Table2LaTeX-RL: High-Fidelity LaTeX Code Generation from Table Images via Reinforced Multimodal Language Models
Abstract: In this work, we address the task of table image to LaTeX code generation, with the goal of automating the reconstruction of high-quality, publication-ready tables from visual inputs. A central challenge of this task lies in accurately handling complex tables -- those with large sizes, deeply nested structures, and semantically rich or irregular cell content -- where existing methods often fail. We begin with a comprehensive analysis, identifying key challenges and highlighting the limitations of current evaluation protocols. To overcome these issues, we propose a reinforced multimodal LLM (MLLM) framework, where a pre-trained MLLM is fine-tuned on a large-scale table-to-LaTeX dataset. To further improve generation quality, we introduce a dual-reward reinforcement learning strategy based on Group Relative Policy Optimization (GRPO). Unlike standard approaches that optimize purely over text outputs, our method incorporates both a structure-level reward on LaTeX code and a visual fidelity reward computed from rendered outputs, enabling direct optimization of the visual output quality. We adopt a hybrid evaluation protocol combining TEDS-Structure and CW-SSIM, and show that our method achieves state-of-the-art performance, particularly on structurally complex tables, demonstrating the effectiveness and robustness of our approach.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching a computer to look at a picture of a table (like one you’d see in a PDF or textbook) and write clean, accurate LaTeX code that recreates that table. LaTeX is the standard way scientists and engineers write professional-looking documents, especially when they need perfect formatting. The goal is to turn table images into “publication-ready” LaTeX tables automatically, even when the tables are large and complicated.
