Provable Separations between Memorization and Generalization in Diffusion Models
Abstract: Diffusion models have achieved remarkable success across diverse domains, but they remain vulnerable to memorization -- reproducing training data rather than generating novel outputs. This not only limits their creative potential but also raises concerns about privacy and safety. While empirical studies have explored mitigation strategies, theoretical understanding of memorization remains limited. We address this gap through developing a dual-separation result via two complementary perspectives: statistical estimation and network approximation. From the estimation side, we show that the ground-truth score function does not minimize the empirical denoising loss, creating a separation that drives memorization. From the approximation side, we prove that implementing the empirical score function requires network size to scale with sample size, spelling a separation compared to the more compact network representation of the ground-truth score function. Guided by these insights, we develop a pruning-based method that reduces memorization while maintaining generation quality in diffusion transformers.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper studies why diffusion models (popular AI systems that make images, sounds, or other data) sometimes “memorize” their training examples instead of creating truly new things. The authors give math-based explanations of when and why memorization happens, and they show simple ways to reduce it without ruining image quality.
Think of a diffusion model like a clean-up machine: it learns how to remove noise from a messy picture until it looks like a real photo. If it memorizes, it’s like the machine just redraws exact pictures from its homework (the training set) instead of learning the general rules for drawing anything similar.
The big questions
- Why do diffusion models sometimes copy training examples instead of generalizing?
- Does the training objective itself push models toward memorization?
- How does the size and design of the neural network affect memorization?
- Can we reduce memorization while keeping good generation quality?
How did they study it? Methods and analogies
To keep things simple, here are the key ideas and terms with everyday analogies:
- Diffusion models: They learn to turn noisy data into clear data. Imagine trying to guess the original photo under heavy static; you learn to remove noise step by step.
- Score function: This is like a tiny arrow at every point in the noisy space pointing toward “more likely” data. The model learns to predict these arrows.
- Training loss (denoising score matching): This is the model’s homework: it adjusts itself to predict the correct arrows so it can remove noise. It’s computed using the training samples you have.
- Ground-truth score vs. empirical score:
- Ground-truth score: The “perfect” arrow directions you’d have if you knew the true data distribution.
- Empirical score: The arrow directions you get if you only use the training samples you collected. This can push the model to fit the exact training points (memorization).
The authors use two complementary lenses:
- Statistical separation (how the training objective behaves):
- They prove that, because we train on a finite dataset, the empirical score actually minimizes the training loss better than the ground-truth score.
- In other words, the homework is set up so that “copying” the training data can look better (in terms of the loss) than truly learning the general pattern.
They relate the loss difference to a quantity called Fisher divergence, which you can think of as a “distance” (based on arrow differences) between the empirical world (your dataset) and the true world (the real data distribution).
They show this gap is especially large:
- when the noise level is low (early denoising steps), and
- when the data has spread-out clusters (like different categories),
- and it doesn’t quickly vanish with reasonable dataset sizes in high dimensions.
- Architectural separation (how hard functions are to represent with a neural network):
- They prove that representing the empirical score well needs a network whose size grows with the number of training samples.
- But representing the ground-truth score can be done with a more compact network (when the true data is reasonably smooth).
- Why? The empirical score is “wigglier,” especially at low noise levels, so the network must be big to capture all those wiggles. The ground-truth score is smoother, so a smaller network can handle it.
They also analyze smoothness more directly:
- The empirical score can change very sharply (become very non-smooth) when noise is low. That tends to increase memorization.
- Regularization like weight decay (a common training trick that keeps weights smaller) limits how “wiggly” the network can be, which helps reduce memorization.
Finally, they test these ideas with:
- Math proofs,
- Experiments on synthetic Gaussian mixtures (simple clustered data), and
- Real image data (CIFAR-10) using diffusion transformers.
They also propose a pruning method: remove the least important attention heads (parts of the model) that operate at the small-noise steps—where memorization pressure is strongest—and then fine-tune the model.
What did they find?
Here are the main results and why they matter:
- The training objective favors memorization in practical settings:
- The loss measured on the training data is minimized by the empirical score (which chases the training points) rather than the ground-truth score (which generalizes).
- This “loss gap” can be large at early denoising times (low noise). That means the model is nudged to memorize when it’s learning those fine details.
