- The paper demonstrates the novel MSRL method that integrates multimodal (textual and visual) rewards to break the SFT performance plateau in chart-to-code generation.
- It employs a two-stage curriculum training strategy, initially optimizing for textual accuracy before introducing visual rewards to refine chart structure.
- MSRL achieves significant benchmark improvements, with performance gains of 6.2% and 9.9% on ChartMimic and ReachQA respectively, surpassing previous methods.
Breaking the SFT Plateau: Multimodal Structured Reinforcement Learning for Chart-to-Code Generation
Introduction
The paper addresses a notable challenge in chart-to-code generation—an application requiring models to convert complex visual charts into structured code. While Supervised Fine-Tuning (SFT) has been traditionally employed in this domain, its efficacy is limited upon reaching a performance plateau. The authors introduce Multimodal Structured Reinforcement Learning (MSRL) to transcend these limitations. By integrating both textual and visual feedback within a reinforcement learning framework, the MSRL method showcases a significant advancement in performance metrics on standard benchmarks such as ChartMimic and ReachQA.
Problem Identification and Dataset Construction
A key limitation identified is that SFT alone leads to a performance bottleneck due to its inability to leverage the potential of large-scale data optimally. To explore these constraints, the study constructs the largest chart-to-code dataset to date, comprising 3 million chart-code pairs sourced from real-world tables across arXiv papers. This comprehensive dataset enables a detailed examination of SFT's performance limitations at various scales.
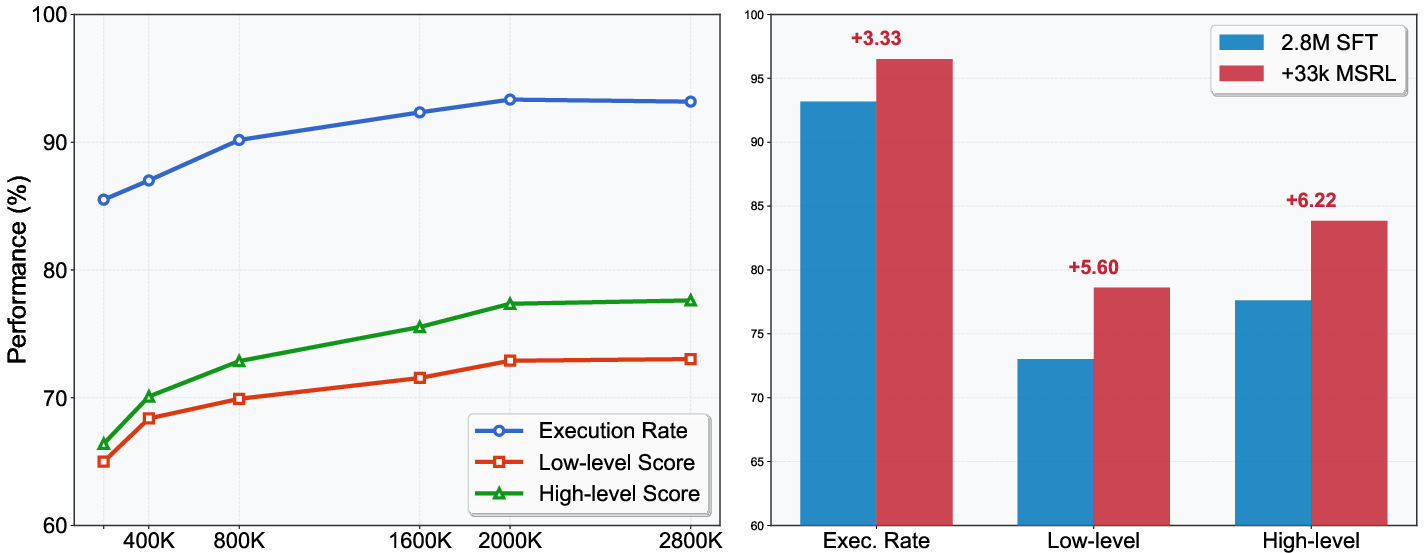
Figure 1: The SFT plateau and RL performance gain from our experiments.
