- The paper introduces a method that uses dynamic GPU clusters and pervasive context management to significantly reduce LLM inference execution time.
- It employs the Parsl-TaskVine software stack to optimize resource allocation, enabling flexible and efficient dynamic workflow execution.
- Experimental results demonstrate a 98.1% reduction in execution time and improved throughput, validating its scalable performance gains.
Introduction
In "Scaling Up Throughput-oriented LLM Inference Applications on Heterogeneous Opportunistic GPU Clusters with Pervasive Context Management," researchers analyze the resource requirements of LLM training and inference serving and introduce a novel solution for scaling throughput-oriented inference applications using heterogeneous opportunistic GPU clusters. Opportunistic resources enable dynamic allocation in GPU clusters, providing computational flexibility without the cost and delay of purchasing dedicated hardware. This solution incorporates a pervasive context management technique that optimizes inference application scaling, resulting in substantial execution time reduction.
Opportunistic Resource Utilization
Opportunistic resource utilization leverages the availability of unallocated or idle resources in GPU clusters. This approach circumvents the limitations and costs associated with static allocations, significantly reducing the time and computational resources required for LLM inference applications. Through pervasive context management, applications harness these opportunistic resources, dynamically adapting to cluster states.
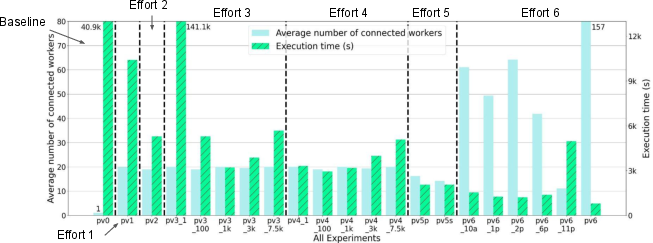
Figure 1: Average Number of Connected Workers and Execution Time of All Experiments.
Pervasive Context Management
The essence of pervasive context management is the reuse of computational context across tasks, minimizing initialization overhead and maximizing execution efficiency. This management technique facilitates effective resource utilization, addressing challenges like spiky data movement and unpredictability. By retaining shared computational states efficiently, the technique enhances throughput-oriented application scaling.
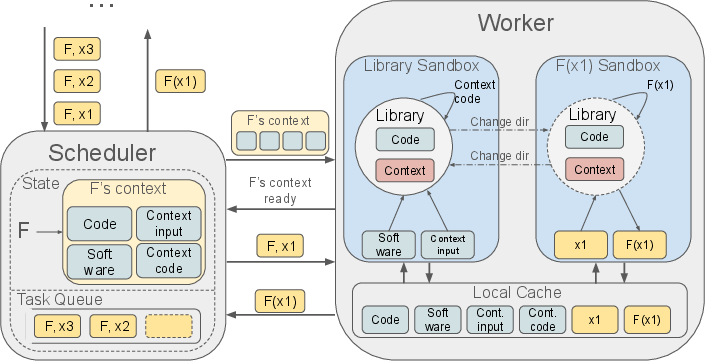
Figure 2: Context Reuse with Pervasive Context Management.
Implementation Strategy
The implementation utilizes the Parsl-TaskVine software stack, combining efficient resource management with dynamic workflow execution. Parsl provides a flexible Python-based environment for function-centric computational expression, while TaskVine manages data-intensive workflow execution, optimizing resource distribution and task scheduling. The strategy includes establishing an opportunistic resource pool with minimal resource units per task, promoting resource conservation and adaptability.
Experimental Evaluation
Experiments demonstrate the scalability and performance gains achieved through pervasive context management on opportunistic GPU clusters. The evaluation includes incremental efforts showcasing execution time reduction across diverse task configurations and resource conditions. The results highlight a reduction in execution time by 98.1%, with significant evidence of throughput improvement and resilience against dynamic resource availability.
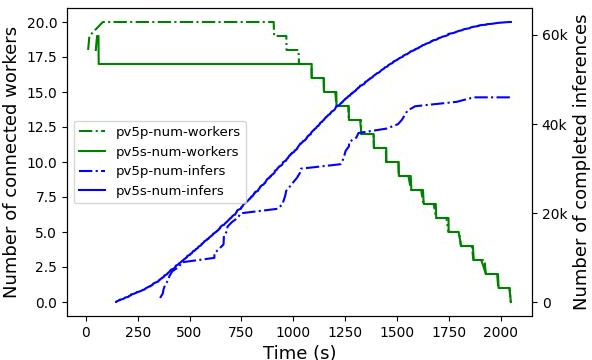
Figure 3: Effect of Pervasive Context on Throughput.
Conclusion
This research offers a scalable solution for throughput-oriented LLM inference applications on heterogeneous opportunistic GPU clusters. The integration of opportunistic resources and pervasive context management leads to substantial performance enhancements, enabling researchers and practitioners to reduce execution time and optimize resource utilization efficiently. Future developments may focus on extending the context management framework to broader computational environments and exploring its applicability to varied AI applications.