- The paper introduces the RLSP framework, demonstrating how decoupling exploration from correctness triggers emergent search behaviors in LLMs.
- It employs a three-stage protocol—supervised fine-tuning, exploration rewards, and outcome verification—to achieve significant performance boosts (e.g., 23% improvement on MATH-500).
- The framework’s meta-cognitive techniques, such as backtracking and self-verification, present scalable, token-efficient approaches for enhancing LLM reasoning.
Emergence of Search and Reasoning in LLMs via RLSP
Introduction
The paper "On the Emergence of Thinking in LLMs I: Searching for the Right Intuition" (2502.06773) investigates the algorithmic underpinnings of reasoning in LLMs, with a focus on the emergence of search-like behaviors that underpin advanced reasoning. The authors introduce the Reinforcement Learning via Self-Play (RLSP) framework, a post-training paradigm designed to induce systematic search and "thinking" behaviors in LLMs, and provide both theoretical and empirical evidence for its efficacy. The work is motivated by the observation that recent LLMs, such as OpenAI's o-series, Google's Gemini Thinking, and Deepseek R1, exhibit behaviors characteristic of Large Reasoning Models (LRMs), which perform explicit reasoning during inference.
RLSP Framework: Design and Rationale
The RLSP framework is a three-stage post-training protocol:
- Supervised Fine-Tuning (SFT): When available, models are fine-tuned on demonstrations of the reasoning process, either from human annotations or synthetic traces (e.g., from tree search).
- Exploration Reward: During RL, an exploration reward is introduced to encourage diverse and efficient reasoning behaviors, independent of solution correctness.
- Outcome Verifier: RL training is conducted with an outcome verifier that provides a binary correctness signal, ensuring that reward hacking is mitigated.
A key innovation is the decoupling of exploration and correctness signals during PPO-based RL, with careful balancing to optimize both reasoning quality and efficiency. The exploration reward can be as simple as incentivizing longer responses (i.e., more intermediate steps), or more sophisticated, such as LLM-based creativity scoring.
Theoretical Motivation
The RLSP framework is theoretically motivated by recent results demonstrating that chain-of-thought (CoT) reasoning provably increases the computational power of transformers, with the number of intermediate steps directly impacting expressivity [merrill2023expresssive]. The authors argue that as problem difficulty increases, models must search over a larger space of rationales, and that explicit reward signals for exploration are necessary to synthetically generate novel CoT trajectories not present in the training data. This synthetic data generation via self-play enables continuous self-improvement, as the model learns from its own diverse reasoning traces.
Empirical Analysis: Emergence of Search Behaviors
The empirical evaluation focuses on mathematical reasoning tasks, using Llama-3.1-8B-Instruct and Qwen2.5-32B-Instruct as base models. The RLSP framework is shown to induce several emergent behaviors, including backtracking, exploration of alternative ideas, verification, and self-correction, even when the exploration reward is simply proportional to response length.
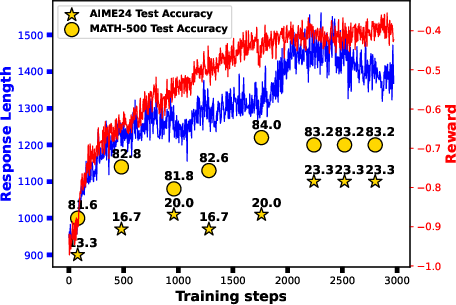
Figure 2: Reward, response length, and AIME24 accuracy during RL training with PPO and a length-based exploration reward. Increased response length is necessary (but not sufficient) for search behavior and improved reasoning.
Notably, the RLSP-trained models achieve a 23% improvement on MATH-500 with Llama-3.1-8B-Instruct and a 10% improvement on AIME 2024 with Qwen2.5-32B-Instruct, compared to their respective baselines. The emergence of search behaviors is robust across model families, sizes, and domains, provided that exploration rewards are present. In contrast, pure RL with only outcome-based rewards fails to induce such behaviors in most settings, except for specific model/data combinations (e.g., Qwen2.5-7B-Instruct on math).
Qualitative Analysis: Emergent Reasoning Trajectories
The paper provides detailed qualitative evidence of emergent behaviors. RLSP-trained models exhibit:
- Backtracking: Explicitly revisiting and revising earlier steps upon detecting inconsistencies.
- Self-Verification: Systematic checking of intermediate results before finalizing answers.
- Exploration of Alternatives: Trying multiple solution paths and comparing outcomes.
- Self-Correction: Identifying and correcting errors in reasoning chains.
These behaviors are not observed in standard CoT or self-consistency sampling without RLSP, even when using the same token budget. The qualitative trajectories demonstrate that RLSP enables models to perform meta-reasoning over their own outputs, a property not reliably induced by SFT or outcome-only RL.
Implementation Details and Practical Considerations
The RLSP framework is implemented using PPO, with the reward function:
$\mathcal{R}(q, o) = \alpha \cdot \mathds{1}[\mathrm{Ver}(q, o) = \mathrm{True}] + (1-\alpha) \cdot \mathcal{R}_{\mathrm{ex}}(q, o)$
where α is a tunable hyperparameter (set to 0.8 in experiments), and Rex is the exploration reward (e.g., proportional to response length or LLM-judged creativity). The outcome verifier provides a sparse but high-precision correctness signal, while the exploration reward provides a dense signal to guide the model toward richer reasoning trajectories.
The authors note that the exploration reward must be carefully balanced to avoid reward hacking (e.g., meaningless repetition for length). In practice, the combination of SFT and RLSP yields the best results, but SFT can be omitted if reward engineering is sufficiently robust.
Comparative Analysis and Token Efficiency
RLSP-trained models outperform self-consistency and majority-vote baselines under equivalent token budgets, achieving higher accuracy with fewer samples. This demonstrates that RLSP not only improves reasoning quality but also enhances token efficiency, a critical consideration for deployment at scale.
Implications and Future Directions
The findings have several implications:
- Scalability: RLSP is a scalable framework for inducing search and reasoning in LLMs, applicable across domains and model sizes.
- Synthetic Data Generation: By incentivizing exploration, RLSP enables models to generate novel CoT data, facilitating continuous self-improvement.
- Generalization: Emergent behaviors induced by RLSP are robust to changes in model architecture and pretraining data, provided that exploration is rewarded.
- Limitations: Emergent behaviors do not guarantee correctness; further work is needed to align exploration with solution quality, especially for small models or limited compute.
The authors speculate on future research directions, including finer-grained test-time search, the impact of context length, and the possibility of inducing higher-order reasoning abilities (e.g., abstraction, tool creation) via further extensions of the RLSP paradigm.
Conclusion
This work provides a principled framework and empirical evidence for the emergence of search and reasoning behaviors in LLMs via RLSP. By decoupling exploration and correctness signals and leveraging RL with self-play, the framework enables models to synthesize novel reasoning trajectories and exhibit meta-cognitive behaviors such as backtracking and self-verification. The results suggest that RLSP is a promising direction for advancing the reasoning capabilities of LLMs, with broad implications for the development of LRMs and future AI systems.