Proposed Methodology: MSRL
Textual and Visual Reward Systems
MSRL employs a multi-granularity structured reward system to optimize model outputs. Textual rewards are derived from a rule-based evaluation of code fidelity across multiple perspectives, such as data accuracy and formatting consistency. To complement this, visual rewards are implemented via a model-based evaluation that quantifies the structural accuracy of generated images against their ground-truth counterparts. This dual approach ensures comprehensive feedback that accounts for both specific content details and the overall chart structure.
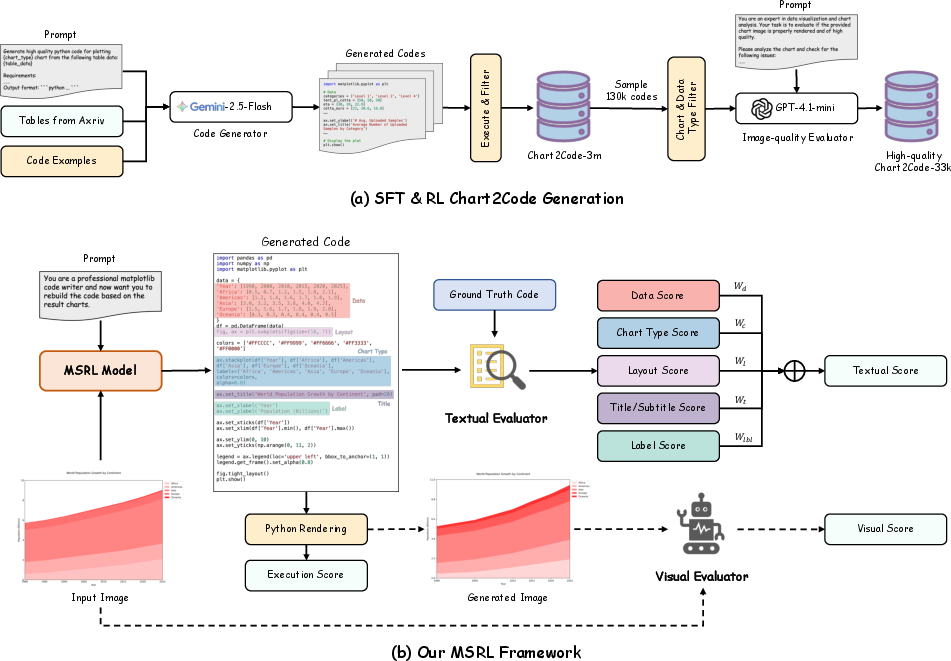
Figure 2: The data generation pipeline and our proposed MSRL framework.
Two-Stage Curriculum Training
To maintain training stability, MSRL adopts a two-stage curriculum training strategy. Initially, the model is trained exclusively on textual rewards to refine the generation of high-fidelity code. Subsequently, the training incorporates visual rewards to further align rendered chart structures with ground-truth images, thereby enhancing the model’s global context understanding and visual precision.
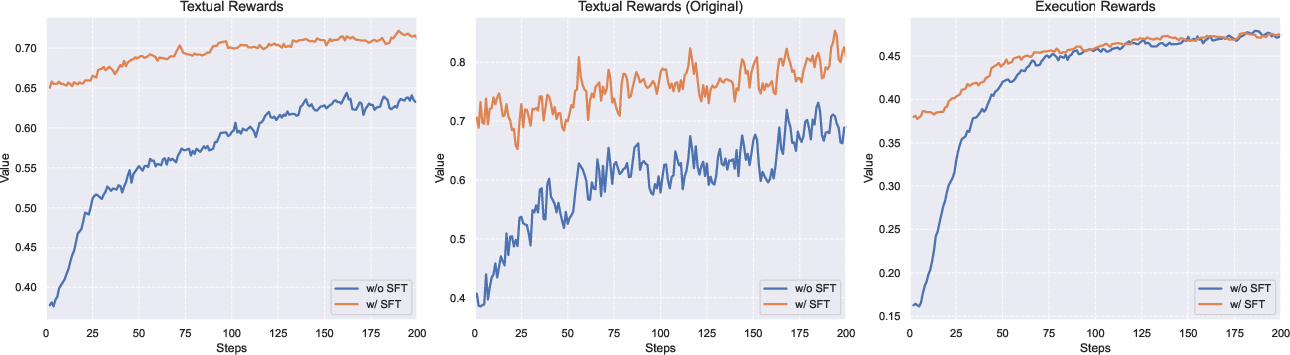
Figure 3: Comparison of textual reward and execution rate changes between baseline and SFT models during the RL stage.