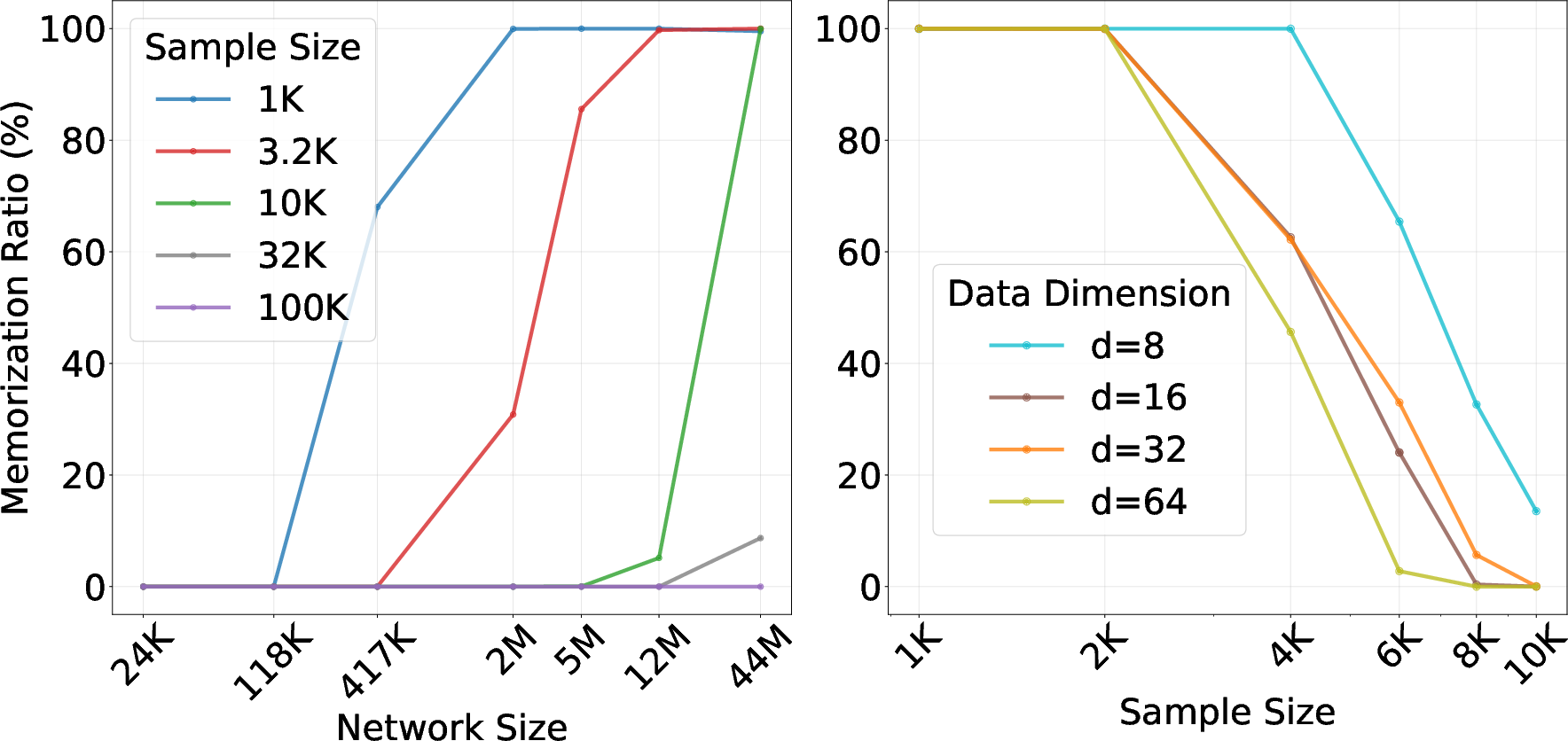
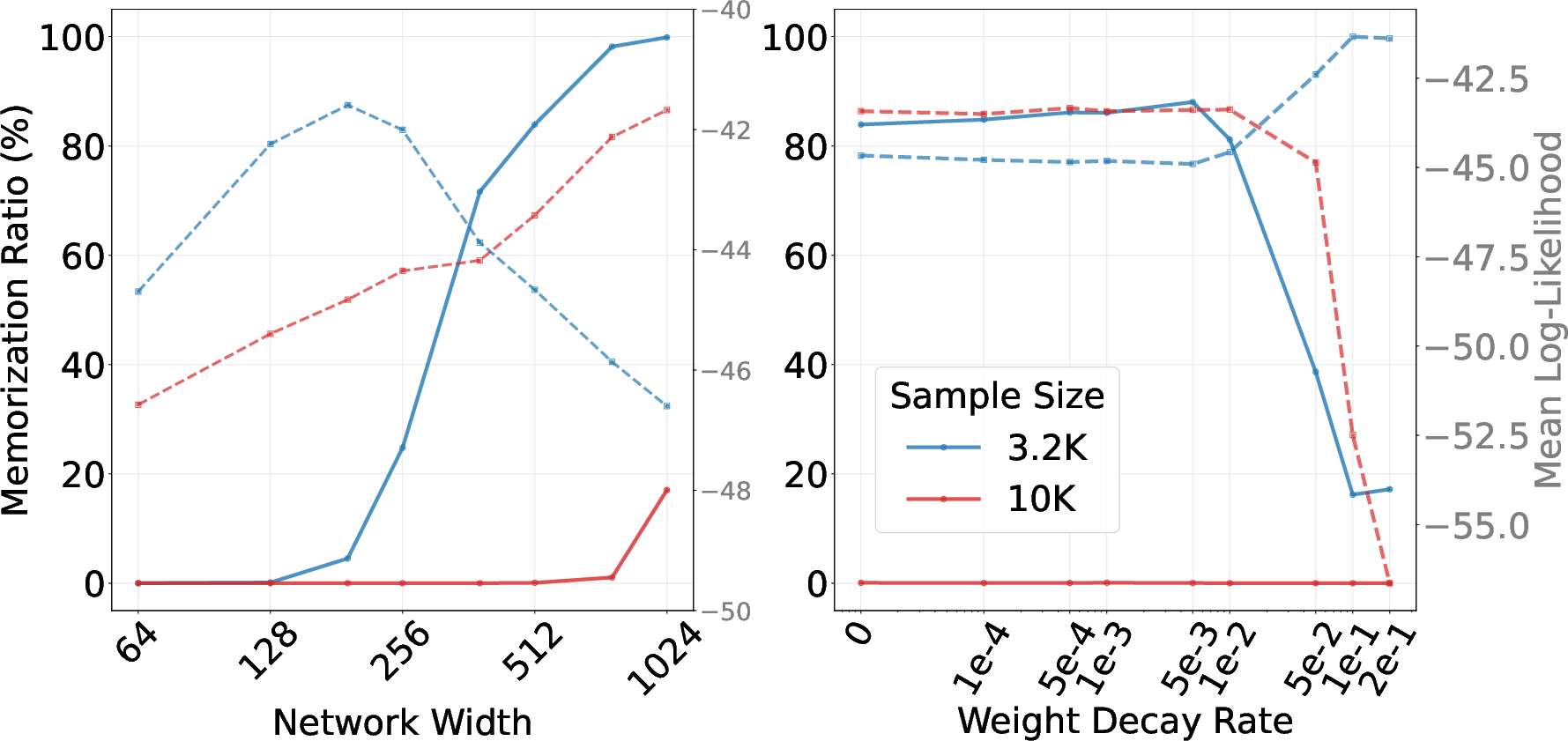
- Model size matters:
- Approximating the empirical score well needs a network that gets bigger as you add more training samples. That’s a strong signal that big models can memorize more if trained naively.
- The ground-truth score doesn’t need such growth; it can be represented compactly if the true data is smooth enough.
- Smoothness matters:
- At low noise, the empirical score is very “wiggly” and hard to learn without memorizing.
- Weight decay helps by discouraging overly sharp, spiky behavior in the learned function.
- Experiments support the theory:
- On synthetic mixtures: bigger networks memorized more; more data reduced memorization; with fewer samples, wide networks and weak regularization (low weight decay) increased memorization; proper width and weight decay improved generalization.
- On CIFAR-10: pruning low-importance attention heads (especially those used at low noise) reduced memorization and improved diversity (higher recall) while keeping image quality competitive (similar FID). Precision dipped slightly, which is expected because simply copying training images can artificially boost precision.
