- The paper's main contribution is the introduction of ProRL, which extends reinforcement learning training to unlock novel reasoning pathways in LLMs.
- It combines strategies like KL divergence control, reference policy resetting, and dynamic entropy management to overcome short-term sampling limitations.
- Results show significant pass@1 improvements across diverse tasks, highlighting enhanced performance in math, code, STEM, and logic puzzles.
Expanding Reasoning Boundaries in LLMs: The Role of ProRL
The paper "ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in LLMs" introduces a methodology - Prolonged Reinforcement Learning (ProRL) - capable of enhancing reasoning capabilities in LLMs far beyond the sampling efficiency improvements typically achieved. ProRL combines techniques such as KL divergence control, reference policy resetting, and diverse task management to explore new solution spaces and achieve novel reasoning strategies that base models cannot access.
Methodological Innovations in ProRL
ProRL distinguishes itself by focusing on sustained reinforcement learning training that goes beyond short-term superficial gains. The methodology leverages existing RL algorithms like GRPO, optimized through additional strategies to mitigate entropy collapse and stabilize long-horizon training:
- Entropy Management: To combat premature entropy collapse, which restricts exploration, ProRL employs decoupled clipping and dynamic sampling from the DAPO algorithm. These techniques encourage broader exploration and maintain output diversity, critical for effective policy updates.
- KL Divergence with Resetting: Introducing a KL divergence penalty maintains entropy while ensuring stable divergence of the training policy from the reference. Periodically resetting the reference policy helps prevent stagnation, facilitating continuous model improvement over extended training durations.
These elements collectively ensure that ProRL can manage the computational complexities associated with prolonged training while achieving meaningful advancements in reasoning capabilities.
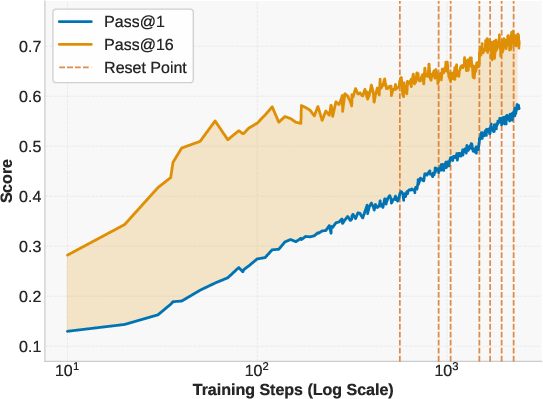
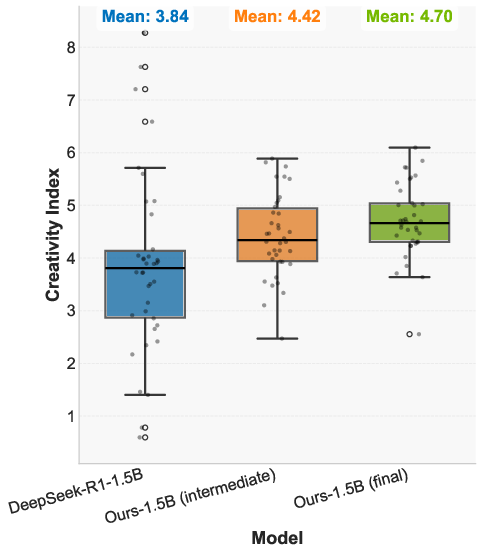
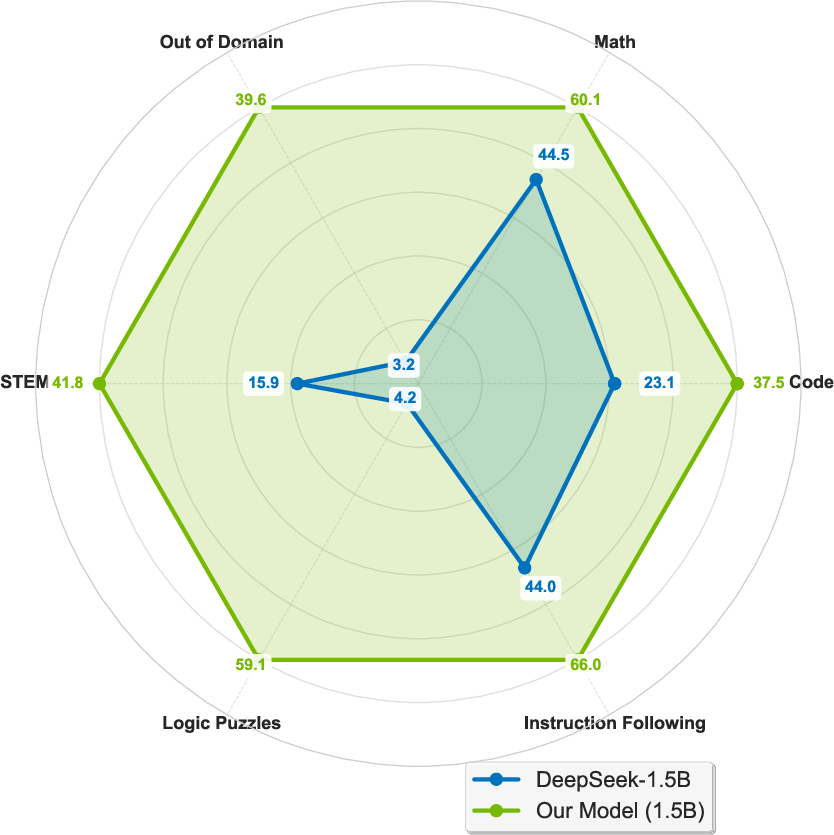
Figure 1: Benefits of prolonged reinforcement learning (ProRL). Left: Pass@1 and Pass@16 scales with ProRL training. Middle: ProRL leads to more novel solutions reflected by higher Creativity Index. Right: The model greatly surpasses the base model across diverse tasks.