What questions did the researchers ask?
They focused on simple versions of these questions:
- Can we build a system that converts table images into LaTeX code accurately, especially for complex tables with merged cells, nested headers, and math?
- How can we train such a system to care not just about the text it outputs, but also whether the final rendered table looks right?
- What’s a fair way to judge whether the generated tables are both structurally correct and visually faithful?
How did they approach the problem?
To make this work, the team combined a powerful “see-and-speak” AI model with smart training and evaluation strategies. Here’s what they did, explained in everyday language.
Building a big training set
- They crawled arXiv (a website with lots of scientific papers) to collect over 1.2 million pairs of table images and their LaTeX code.
- They cleaned the code (removed extra commands like colors and references) so the model could focus on table structure.
- They split tables into three groups by complexity:
- Simple: small, straightforward layouts.
- Medium: more merged rows/columns and 100–160 cells.
- Complex: very large (over 160 cells), with nested, irregular structures.
Teaching the model (supervised fine-tuning)
- First, they trained a multimodal LLM (an AI that can understand images and write text) to map from “table image” → “LaTeX code.”
- This phase is like regular teaching: show the correct answer and ask the model to learn to predict it.
- Problem: LaTeX often has multiple ways to write code that looks the same when rendered. Training only on exact text matches can mislead the model, especially for long, tricky tables.
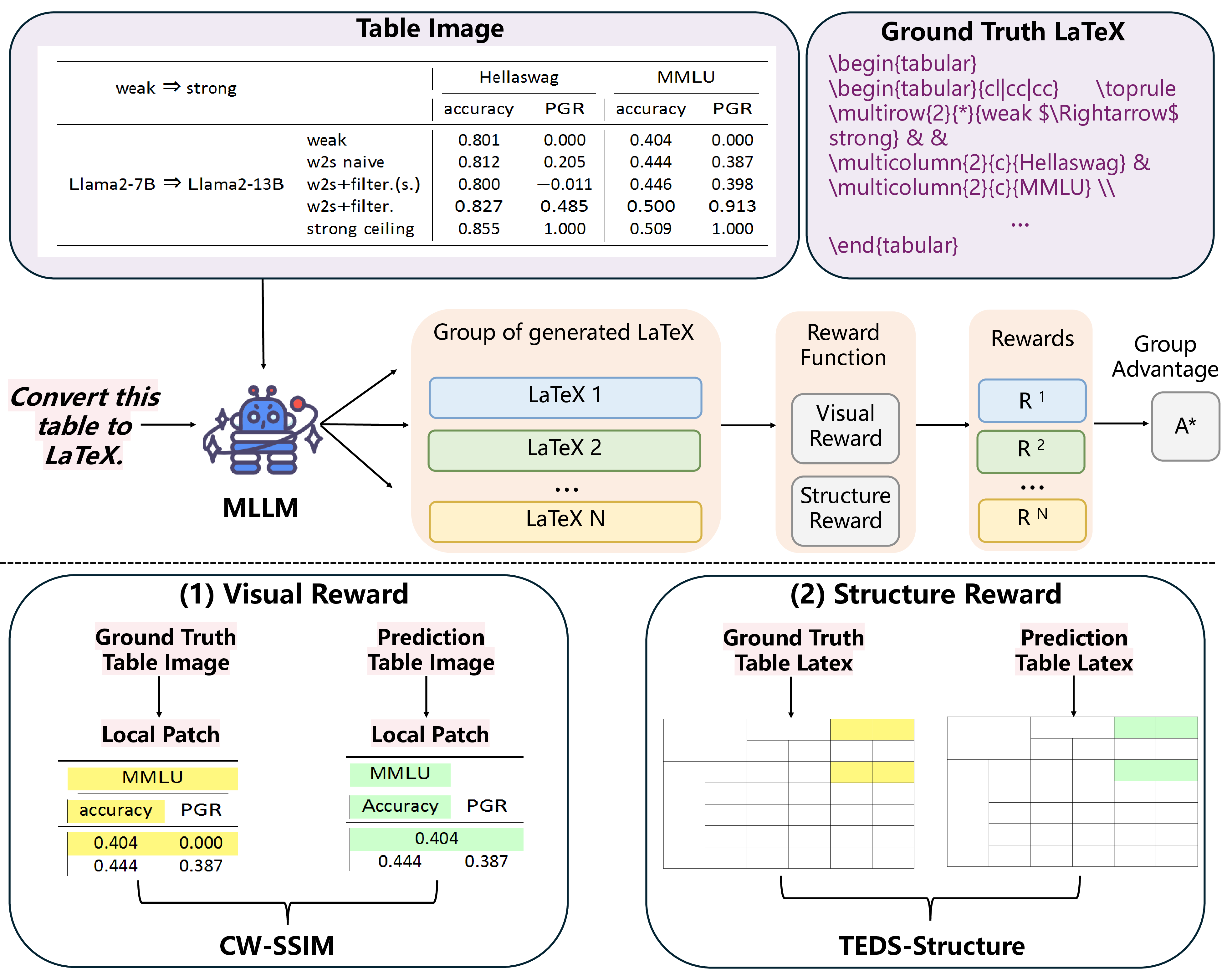
Coaching with rewards (reinforced fine-tuning)
- Next, they used reinforcement learning (RL), which is like a coach giving points based on performance. The model tries something, gets feedback, and improves.
- Their special twist: they gave two kinds of rewards to guide the model:
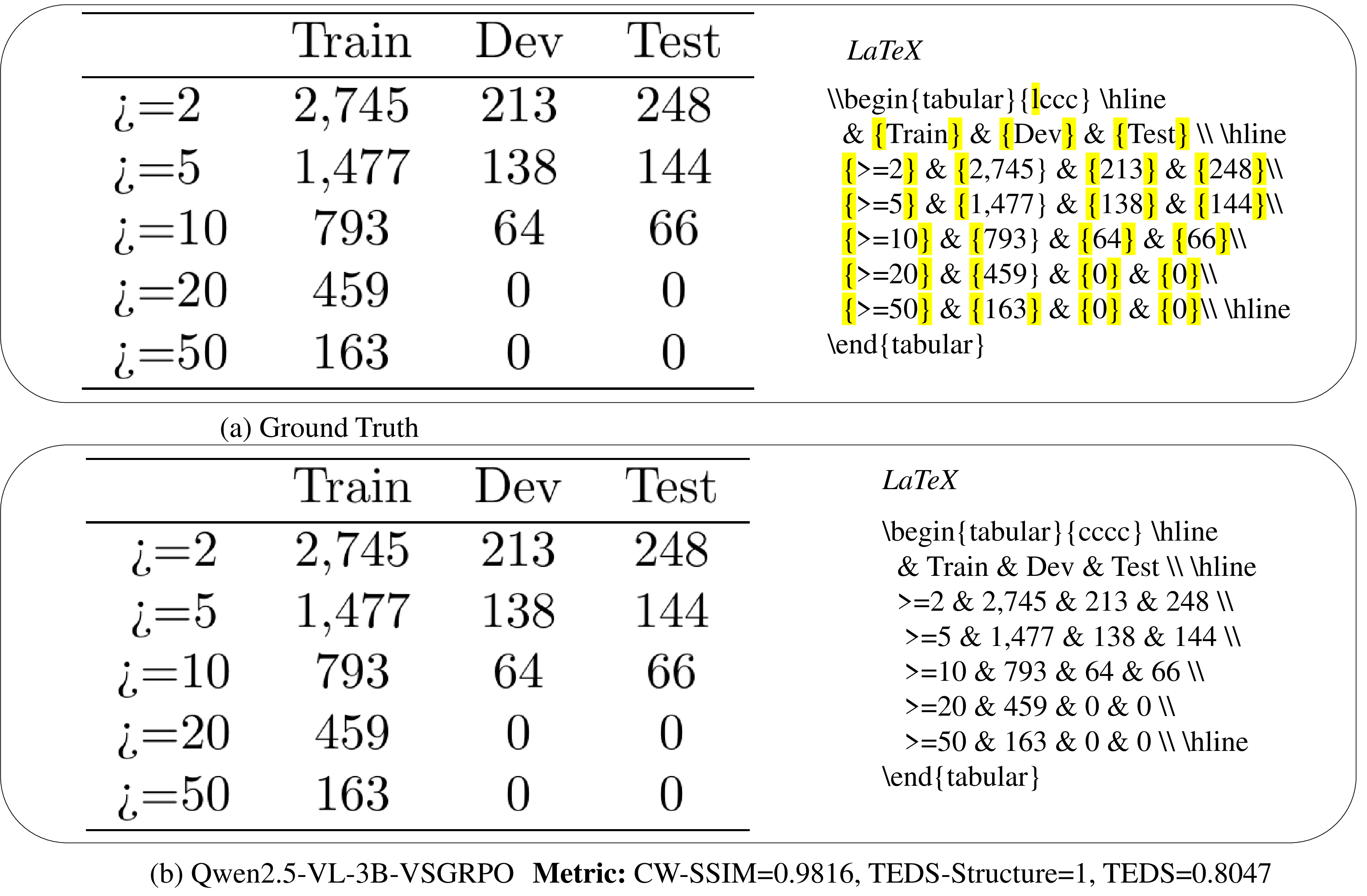
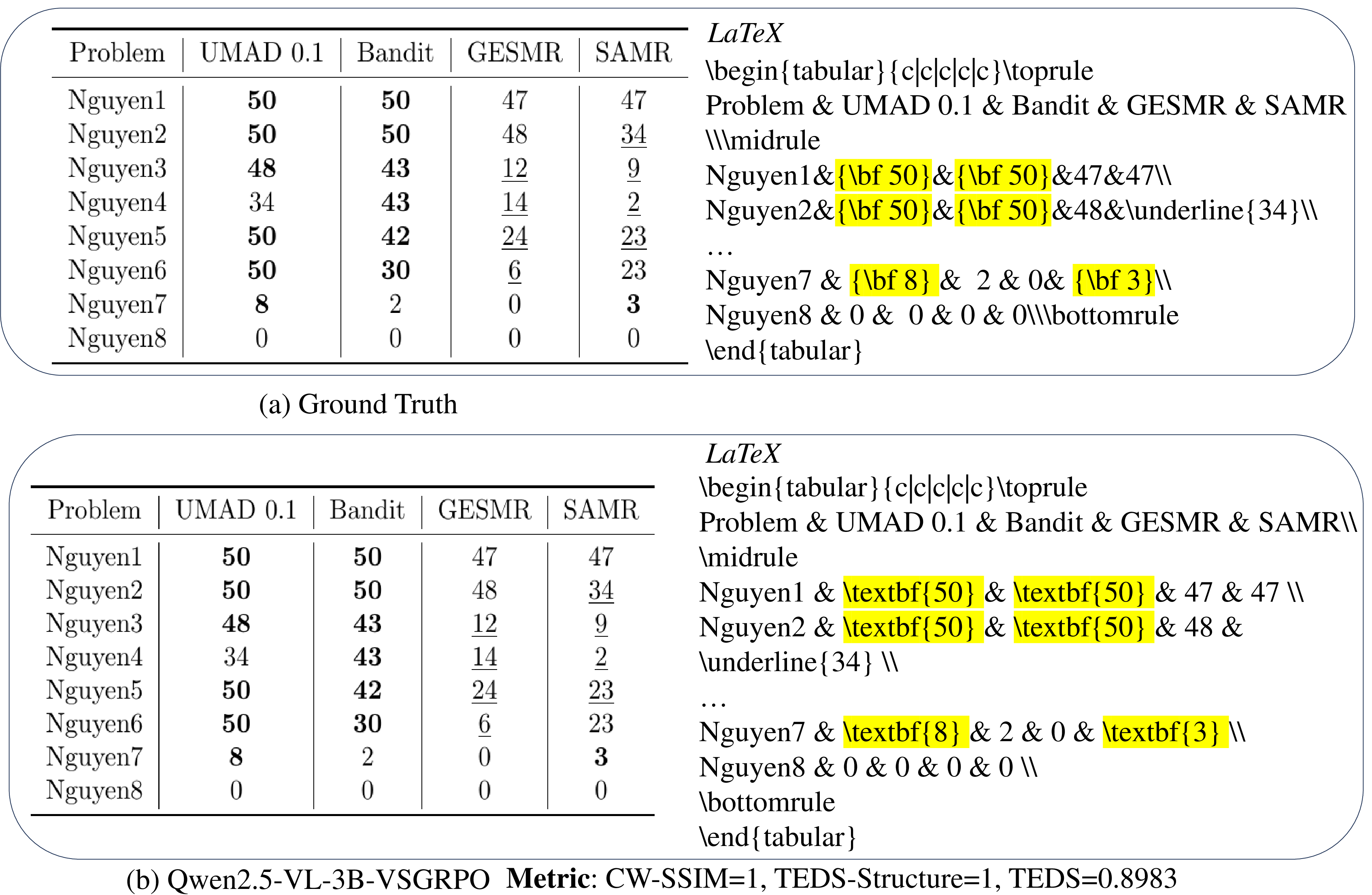
- Structure reward (TEDS-Structure): Does the code organize rows, columns, and cells like the ground truth? Think of this as comparing the “blueprint” of the table.
- Visual reward (CW-SSIM): Render the LaTeX into an image and compare it directly to the original table image. Think of this as a “photo-matching score.”
- This dual-reward setup means the model learns to write code that is structurally correct and looks right when compiled, not just good-looking text.
- They built this on a method called GRPO (Group Relative Policy Optimization), a simpler RL technique that avoids some extra complexity and focuses on correctness-based rewards.
Measuring success (evaluation metrics)
Because judging tables is tricky, they used a hybrid evaluation:
- TEDS-Structure: Checks table structure (rows, columns, merged cells), like verifying the skeleton of the table.
- CW-SSIM: Compares rendered images, scoring how visually similar they are—even for black-and-white, high-contrast tables.
- Compile ratio: The percentage of outputs that actually compile in LaTeX (no syntax errors).