What does this mean going forward?
- Training-time bias: The commonly used training loss can unintentionally push models to copy training images when details matter most (low-noise steps). Recognizing this helps explain real-world privacy and originality concerns.
- Practical tips:
- Don’t just scale up model size without care; bigger can mean more memorization.
- Use weight decay or other smoothness controls to avoid wiggly, overfit solutions.
- Prune model parts that mostly operate during low-noise steps, then fine-tune—this can reduce memorization while keeping quality.
- Impact:
- Better understanding leads to safer, more creative generative models that respect privacy and originality.
- The theory offers a foundation for designing training objectives and architectures that encourage true generalization instead of copying.
Limitations and future directions
- The strongest math results focus on well-behaved (sub-Gaussian) data; heavy-tailed or very messy data needs more study.
- Experiments are promising but not yet at the largest model scales; future work can test these ideas on bigger datasets and models and further refine pruning and regularization techniques.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following items summarize what remains unresolved and where further research could make concrete progress:
- Extension beyond sub-Gaussian Hölder densities: the theory assumes has a sub-Gaussian Hölder density bounded away from zero; it is unknown whether the statistical and architectural separations (and their rates) persist for heavy-tailed, multi-scale, or low-density (near-manifold) regimes that are common in real datasets.
- General mixture models: lower bounds on
Loss-Gapare derived for mixtures with equal priors and common covariance (and separation ). It is open how the gap scales for unbalanced mixtures, component-specific covariances, overlapping modes, or continuous manifolds, and whether similar separations hold without strong separation assumptions. - Tightness of bounds and sample complexity: only lower bounds are provided for
Loss-Gap. Upper bounds, matching rates, and precise finite-sample conditions under which training prefers the empirical score over the ground-truth score (as functions of , , , , ) are not characterized. - Discrete-time training and alternative noise schedules: the analysis is for a continuous-time VP SDE. It is unclear how the separation results change under discrete-time training, cosine or sub-VP schedules, and noise-prediction parameterizations used in practice.
- Optimizer-induced bias: the claim that strong optimizers (e.g., Adam/AdamW) “drive” models toward the empirical score is not formalized. A principled analysis of how optimization dynamics and learning rate schedules interact with
Loss-Gapto shape memorization is missing. - Architectural approximation beyond feedforward ReLU: approximation results are for fully connected ReLU networks. Whether network size must scale with for UNets and Transformers (with skip connections, convolutional structure, and attention) remains unproven.
- Intrinsic-dimension-aware bounds: ground-truth approximation rates scale as , suffering the curse of dimensionality. Theory that leverages low intrinsic dimensionality or manifold hypotheses to yield dimension-free bounds is not developed.
- Data separation assumptions in Lipschitz analysis: the Lipschitz constant bound for the empirical score relies on pairwise separation of training points. Real datasets often contain near-duplicates and dense clusters; probabilistic, data-dependent versions of these bounds are needed.
- Training-time diagnostics: there is no method to estimate
Loss-Gapor Fisher divergence in practice. Developing unbiased or low-variance estimators to monitor memorization during training (especially at small ) is an open direction. - Objective design: it is unclear which modifications to denoising score matching (e.g., reweighting the time integral, excluding very small , adding smoothness regularizers tied to ) provably reduce
Loss-Gapwithout harming sample quality. - Weight decay theory: while weight decay empirically mitigates memorization, formal guarantees connecting weight decay to controllable Lipschitz constants and to a reduced ability to approximate (especially as ) are missing.
- Pruning guarantees: the proposed small- head pruning lacks theoretical analysis linking head importance scores, the pruned model’s function class, and a provable decrease in capacity to approximate the empirical score.
- Pruning design space: only one-shot attention-head pruning with a specific small- importance definition is tested. Open questions include optimal head selection criteria, layer-wise pruning strategies, structured vs. unstructured pruning, and adaptive pruning schedules over .
- Evaluation metrics for memorization: the nearest-neighbor rule (1/9 threshold) is heuristic. More rigorous memorization/privacy metrics (e.g., membership inference risk, copy-detection with de-duplication, distribution-level memorization) and their correlation with
Loss-Gapshould be established. - Scaling to large models and datasets: experiments are limited (e.g., DiT on 5k CIFAR-10 samples). It remains to test whether the separations and pruning benefits hold for large-scale models (UNet-based SD/DiT), text-conditioned generation, audio, and molecular domains.