Experimental Results
The MSRL framework breaks new ground by achieving state-of-the-art results on the ChartMimic and ReachQA benchmarks. Notably, MSRL demonstrated a 6.2% and 9.9% improvement over previous approaches in high-level performance metrics on these benchmarks, respectively. These advances result from MSRL's capacity to optimally utilize both the extensive dataset and the structured reinforcement learning approach.
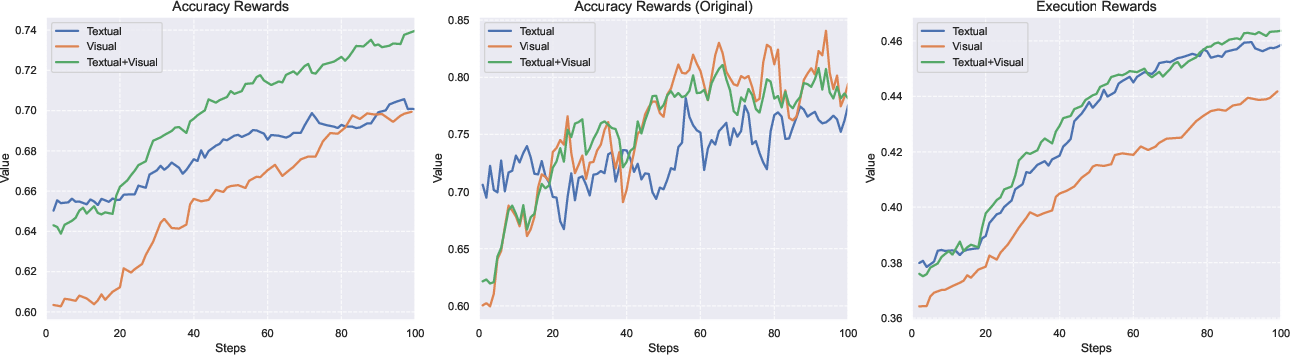
Figure 4: Comparison of reward gains during RL training with various reward settings.
Implementation and Evaluation
MSRL was executed on a baseline model, specifically Qwen2.5-VL-7B-Instruct, refined through structured fine-tuning followed by the MSRL method. Computational efficiency was ensured through staged training on GPU infrastructure, utilizing extensive hardware resources for reinforcement learning optimization. Evaluation against open-source and proprietary models demonstrated that MSRL not only rivals but occasionally surpasses larger proprietary systems such as GPT-4V and GPT-4o in chart-specific tasks.
Implications and Future Work
The introduction of MSRL highlights the potential of multimodal structured reinforcement learning in overcoming SFT limitations in chart-to-code applications. Beyond the immediate gains in performance, MSRL sets a precedent for future research to incorporate multimodal feedback systems in other domains demanding structured output generation from complex inputs. Further exploration into expanding visual reward capabilities and optimizing RL algorithms could drive continued innovation in this space.
Conclusion
The study successfully demonstrates that MSRL can significantly enhance chart-to-code generation tasks by effectively leveraging multi-granularity feedback. This achievement underscores the limitations of traditional SFT approaches and presents MSRL as a robust alternative that is both scalable and adaptable to various chart types and complexities. Through comprehensive dataset curation and innovative reward implementation, the authors have set a new benchmark in this rapidly evolving field.
