer CFG via available API knobs (if any), or refuse.
- Tools/workflows: Client-side sampling wrapper; budget-aware multi-seed tests (e.g., 3–5 seeds).
- Assumptions/dependencies: API exposes guidance scale or similar control; cost constraints.
Long-Term Applications
These applications require model/API changes, research, or standardization beyond immediate deployment, but are natural extensions of the paper’s mechanisms and metrics.
- Guidance mechanisms that avoid early overestimation by design
- Sectors: software, research
- What: Replace linear CFG with normalized/orthogonalized guidance (e.g., project conditional prediction to avoid magnitude inflation along memorized directions; cap or adaptively scale g using deviation signals).
- Tools/workflows: New guidance layers/heads; adaptive g(t) driven by w0(t)/wT(t) deviations and diversity traces.
- Assumptions/dependencies: Architectural access; empirical tuning across domains; potential retraining.
- Training-time regularizers against early overestimation
- Sectors: research, industry R&D
- What: Add losses that penalize excessive conditional magnitude at early timesteps, enforce adherence to theoretical schedules, or maximize early diversity while preserving fidelity later.
- Tools/workflows: Multi-objective training with schedule-adherence penalties; curriculum that emphasizes stable early denoising.
- Assumptions/dependencies: Retraining cost; calibration of regularization strength to avoid quality degradation.
- Formal “memorization risk score” standard for model cards and certifications
- Sectors: policy, standards bodies, procurement
- What: Standardize interpretable metrics (e.g., SSCD_generate percentiles, early-step guidance magnitude, schedule deviation) and require them in model disclosures and audits.
- Tools/workflows: Benchmarks and public leaderboards; certification programs (e.g., “Low Replication Risk”).
- Assumptions/dependencies: Community consensus on metrics/thresholds; regulator adoption.
- Privacy-conscious diffusion for sensitive data (healthcare, finance)
- Sectors: healthcare, finance, government
- What: Architectures and protocols that provably bound training-data reconstruction risk by constraining early-step behavior; combine with differential privacy or privacy auditing tailored to diffusion dynamics.
- Tools/workflows: DP-aware noise schedules; early-step clipping/normalization; privacy audits targeting x̂0(T) and trajectory collapse.
- Assumptions/dependencies: Theory bridging early overestimation and membership inference risk; acceptable utility/privacy trade-offs.
- Cross-modality extensions (video, audio, 3D, code)
- Sectors: media, gaming, simulation
- What: Port the analysis and safeguards to non-image diffusion systems where conditional guidance similarly risks early collapse (e.g., text-to-video).
- Tools/workflows: Modality-specific SSCD-style descriptors and trajectory-diversity metrics; modality-aware g(t) schedules.
- Assumptions/dependencies: Robust copy-detection descriptors for each modality; access to conditional/unconditional predictors.
- Model-agnostic “memorization firewall” in serving stacks
- Sectors: platform infrastructure
- What: An inference layer that intercepts conditional calls, applies adaptive g schedules, tests for collapse, and enforces policies before returning results—usable across multiple model backends.
- Tools/workflows: Sidecar/proxy service with pluggable tests; caching of per-prompt risk scores.
- Assumptions/dependencies: Latency budgets; partial observability with closed models may limit effectiveness.
- Insurance and risk analytics for generative IP leakage
- Sectors: insurance, legal tech
- What: Quantify client exposure by running the paper’s metrics on their generative workflows; price policies based on measured replication risk and mitigation controls.
- Tools/workflows: Risk assessment SaaS with dashboards; periodic audits; incident forensics using early-step probes.
- Assumptions/dependencies: Market acceptance; standardized scoring.
- Dataset and prompt governance ecosystems
- Sectors: creator platforms, data licensing
- What: Market tools that let rights holders test if their works are likely to be reproduced (e.g., by probing early-step alignment when available) and request mitigation in deployed systems.
- Tools/workflows: Rights-holder portals; verification using descriptor-based search and risk signals from serving systems.
- Assumptions/dependencies: Cooperation from model providers; privacy-preserving verification protocols.
- Curriculum/schedule-aware architectures to preserve early diversity
- Sectors: research
- What: New UNet/scheduler designs that explicitly separate “exploration” (high-diversity early phase) from “commitment” (late fidelity) while maintaining prompt consistency.
- Tools/workflows: Hybrid samplers; learned schedulers that optimize diversity-fidelity trade-offs conditioned on prompt risk.
- Assumptions/dependencies: Training compute; generalization across prompts/domains.
- Educator- and child-safe generative platforms
- Sectors: education, family tech
- What: Platforms that architecturally minimize verbatim reproduction so students/children aren’t inadvertently shown copyrighted originals, using strict early-step constraints and risk gating.
- Tools/workflows: Default Safe CFG; collapse detection with re-rendering; policy explanations suitable for schools.
- Assumptions/dependencies: Usability/quality acceptable under stricter controls; procurement requirements.
Notes on feasibility across items
- Most immediate applications require access to UNet predictions at specific timesteps or multi-seed sampling; black-box APIs limit options to collapse detection and coarse guidance controls.
- SSCD thresholds and decomposition-based metrics must be calibrated per model/version; reported correlations were measured on SD v1.4-like systems and should be validated on target models.
- There is an inherent trade-off between early diversity and prompt adherence/visual “punch”; productization will often need prompt-strength compensation or mild later-step boosts.
- Adoption in regulated sectors depends on standardizing metrics and evidence collection, potentially via industry consortia or academic benchmarks.
Collections
Sign up for free to add this paper to one or more collections.