- Conditional and guided diffusion: the theory does not cover conditional models or classifier-free guidance. How conditioning and guidance (which often amplify small- effects) alter
Loss-Gapand architectural separation is unexplored. - Data duplication and curation: empirical links between duplicate prevalence, smoothness, and memorization are not analyzed. A theoretical treatment of how duplication changes Fisher divergence and practical guidelines for data curation are open.
- Early-stopping time : choosing is critical but ad hoc. There is no principled method to select (or time-weighting) to balance optimization stability, generalization, and reduced
Loss-Gap. - From existence to trainability: approximation results are existential. Whether typical training pipelines can realize the compact ground-truth approximators (and systematically avoid the high-capacity empirical approximators) is unaddressed.
- Privacy and IP risk quantification: while memorization is linked to privacy/IP concerns, the paper does not quantify the risk or provide formal guarantees that pruning/regularization reduce model extractability or copyright exposure.
Practical Applications
Immediate Applications
Below are applications that can be deployed with current tools and model training pipelines, using the paper’s theoretical insights and pruning method.
- Mitigation of memorization in deployed diffusion models via pruning
- What: Apply one-shot pruning of attention heads in Diffusion Transformers (DiTs) with small-t saliency scoring, followed by short fine-tuning, to reduce replication of training data while preserving quality.
- Sectors: Software (image/video generation), Creative industries, Healthcare (medical imaging synthesis), Finance (document synthesis), Education (content generation platforms).
- Tools/Workflows:
- “Small-t head pruner” plugin for DiTs that ranks/prunes heads by importance under small-noise timesteps.
- Fine-tuning loop (hundreds to low thousands of steps) post-pruning.
- Automated A/B gating based on memorization ratio and FID/precision-recall.
- Assumptions/Dependencies: DiT architecture (or other attention-based backbones); ability to sample smaller t during scoring; access to fine-tuning compute; models trained with denoising score matching.
- Training-time regularization recipes that curb memorization without major quality loss
- What: Increase weight decay and reduce width (or overall parameter count) when sample size n is small or data are multi-modal; jointly tune time sampling to avoid overemphasis on very small t.
- Sectors: Software, Healthcare, Finance, Robotics (world-model generation), Energy (synthetic time-series).
- Tools/Workflows:
- “Memorization-aware” hyperparameter schedule: stronger weight decay early and at smaller t, conservative width for given n and d.
- Capacity planning checklist: model width/params ≤ linear in n to avoid converging to empirical score; early stopping heuristics at small t.
- Assumptions/Dependencies: Denoising score matching objective; availability of optimizer configs; moderate changes to training recipes.
- Memorization risk auditing and release gating
- What: Quantify and monitor a “memorization ratio” (nearest-neighbor criterion) and a loss-gap proxy to gate model releases and datasets.
- Sectors: Policy and Compliance, Healthcare (HIPAA), Creative (copyright/IP), Enterprise ML governance.
- Tools/Workflows:
- Batch-wise nearest neighbor ratio (training set vs generated samples).
- Loss-gap proxy: compute empirical denoising loss for learned score vs an EMA-smoothed/teacher score; monitor gap over training and at small t.
- Release checklist requiring thresholds (e.g., memorization ratio ≤ target).
- Assumptions/Dependencies: Access to training data for nearest-neighbor auditing; scalable approximate NN search; defined thresholds and governance processes.
- Model scaling and capacity planning guidelines
- What: Choose network size to avoid regimes where the network is expressive enough to approximate the empirical score (which scales with n) rather than the ground-truth score (compact).
- Sectors: Industry labs, Startups, Academia (benchmarking), Regulated industries (health/finance).
- Tools/Workflows:
- “n-aware” capacity selection: width/parameter count grows sublinearly in n unless there is strong regularization.
- Dataset-size-driven architecture templates and automatic width selection.
- Assumptions/Dependencies: Knowledge of training set size n, data dimension d, and feasible regularization strength; use with standard UNet/ViT/DiT backbones.
- Dataset curation with theory-backed priorities
- What: Reduce within-component variance and duplication; increase per-mode coverage to shrink Fisher divergence between empirical and true noisy distributions (reduces the loss gap).
