Talk like a Graph: Encoding Graphs for Large Language Models
Abstract: Graphs are a powerful tool for representing and analyzing complex relationships in real-world applications such as social networks, recommender systems, and computational finance. Reasoning on graphs is essential for drawing inferences about the relationships between entities in a complex system, and to identify hidden patterns and trends. Despite the remarkable progress in automated reasoning with natural text, reasoning on graphs with LLMs remains an understudied problem. In this work, we perform the first comprehensive study of encoding graph-structured data as text for consumption by LLMs. We show that LLM performance on graph reasoning tasks varies on three fundamental levels: (1) the graph encoding method, (2) the nature of the graph task itself, and (3) interestingly, the very structure of the graph considered. These novel results provide valuable insight on strategies for encoding graphs as text. Using these insights we illustrate how the correct choice of encoders can boost performance on graph reasoning tasks inside LLMs by 4.8% to 61.8%, depending on the task.
- Knowledge graph based synthetic corpus generation for knowledge-enhanced language model pre-training, 2021.
- Statistical mechanics of complex networks. Reviews of modern physics, 74(1):47, 2002.
- Palm 2 technical report. arXiv preprint arXiv:2305.10403, 2023.
- Emergence of scaling in random networks. science, 286(5439):509–512, 1999.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020a.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020b.
- Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712, 2023.
- Exploring the potential of large language models (llms) in learning on graphs. arXiv preprint arXiv:2307.03393, 2023.
- Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022.
- Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416, 2022.
- Transformers as soft reasoners over language. arXiv preprint arXiv:2002.05867, 2020.
- Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- A generalization of transformer networks to graphs. arXiv preprint arXiv:2012.09699, 2020.
- On random graphs. Publicationes Mathematicae Debrecen, 6:290–297, 1959.
- Retrieval augmented language model pre-training. In International conference on machine learning, pp. 3929–3938. PMLR, 2020.
- Exploring network structure, dynamics, and function using networkx. Technical report, Los Alamos National Lab.(LANL), Los Alamos, NM (United States), 2008.
- Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021.
- Stochastic blockmodels: First steps. Social networks, 5(2):109–137, 1983.
- Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.
- Jie Huang and Kevin Chen-Chuan Chang. Towards reasoning in large language models: A survey. arXiv preprint arXiv:2212.10403, 2022.
- Patton: Language model pretraining on text-rich networks. arXiv preprint arXiv:2305.12268, 2023.
- Lambada: Backward chaining for automated reasoning in natural language. arXiv preprint arXiv:2212.13894, 2022.
- Decomposed prompting: A modular approach for solving complex tasks. arXiv preprint arXiv:2210.02406, 2022.
- Large language models are zero-shot reasoners. Advances in neural information processing systems, 35:22199–22213, 2022.
- The power of scale for parameter-efficient prompt tuning. arXiv preprint arXiv:2104.08691, 2021.
- Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474, 2020.
- What makes good in-context examples for gpt-3333? arXiv preprint arXiv:2101.06804, 2021.
- Attending to graph transformers. arXiv preprint arXiv:2302.04181, 2023.
- Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
- Graphworld: Fake graphs bring real insights for gnns. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp. 3691–3701, 2022.
- Unifying large language models and knowledge graphs: A roadmap, 2023.
- Automatic prompt optimization with” gradient descent” and beam search. arXiv preprint arXiv:2305.03495, 2023.
- A decade of knowledge graphs in natural language processing: A survey. arXiv preprint arXiv:2210.00105, 2022.
- Generate & rank: A multi-task framework for math word problems. arXiv preprint arXiv:2109.03034, 2021.
- Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Can language models solve graph problems in natural language? arXiv preprint arXiv:2305.10037, 2023.
- Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837, 2022.
- Large language models as optimizers. arXiv preprint arXiv:2309.03409, 2023.
- Examining the effects of degree distribution and homophily in graph learning models, 2023.
- Deep bidirectional language-knowledge graph pretraining, 2022.
- Natural language is all a graph needs. arXiv preprint arXiv:2308.07134, 2023.
- Graph-bert: Only attention is needed for learning graph representations. arXiv preprint arXiv:2001.05140, 2020.
- Exploring the mit mathematics and eecs curriculum using large language models. arXiv preprint arXiv:2306.08997, 2023a.
- Siren’s song in the ai ocean: A survey on hallucination in large language models. arXiv preprint arXiv:2309.01219, 2023b.
- A survey of large language models. arXiv preprint arXiv:2303.18223, 2023.
- Least-to-most prompting enables complex reasoning in large language models. arXiv preprint arXiv:2205.10625, 2022a.
- Large language models are human-level prompt engineers. arXiv preprint arXiv:2211.01910, 2022b.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Talk like a Graph: Encoding Graphs for LLMs”
1) What is this paper about?
This paper looks at how to help LLMs—computer programs that read and write text—reason about graphs. A graph is just a way to show connections, like a map of who is friends with whom, roads between cities, or links between web pages. Because LLMs mainly read text, the authors ask: how should we write (encode) a graph as text so the LLM can understand it and answer questions about it?
2) What questions are the researchers trying to answer?
The paper focuses on three main questions, explained in simple terms:
- How should we write down a graph as text so an LLM can use it well?
- How should we ask the question (the prompt) so the LLM knows exactly what to do?