What did they find?
They tested their approach against strong baselines, including commercial tools and big general-purpose AI models. Their method performed best overall, especially on complex tables.
Highlights:
- Very high compile success rates (close to or above 99% on complex tables).
- Top visual similarity scores (CW-SSIM), meaning the rendered tables look very close to the originals.
- Top structural scores (TEDS-Structure), meaning the layout is correct.
- Even a modest-sized model trained with their dual-reward RL beat much larger models that didn’t have this specialized training.
- In human evaluations, people preferred their results more often, especially on challenging tables.
Why this matters: Complex tables are where most systems struggle. This paper shows that combining visual feedback (image comparison) with structural feedback (layout comparison) helps the AI produce high-fidelity LaTeX that’s both accurate and “publication-ready.”
Why does this matter?
- Saves time: Researchers, publishers, and students can quickly convert scanned or image-based tables into editable LaTeX.
- Better quality: The tables generated look professional and are correct in structure, reducing manual fixing.
- Wider access: Makes it easier to reuse data from older PDFs and documents that don’t have original source files.
- Stronger foundations: The idea of “visual-in-the-loop” training (optimizing based on rendered images) can be applied to other tasks, like equations or figures, improving how AI works with scientific documents.
Limitations and future impact
- Training costs: Rendering LaTeX for every trial to compute visual rewards is slow and resource-heavy, becoming a bottleneck.