Implementation of Nemotron-Research-Reasoning-Qwen-1.5B
The practical application of ProRL is demonstrated through the Nemotron-Research-Reasoning-Qwen-1.5B model, which is trained using extensive RL over diverse problem domains including math, code, STEM, logic puzzles, and instruction following:
- Training Setup: Utilizing computational resources from NVIDIA-H100-80GB nodes, the training runs for 16k GPU hours, significantly enhancing the model's proficiency in reasoning tasks compared to its base model and achieving comparable results to larger models.
- Task Diversity: An expansive dataset covering five task domains with clear reward signals is used, promoting generalization and presenting rigorous RL algorithm evaluations across fundamentally different environments.
The results indicate substantial performance gains with average pass@1 improvements ranging from 14.7% in mathematical reasoning to 54.8% in logic puzzles, showcasing ProRL’s effectiveness in broadening reasoning boundaries.
Evaluating The Expanded Reasoning Boundaries
ProRL’s true impact comes through its capacity for reasoning expansions, particularly evident in domains where the base model struggles initially:
- Performance Metrics: Different evaluation benchmarks reveal three regimes of model performance: Diminish, Plateau, and Sustained gains. ProRL shows sustained performance improvements with prolonged training cycles, notably in complex domains such as code generation, where exploration over diverse instances is crucial.