- Does the shape or structure of the graph (for example, a chain vs. a web) change how well the LLM can reason about it?
They also ask: do bigger LLMs do better, and do small changes in wording or examples make a big difference?
3) How did they study this?
The researchers treated the LLM like a “black box” (they didn’t change the inside of the model). They only changed the text they gave it. They tried two main things:
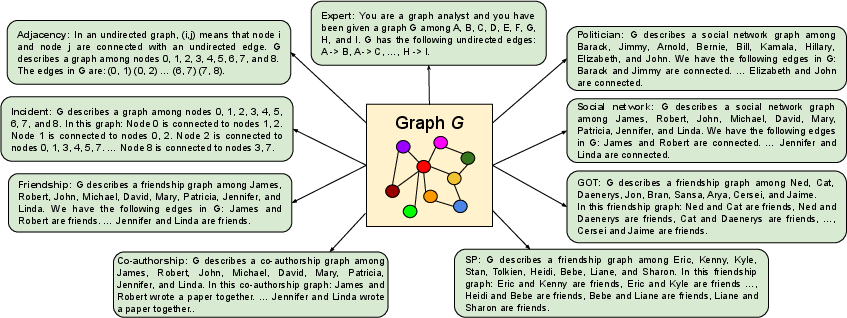
- Different ways to write the graph as text (graph encodings). Examples include:
- Listing edges as pairs of numbers (like “(0, 1), (1, 2)”)—think of this as a very math-like list.
- Writing neighbors of each node (like “Node 2 is connected to 0, 1, 3…”).
- Using natural language with names and relationships (like “James and Mary are friends”).
- Different ways to ask the question (prompting). They tested:
- Zero-shot: just ask the question directly.
- Few-shot: show a few example questions and answers first.
- Chain-of-thought (CoT): ask the model to explain its steps.
- Variations like zero-shot CoT (“Let’s think step by step”) and a “bag prompting” tip for graphs.
They built a set of simple graph tasks, called GraphQA, to test the LLM. These are basic but important building blocks for harder problems. For example:
- Edge existence: Is there a connection between A and B?
- Node degree: How many connections does a node have?
- Counting nodes or edges
- Listing neighbors (connected nodes)
- Cycle check: Does the graph contain a loop?
- Disconnected nodes: Who is NOT connected to this person?
They also tried different kinds of graphs: random graphs, “star” graphs (one central hub), “path” graphs (a straight chain), complete graphs (everyone connected to everyone), and other real-world-like generators. Finally, they tested different model sizes to see if bigger models help.
4) What did they find, and why is it important?
The short version: details matter—a lot.
- LLMs struggle with even basic graph tasks if the text is written in the wrong way. Just because an LLM is great with regular text doesn’t mean it automatically understands graphs written as sentences.
- The way you write the graph changes performance a lot. For example:
- Writing “who is connected to whom” (incident encoding) helped on tasks like finding a node’s degree.
- Using numbers for nodes (like node 0, node 1) helped with counting and math-like tasks.
- Using human names sometimes helped for simple yes/no tasks.
- The way you ask the question matters. Asking in a natural, everyday way (“How many friends does Alex have?”) sometimes worked better than using abstract graph terms (“What is the degree of node i?”).
- Simple tasks don’t always need step-by-step reasoning. For many basic tasks, a straightforward prompt (zero-shot) worked better than “Let’s think step by step.” But for more complex tasks, examples and chain-of-thought helped.
- Bigger models generally did better, but size alone didn’t fix everything. If the graph was encoded poorly or the question was unclear, even large models failed.
- The shape of the graph matters. The model’s accuracy changed a lot across different graph types. For example:
- It often assumed cycles exist (a bias), so it did well on graphs that usually have cycles (like complete graphs) and poorly on graphs that never have cycles (like path graphs).
- Graphs with fewer edges (shorter descriptions) were easier because there was less distracting text.
- LLMs are bad at reasoning about things that are not explicitly written. For example, listing who is NOT connected (disconnected nodes) was very hard, because the graph text mostly mentions what does exist, not what doesn’t.
- Picking the right encoding and prompt can boost accuracy by a lot—sometimes from a few percent up to over 60% improvement, depending on the task.
Why this matters: If you want to use LLMs to analyze networks—social media, recommendation systems, fraud rings, and more—you can’t just paste in graph data randomly. You must write it in the “language” the LLM handles best for your specific task.
5) What’s the impact of this research?
This work gives practical guidance for anyone who wants LLMs to reason about graphs using only text:
- Choose your graph encoding based on the task (e.g., use numeric nodes for counting, neighbor lists for degree-related questions).
- Ask questions in natural and clear ways; sometimes “real-world” phrasing beats tech-speak.
- Provide short, focused graph descriptions to reduce distraction.
- Add a few examples and step-by-step reasoning for harder tasks.
- Be aware of model biases (like assuming cycles are common).
- Don’t expect the model to infer missing information unless you prompt or encode it explicitly.
The authors also release GraphQA, a benchmark to help the community test and improve how LLMs handle graph reasoning. Overall, the study shows that with the right “translation” of a graph into text and careful prompting, LLMs can do much better—opening the door to smarter tools for understanding complex networks in everyday domains.
Collections
Sign up for free to add this paper to one or more collections.