- Data focus: Their RL stage used about 5,936 complex tables due to compute limits; more data and faster rendering could push performance even further.
- Future directions: Faster rendering, smarter reward designs, and broader datasets could make this approach even more effective. The same idea could be expanded beyond tables to full-page layouts, math, and complex document elements.
In short, this paper shows a practical, high-quality way to turn table images into LaTeX by teaching the model to care about both the code’s structure and how it looks when rendered. That makes it a strong step toward better, more reliable document digitization.
Knowledge Gaps
Below is a single, focused list of concrete knowledge gaps, limitations, and open questions that remain unresolved and could guide future research.
- Real-world input variability: The training and test data are crawled from arXiv LaTeX sources and rendered; robustness to non-synthetic inputs (scans, camera-captured documents, compression artifacts, skew, noise) is not evaluated.
- Table detection and cropping: The system assumes isolated table images; a full pipeline that detects and segments tables from complete pages (PDFs or images) and its impact on end-to-end accuracy is not addressed.
- Dataset coverage of LaTeX environments: The regex-based extraction targets only the tabular environment; coverage gaps for longtable, tabularx, tabular*, array, booktabs, ctable, multi-page tables, sideways/rotated tables, and float/table captions remain unquantified.
- Macro/package dependence: The cleaning step removes “control commands” (e.g., color, possibly booktabs rules). The effect of stripping or missing package-specific macros on both model learning and compilation/runtime fidelity is unknown.
- Complex content types in cells: Handling of math-heavy cells, multi-line paragraphs, footnotes, embedded figures, column types (p/m/b with fixed widths), and alignment/spacing semantics is not separately analyzed or stress-tested.
- Multilingual text and scripts: Support for non-Latin scripts (Chinese, Arabic, Devanagari), ligatures, right-to-left text, special fonts, and encodings in table cells is not evaluated.
- Visual style diversity: Generalization across varied typographic styles (line thickness, rules, spacing, font families/sizes, shading/striping) and colored tables is not explored (CW-SSIM was tuned for monochrome).
- Complexity taxonomy: Complexity is defined by cell count and presence of multirow/multicolumn; it does not capture header hierarchy depth, irregular spanning patterns, nested structures, semantic richness, or layout heterogeneity. A more comprehensive, validated complexity schema is needed.
- LaTeX-to-HTML conversion fidelity: TEDS-Structure requires HTML; the conversion may be lossy or brittle for LaTeX-specific constructs. A LaTeX-native structural metric or validated conversion pipeline is missing.
- Reward design granularity: Both rewards are binary (0/1) with fixed thresholds (CW-SSIM=0.6, TEDS-Structure=0.9). The sensitivity to these thresholds, benefits of continuous/graded rewards, and multi-objective weighting strategies are unstudied.
- RL framework comparisons: GRPO is adopted without controlled comparisons against DPO, PPO variants, RLHF, or rule-based RL used in recent multimodal R1-style training; the stability, sample efficiency, and convergence properties across frameworks remain open.
- Rendering bottlenecks: Reinforcement training requires compiling each candidate to PDF/PNG, causing high latency. Alternatives such as differentiable or approximate renderers, caching/bytecode reuse, incremental compilation, or surrogate visual rewards are not investigated.
- Scalability and scaling laws: The method is shown on 1B and 3B models; systematic studies of model size, dataset size, RL steps, group sampling size (num_gens), and their trade-offs with performance and cost are absent.
- Extremely large tables: RL training excludes tables with LaTeX code length ≥3000 chars; performance and failure modes on ultra-large, multi-page, or highly nested tables are unknown.
- Compile success analytics: “Compile ratio” is reported, but failure reasons (missing packages, syntax errors, overfull boxes, bad alignment) and automated self-correction strategies (syntax checkers, iterative repair loops) are not analyzed.
- Prompt sensitivity and inference strategies: Only a single prompt and temperature=0 are used; robustness to prompt variants, decoding strategies (beam search, nucleus sampling), and post-editing heuristics is not studied.
- Metric–human alignment: Human evaluation uses 200 examples and majority voting; inter-annotator agreement, correlation with CW-SSIM/TEDS-Structure, and diagnostic error categories (e.g., spans vs. content vs. alignment) are not provided.