- Sectors: Data operations across all industries using generative models.
- Tools/Workflows:
- De-duplication and per-class balancing.
- Targeted augmentation to densify sparse modes/components.
- Assumptions/Dependencies: Access to class labels or mode proxies; dedup infrastructure; basic data statistics.
- Safer consumer-facing generation modes
- What: Offer a “Diversity/Safe Mode” that toggles pruned heads and stronger weight decay at inference/training checkpoints to reduce training-data replicas.
- Sectors: Consumer apps, Creative suites, EdTech content tools.
- Tools/Workflows:
- Runtime model-switching between base and pruned checkpoints.
- UX toggle tied to governance metrics (memorization ratio).
- Assumptions/Dependencies: Maintaining multiple checkpoints; minimal performance hit is acceptable; simple UI integration.
- Standardized academic benchmarks and leaderboards for memorization
- What: Release benchmark suites based on well-separated mixture datasets and CIFAR-like subsets to evaluate memorization vs generalization trade-offs.
- Sectors: Academia, Open-source communities, Standards bodies.
- Tools/Workflows:
- Reproducible protocols: fixed n, d, mixture separation, small-t schedules.
- Public leaderboards reporting FID/precision-recall alongside memorization ratio.
- Assumptions/Dependencies: Community adoption; open datasets and scripts.
Long-Term Applications
These applications likely need further theory, scaling studies, or ecosystem development before broad deployment.
- Objective functions that directly penalize convergence to the empirical score
- What: Modify denoising score matching to include Fisher divergence-inspired regularizers that penalize fitting the empirical score under empirical P̂t rather than the true Pt.
- Sectors: All industries using diffusion training at scale; Academic ML theory.
- Tools/Workflows:
- New loss terms approximating Fisher(P̂t, Pt) or surrogates; small-t aware penalties; adaptive noise schedules.
- Assumptions/Dependencies: Efficient, unbiased estimators of divergence surrogates; stability and training throughput; theoretical guarantees.
- Architectures with built-in smoothness and time-aware capacity control
- What: Design networks whose Lipschitz constants are constrained (e.g., via spectral normalization/Jacobian penalties) and whose effective capacity varies with time t (more aggressive constraints at small t).
- Sectors: Software, Healthcare, Finance, Safety-critical systems.
- Tools/Workflows:
- Time-conditioned regularization layers; spectral norm control per block; adaptive pruning/gating schedules during training and sampling.
- Assumptions/Dependencies: Minimal quality loss; robust optimization; hardware-friendly implementations.
- Formal “generalization certificates” for diffusion models
- What: Provide certifiable guarantees that a trained model does not overfit to the empirical score (e.g., bounds on Fisher divergence, Lipschitz constants, and loss-gap metrics).
- Sectors: Policy/Regulation (AI governance), Enterprise compliance, Government procurement.
- Tools/Workflows:
- Audit pipelines producing certificates with statistically valid confidence intervals.
- Third-party verification services and model cards with memorization metrics.
- Assumptions/Dependencies: Standardized protocols; acceptance by regulators; efficient estimation at scale.
- Privacy-preserving diffusion training integrated with separation theory
- What: Combine differential privacy (DP-SGD) or privacy filters with capacity controls and small-t regularization to limit memorization while maintaining utility.
- Sectors: Healthcare, Finance, Legal, Public sector.
- Tools/Workflows:
- Privacy budgets co-optimized with width/weight-decay schedules; hybrid DP + pruning recipes; privacy-utility frontiers informed by theory.
- Assumptions/Dependencies: DP overhead manageable; clear utility targets; data access constraints.
- AutoML for memorization–generalization trade-off
- What: Automated selection of model size, weight decay, pruning ratio, and time sampling schedule given dataset properties (n, d, multimodality estimates, smoothness proxies).
- Sectors: MLOps platforms, Cloud providers, Enterprise AI.
- Tools/Workflows:
- Meta-learning of hyperparameter policies; small-t diagnostics; objective to minimize estimated loss-gap under quality constraints.
- Assumptions/Dependencies: Reliable proxies for smoothness and multimodality; meta-data collection across tasks.
- Domain-specific standards and testing for generative safety
- What: Sector-level standards setting minimum tests and thresholds for memorization (e.g., in medical imaging or financial document synthesis).