- Discovering Novel Solutions: ProRL enables the emergence of genuinely new reasoning trajectories, evidenced by substantial shifts in reasoning accuracy distributions and the ability to generalize to out-of-domain tasks (Figure 2).
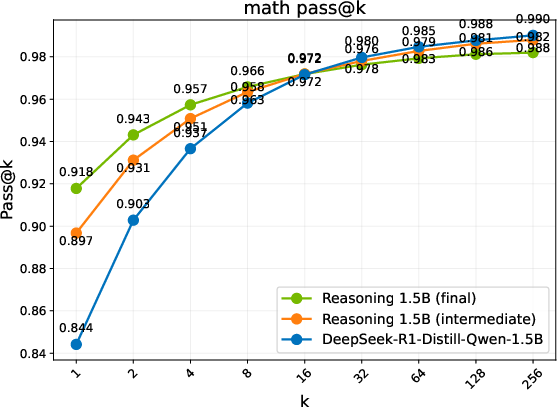
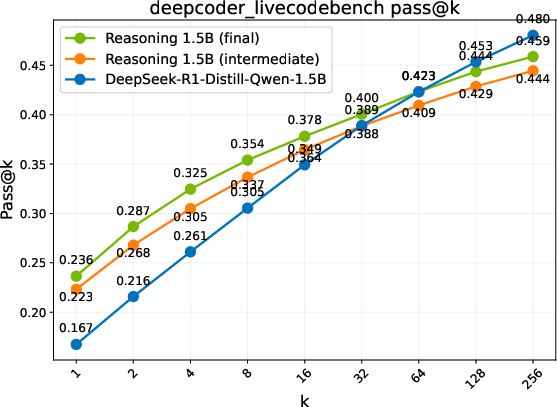
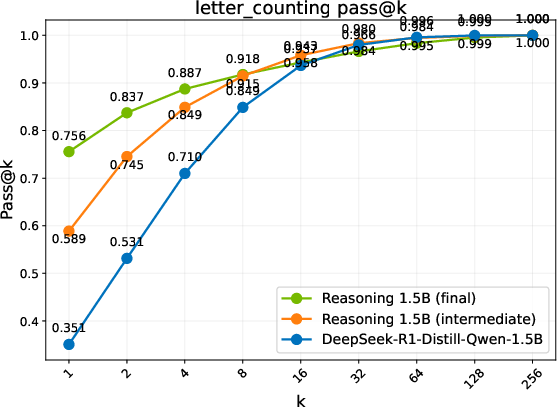
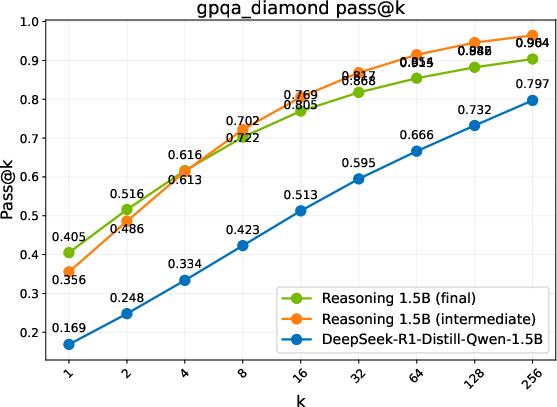
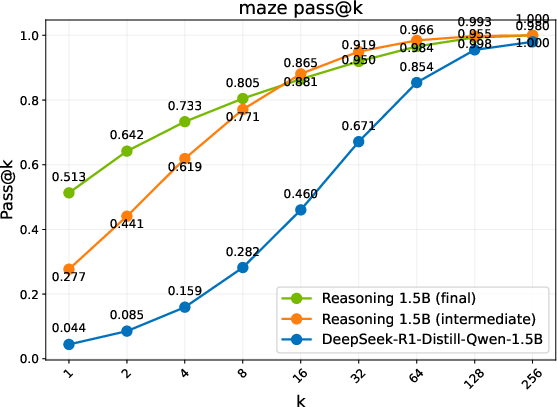
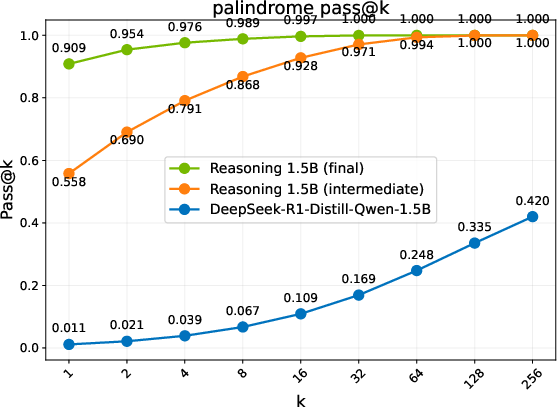
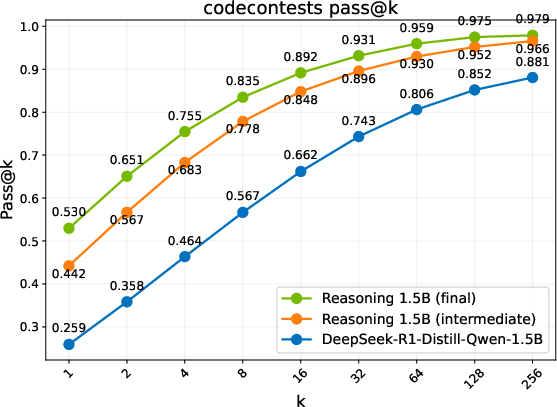
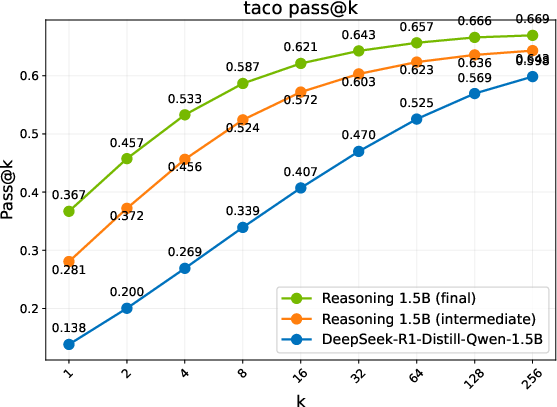
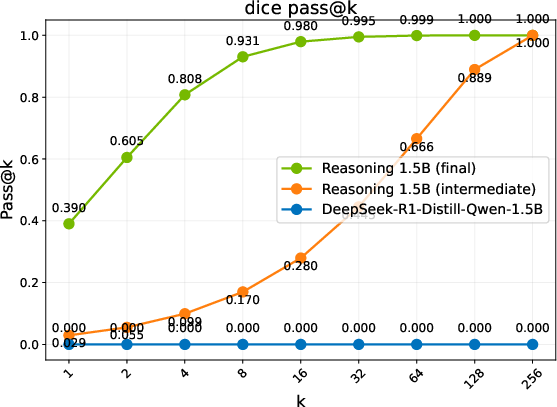
Figure 2: Pass@k comparison of the base model, an intermediate checkpoint, and the final RL-trained models. Trends are grouped into three regimes: Diminish, Plateau, and Sustained.
Broader Implications and Future Directions
This research dramatically challenges existing assumptions about RL's limitations in developing reasoning capabilities within LLMs. ProRL underscores the potential for sustained RL training to facilitate new pathways in reasoning, offering a foundation for future research into long-horizon RL methodologies. The findings suggest the necessity for models to explore extensively across diverse tasks to develop generalized reasoning capabilities.
In conclusion, ProRL establishes a clear precedent for future exploration in sustained reinforcement learning strategies, providing pathways for developing sophisticated and adaptable AI systems that can solve more complex and diverse reasoning challenges efficiently.