- Error taxonomy and explainability: No fine-grained breakdown of common failure modes (mis-spans, misplaced rules, cell merges/splits, math errors, content transcription mistakes) or tools to explain/model errors are offered.
- Generalization across domains: The evaluation is arXiv-only; transfer to other scientific publishers, business reports, forms, invoices, financial statements, and historical documents is untested.
- Package/preamble standardization: The “standard macro packages” used for rendering are not fully specified; reproducibility and portability across TeX distributions/platforms require clearer documentation and ablation.
- HTML/visual metric limits: CW-SSIM (even modified) may miss global structural mismatches; advancing visual metrics tailored to high-contrast, sparse tabular imagery (e.g., rule-aware, grid alignment metrics) is an open direction.
- Content correctness vs. visual mimicry: Dual rewards reduce but may not eliminate “visual cheating” (e.g., using rules/spacing to match appearance with incorrect semantics). Explicit semantic constraints or LaTeX AST-level validation could further guard against this.
- End-user utility: Downstream usability (editability, adherence to publisher style guides, semantic tagging for accessibility) and integration with authoring workflows are not measured.
- Data quality and leakage: The crawler/reg-ex pipeline may introduce noisy labels or duplicates; deduplication, data quality audits, and leakage checks between train (2017–2023) and test (2024) sets are not reported.
- Reproducibility details: Precise image rendering settings (DPI, font stack), HTML conversion tools, LaTeX preambles, and data processing scripts need fuller specification to ensure exact replication.
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s released code, dataset, and evaluation procedures, with standard LaTeX infrastructure and lightweight integration work.
- High-fidelity table reconstruction in scientific publishing
- Sector: Publishing, Academia, Software
- Tools/Products: A “Screenshot-to-LaTeX” feature in Overleaf/VS Code; publisher prepress plugins to convert image-only tables to LaTeX; a command-line tool that takes table images and outputs compilable LaTeX
- Workflow: Ingest PDF or image; run Table2LaTeX-RL to generate LaTeX; compile in
texlive-full; human review and patch any custom macros; push to camera-ready - Assumptions/Dependencies: Availability of a secure LaTeX rendering sandbox (no shell-escape); domain match to scientific tables (arXiv-like); handling of custom commands/macros in submissions
- Digitization and archival of legacy technical documents
- Sector: Libraries/Archives, Government, Education
- Tools/Products: Digitization pipelines that combine OCR with Table2LaTeX-RL for tables; batch converters for scanned reports
- Workflow: Scan documents; detect table regions; convert to LaTeX; optionally export to CSV/HTML for indexing; store structured metadata
- Assumptions/Dependencies: Image quality sufficient for recognition; standardized macro packages; rights to process archival material
- Structured data extraction from PDFs for analysis
- Sector: Finance, Healthcare, Policy, Research
- Tools/Products: PDF-to-structured-data services that auto-convert tables to LaTeX→CSV/JSON; audit-ready data extraction modules
- Workflow: Identify table images in filings/reports; generate LaTeX; parse LaTeX
tabularto CSV/JSON; feed into analytics - Assumptions/Dependencies: Robust handling of merged cells/multirow/multicolumn; domain-specific post-processing to normalize units and headers
- Accessibility enhancement for technical documents
- Sector: Accessibility, Education, Government
- Tools/Products: LaTeX-to-accessible-HTML exporters with ARIA roles; screen-reader optimized table output
- Workflow: Convert table images to LaTeX; export to accessible HTML; validate with hybrid metrics (TEDS-Structure + CW-SSIM) before publishing
- Assumptions/Dependencies: Consistent mapping from LaTeX structure to accessible HTML; handling of mathematical notation and nested headers
- Standardized evaluation for table recognition systems
- Sector: Academia, ML/AI Tooling
- Tools/Products: Benchmark suites adopting the hybrid TEDS-Structure + CW-SSIM protocol; continuous integration tests for LaTeX generation quality
- Workflow: Integrate the paper’s metrics into CI; score models on complexity-stratified splits; use compile ratio as a reliability gate
- Assumptions/Dependencies: Agreement on metric thresholds (e.g., CW-SSIM≥0.6, TEDS-Structure≥0.9) and complexity splits; availability of test datasets
- Editorial preflight checks and compliance
- Sector: Publishing, Policy