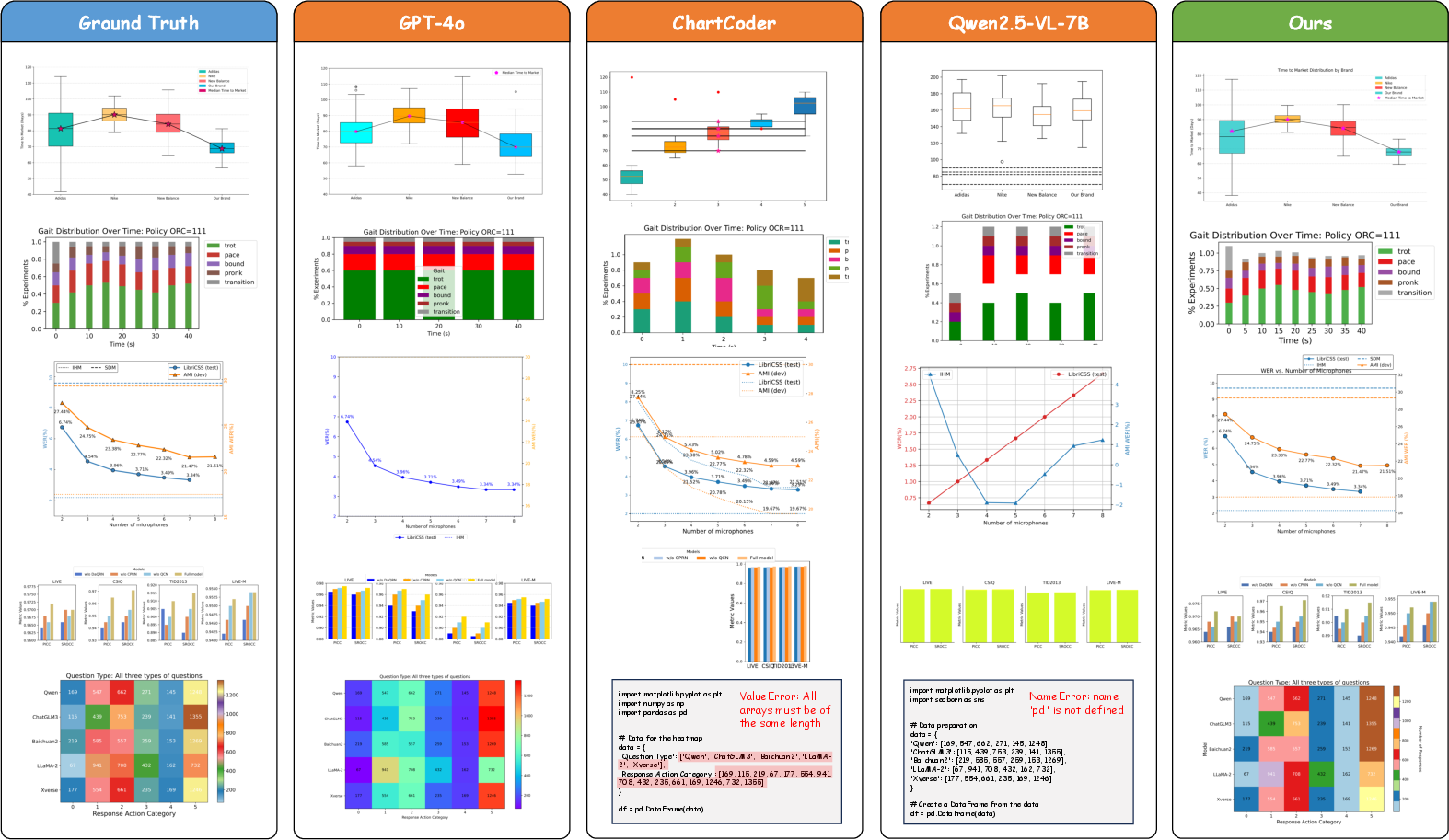
Figure 5: Showcasing charts generated by MSRL compared to proprietary and open-source MLLMs. The charts produced by MSRL align well with their ground-truth ones.