- Sectors: Healthcare regulators, Financial authorities, Consumer protection agencies.
- Tools/Workflows:
- Conformance testing suites with loss-gap/memorization ratio and coverage (recall) requirements; audit-ready reporting formats.
- Assumptions/Dependencies: Multi-stakeholder alignment; mapping to legal frameworks (e.g., HIPAA, GDPR, copyright law).
- Efficient, safe on-device generative models
- What: Use pruning (and potentially time-aware capacity control) to simultaneously reduce model size and memorization risk for edge deployment.
- Sectors: Mobile, AR/VR, Automotive HMI, Consumer devices.
- Tools/Workflows:
- Hardware-aware pruning; on-device small-t scheduling; safe mode by default for consumer apps.
- Assumptions/Dependencies: Sufficient on-device compute; acceptable latency; energy constraints.
- Extending theory to heavy-tailed and multimodal web-scale data
- What: Generalize statistical and architectural separation results beyond sub-Gaussian Hölder densities to text-to-image/video and multimodal web data.
- Sectors: Foundation model providers, Research labs.
- Tools/Workflows:
- New analyses under heavy-tailed and long-tail mixture regimes; training recipes adapted to those distributions.
- Assumptions/Dependencies: Novel mathematical tools; large-scale empirical validation.
Notes on applicability and limits:
- The paper’s guarantees hinge on assumptions like sub-Gaussian Hölder density and well-separated mixtures; real-world data may violate these (long tails, label noise), calling for robust extensions.
- The most sensitive regime for memorization is small t; methods that explicitly regularize or reduce capacity there (weight decay, pruning, time-aware constraints) are the most immediately impactful.
- Approximating or monitoring Fisher divergence directly may be costly at scale; practical proxies (loss-gap trends, small-t validation loss, nearest-neighbor ratios) are often necessary.
Glossary
- Adam: A stochastic optimization algorithm that adapts learning rates for each parameter using estimates of first and second moments of gradients. "strong optimizers, e.g., Adam and AdamW"
- AdamW: An Adam variant that decouples weight decay from the gradient-based update to improve generalization. "strong optimizers, e.g., Adam and AdamW"
- Asymptotic analyses: Analyses in the limit where quantities like sample size and dimension grow, often proportionally, to study behavior such as generalization. "For instance, asymptotic analyses, where both sample size and data dimension grow proportionally, have provided insights"
- Backward process: The reverse-time stochastic process in diffusion models used for denoising to generate samples from noise. "The backward process reverses the noise corruption in the forward process"
- Brownian motion: A continuous-time stochastic process with independent Gaussian increments, used to model noise in diffusion processes. "B_t is a standard Brownian motion"
- Curse of dimensionality: The phenomenon where statistical or computational complexity worsens rapidly with increasing dimension. "the convergence rate n{-1/d} is subject to the curse of dimensionality"
- Denoising score matching loss: The training objective for score-based diffusion models that matches the model’s score to the gradient of the noisy data log-density. "we estimate the score function by minimizing the following denoising score matching loss:"
- Diffusion models: Generative models that learn to reverse a noise-adding process to synthesize data samples. "Diffusion models have emerged as one of the most powerful families of generative models"
- Diffusion Transformers (DiTs): Transformer-based architectures tailored for diffusion models to parameterize the score or denoising network. "We propose a one-shot pruning method for trained Diffusion Transformers (DiTs)"
- Early-stopping time: A small positive lower bound on diffusion time used during training to avoid instability due to score blow-up. "Note that t_0 is an early-stopping time to prevent score blow-up"
- Empirical data distribution: The discrete distribution placing equal mass on observed training points. "we denote \hat{P}{\rm data} = \frac{1}{n} \sum{i=1}n \mathds{1}_{x_i} as the empirical data distribution"
- Empirical score function: The score of the noisy empirical distribution (often a Gaussian mixture), which minimizes the empirical denoising loss and can induce memorization. "Consequently, \hat{P}_t induces the empirical score function defined as"
- FID: Frechet Inception Distance, a metric that measures similarity between generated and real images via Gaussian statistics in a feature space. "in addition to memorization ratio and FID, we adopt precision and recall"
- Fisher divergence: A discrepancy measure between distributions based on the squared difference of their score functions. "We relate Loss-Gap to the well-known Fisher divergence"