- Tools/Products: Preflight validators that detect image-only tables, auto-reconstruct them, and flag compilation or structure mismatches
- Workflow: Run submissions through a preflight pipeline; auto-convert image tables; verify compile success and structural fidelity; request author fixes if needed
- Assumptions/Dependencies: Integration with publisher CMS; clear policies around replacing image tables with code
- Research reproducibility support
- Sector: Academia, Open Science
- Tools/Products: Reproducibility bots that reconstruct tables to editable LaTeX and link them to data sources; diff tools to check visual/structural changes
- Workflow: Convert tables; compare generated images to originals via CW-SSIM; attach provenance; allow reviewers to edit and recompile quickly
- Assumptions/Dependencies: Secure LaTeX rendering; provenance tracking; acceptance of hybrid visual-structure checks in review
- AI assistant features in LaTeX editors
- Sector: Software, Education
- Tools/Products: Editor plugins where users paste a table screenshot and receive compilable LaTeX with linting and package suggestions
- Workflow: Capture image; infer LaTeX; highlight potential macro/package needs; compile preview; allow inline corrections
- Assumptions/Dependencies: Local or cloud LaTeX engine; UI integration; macro sanitization
- Content migration across formats
- Sector: Enterprise Documentation, Education
- Tools/Products: PDF-to-LaTeX/HTML/Markdown converters focused on high-fidelity tables; bulk migration utilities
- Workflow: Extract tables from PDFs; reconstruct in LaTeX; export to target formats; validate visually and structurally
- Assumptions/Dependencies: Reliable LaTeX→target format translators; handling of color and complex layouts
- Training and benchmarking resources for model development
- Sector: Academia, ML/AI Industry
- Tools/Products: Use of the 1.2M arXiv table-LaTeX pairs and complexity split to train/improve models; SFT→RL recipes with dual rewards
- Workflow: Fine-tune MLLMs with SFT on full dataset; apply VSGRPO on complex subset; evaluate with hybrid metrics; release models
- Assumptions/Dependencies: Compute resources for rendering during RL; adherence to dataset licensing and ethical use
Long-Term Applications
These applications require further research, scaling, productization, or broader standardization (e.g., handling diverse domains, large-scale deployment, or added safety/robustness).
- Universal document-to-structure conversion beyond tables
- Sector: Enterprise RPA, GovTech, LegalTech
- Tools/Products: Visual-in-the-loop RL pipelines for forms, schedules, diagrams, and spreadsheets; end-to-end DocAI platforms
- Workflow: Extend dual-reward RL to other document elements; target structured outputs (LaTeX/HTML/XML); deploy at scale
- Assumptions/Dependencies: New reward functions per modality; robust domain generalization; scalable rendering or differentiable surrogates
- Real-time mobile capture and conversion
- Sector: Education, Field Operations, Healthcare
- Tools/Products: Smartphone apps that capture tables via camera and output LaTeX/CSV offline with high fidelity
- Workflow: On-device inference; fast rendering or render-free quality proxies; user correction UI
- Assumptions/Dependencies: Efficient models for edge devices; low-latency rendering alternatives; robust performance under poor lighting and perspective
- Semantic enrichment and knowledge-graph linking
- Sector: Research Intelligence, Finance, Pharma
- Tools/Products: Pipelines that convert tables to LaTeX→semantic tables→RDF/graph entries with units and ontologies
- Workflow: Reconstruct structure; extract entities/values; align to domain ontologies; link provenance
- Assumptions/Dependencies: Domain-specific NER and unit normalization; ontology coverage; high-quality header parsing
- Compliance and audit verification of published tables
- Sector: Finance, Healthcare, Regulatory
- Tools/Products: Auditors that verify visual fidelity, structural correctness, and data lineage (table↔source)
- Workflow: Auto-reconstruct tables; compare to source datasets; flag discrepancies; produce audit reports
- Assumptions/Dependencies: Access to source data; standardized audit criteria; robust difference metrics beyond CW-SSIM/TEDS
- Standardization of hybrid metrics for digitization policies
- Sector: Policy, Standards Organizations
- Tools/Products: Official adoption of hybrid structural+visual metrics for high-fidelity document digitization
- Workflow: Establish thresholds and test suites; certify systems; incorporate into government procurement standards
- Assumptions/Dependencies: Community consensus; transparent benchmarks; governance around metrics gaming