- Forward process: The noise-adding process in diffusion models that gradually corrupts data with Gaussian noise. "we adopt a continuous-time description, where the forward process is"
- Frobenius norm: A matrix norm equal to the square root of the sum of squares of all entries. "‖A‖2 and ‖A‖{\rm F} denote its spectral norm and Frobenius norm, respectively"
- Gaussian mixture: A distribution composed of a weighted sum of Gaussian components. "is a Gaussian mixture with mean and variance dependent on time t"
- Generalization bound: A bound on the performance gap between empirical and population objectives, often under the true data distribution. "A generalization bound evaluates the deviation of ∇ log \hat{p}_t from ∇ log p_t under the ground-truth data distribution P_t"
- Ground-truth score function: The gradient of the log-density of the true (noisy) data distribution, which defines the ideal reverse-time dynamics. "the ground-truth score function does not minimize the denoising score matching loss"
- Hessian: The matrix of second-order partial derivatives of a scalar function, describing local curvature. "The Hessian of \log p_t(x_t) admits the following explicit form:"
- Hölder ball: The set of functions whose Hölder norm is bounded by a given radius. "The Hölder ball of radius B > 0 is defined as"
- Hölder norm: A measure of smoothness capturing bounded derivatives up to order s and a Hölder-continuous s-th derivative. "its Hölder norm is defined as"
- Lipschitz constant: The smallest constant bounding how much a function can change relative to input changes, controlling smoothness. "Define the Lipschitz constant of the empirical score function ∇ log\hat{p}_t(x_t) as"
- Mixture models: Distributions formed by combining multiple component distributions, often to represent multi-modality. "for mixture models, we provide a lower bound on the gap"
- Minimax optimal rate: The best possible convergence rate achievable by any estimator in the worst case over a function class. "is adopted in \citet{fu2024unveil} for establishing minimax optimal rate of conditional diffusion models"
- Neural architectural separation theory: A theoretical perspective comparing network complexity required to approximate empirical vs. true score functions. "Neural architectural separation theory: We establish bounds on neural networks approximating both ground-truth and empirical score functions"
- Non-asymptotic analysis: Finite-sample analysis that provides guarantees without taking limits in sample size or dimension. "We develop a non-asymptotic analysis that theoretically explains the emergence of memorization"
- Posterior distribution: The conditional distribution of latent variables given observations; here, the distribution of X_0 given X_t. "with respect to the posterior distribution of X_0 given X_t"
- Pruning: The removal of parameters or components (e.g., heads) from a network to reduce capacity or improve certain behaviors. "Pruning has been widely adopted for trained diffusion models"
- ReLU networks: Neural networks built with Rectified Linear Unit activations, often characterized by width, depth, and parameter counts. "we focus on feedforward ReLU networks"
- Score function: The gradient of the log-density of a distribution; central to score-based diffusion training. "we estimate the score function by minimizing the following denoising score matching loss"
- Score-based diffusion model: A generative framework that learns the score of noisy data distributions to reverse the diffusion process. "A score-based diffusion model aims to learn and sample from an unknown data distribution P_{\rm data} by estimating the score function"
- Spectral norm: The largest singular value of a matrix, measuring its maximum stretching factor. "‖A‖2 and ‖A‖{\rm F} denote its spectral norm and Frobenius norm, respectively"
- Sub-Gaussian Hölder density: A class of densities with sub-Gaussian tails and Hölder-smooth multiplicative factors. "A density function p is sub-Gaussian Hölder if"
- Sub-Gaussian norm: A norm characterizing the tail behavior of random variables/vectors that decay at least as fast as a Gaussian. "∥ξ∥{ψ_2} = \cO(1), where ∥·∥{ψ_2} denotes the sub-Gaussian norm"
- UNet: A convolutional neural network architecture with encoder-decoder skip connections, often used as a score network. "The estimator s is parameterized by a large-scale neural network such as a UNet"
- Weight decay: An L2-based regularization that penalizes large weights to control smoothness and reduce overfitting. "Weight decay controls the Lipschitz continuity of neural networks by penalizing the Frobenius norms of the weight matrices"
Collections
Sign up for free to add this paper to one or more collections.