- Interactive WYSIWYG AI editors for complex tables
- Sector: Software, Education, Publishing
- Tools/Products: Editors that let users edit a table visually while ensuring the generated LaTeX remains consistent via RL-guided constraints
- Workflow: UI edits → constrained LaTeX generation; live compile previews; automated package selection and macro resolution
- Assumptions/Dependencies: Constraint-aware decoding; scalable RL fine-tuning with human-in-the-loop; safe macro handling
- Cross-format interoperability and round-trip fidelity
- Sector: Enterprise Documentation, Productivity Software
- Tools/Products: Round-trip converters (LaTeX↔Word/Excel↔HTML/Markdown) that preserve merged cells, math, and nested headers
- Workflow: Convert across formats; validate via hybrid metrics; use RL to correct drift
- Assumptions/Dependencies: Mature parsers for all target formats; math and styling preservation strategies; complex layout mapping
- Security-hardened LaTeX rendering services
- Sector: Cloud Platforms, Enterprise IT
- Tools/Products: Sandbox LaTeX renderers with macro whitelisting, resource quotas, and code sanitization integrated into RL pipelines
- Workflow: Submit generated LaTeX; sandbox compile; detect unsafe commands; return artifacts for scoring
- Assumptions/Dependencies: Secure containerization; compatibility with
texlive-full; trade-offs between safety and package coverage
- Domain adaptation for non-scientific tables
- Sector: Retail, Logistics, Manufacturing, Public Sector
- Tools/Products: Fine-tuned models for business documents (invoices, forms, schedules) with domain-specific structure and styling
- Workflow: Curate domain datasets; extend reward design (e.g., color, fonts, borders); continual learning
- Assumptions/Dependencies: Access to representative datasets; privacy/compliance; metric extensions for colored/rich layouts
- Cost-efficient RL training and deployment at scale
- Sector: ML/AI Infrastructure
- Tools/Products: Rendering-free or differentiable proxies for visual rewards; batched GPU/CPU render farms; caching and deduplication
- Workflow: Replace expensive render steps with learned surrogates; optimize pipelines; scale to millions of samples
- Assumptions/Dependencies: Valid surrogate metrics correlating with visual fidelity; robust caching; scheduling across heterogeneous compute
Notes on Feasibility and Dependencies Across Applications
- Rendering overhead: The dual-reward RL pipeline relies on LaTeX rendering (PDF→PNG) for CW-SSIM, which is compute-intensive; large-scale training and real-time applications need optimizations or surrogate rewards.
- Domain shift: The model is trained on arXiv-style scientific tables; performance on business/government formats may require fine-tuning and custom macro handling.
- Safety and sanitization: LaTeX code must be compiled in secure sandboxes to prevent unsafe commands; macro whitelisting and
shell-escaperestrictions are essential. - Metric alignment: Optimizing for CW-SSIM and TEDS-Structure may not capture all semantic errors; thresholds must be set and validated; guard against metric gaming.
- Legal/ethical considerations: Use of scraped LaTeX sources must respect licensing and privacy; consent and compliance are necessary for proprietary documents.
- Infrastructure: Deployment assumes access to
texlive-fullor equivalent environments (Dockerized), reliable compilation, and robustness to compilation failures.
Glossary
- Advantage function: In reinforcement learning, a measure of how much better a sampled action (or output) is relative to the group’s average, often used to scale gradients in policy optimization. "The advantage for the -th sample is computed as"
- BLEU: A token-level n-gram precision metric originally for machine translation, used here to compare generated versus ground-truth LaTeX sequences. "Text-based metrics, such as TEDS~\cite{Zhong2019ImagebasedTR} and BLEU~\cite{Papineni2002BleuAM} , compare the predicted and ground-truth LaTeX code at the token level."
- Compile ratio: The proportion of generated LaTeX outputs that successfully compile, indicating syntactic correctness and practical usability. "Two metrics are used: the compile ratio, which reflects the proportion of LaTeX outputs that can be successfully compiled using standard LaTeX packages, and CW-SSIM, which quantifies the visual similarity between the rendered output and the ground-truth image."
- Cross-modal reasoning: The capability of models to integrate and reason over information from different modalities (e.g., images and text). "which demonstrate strong capabilities in visual recognition, cross-modal reasoning, and LaTeX fluency."
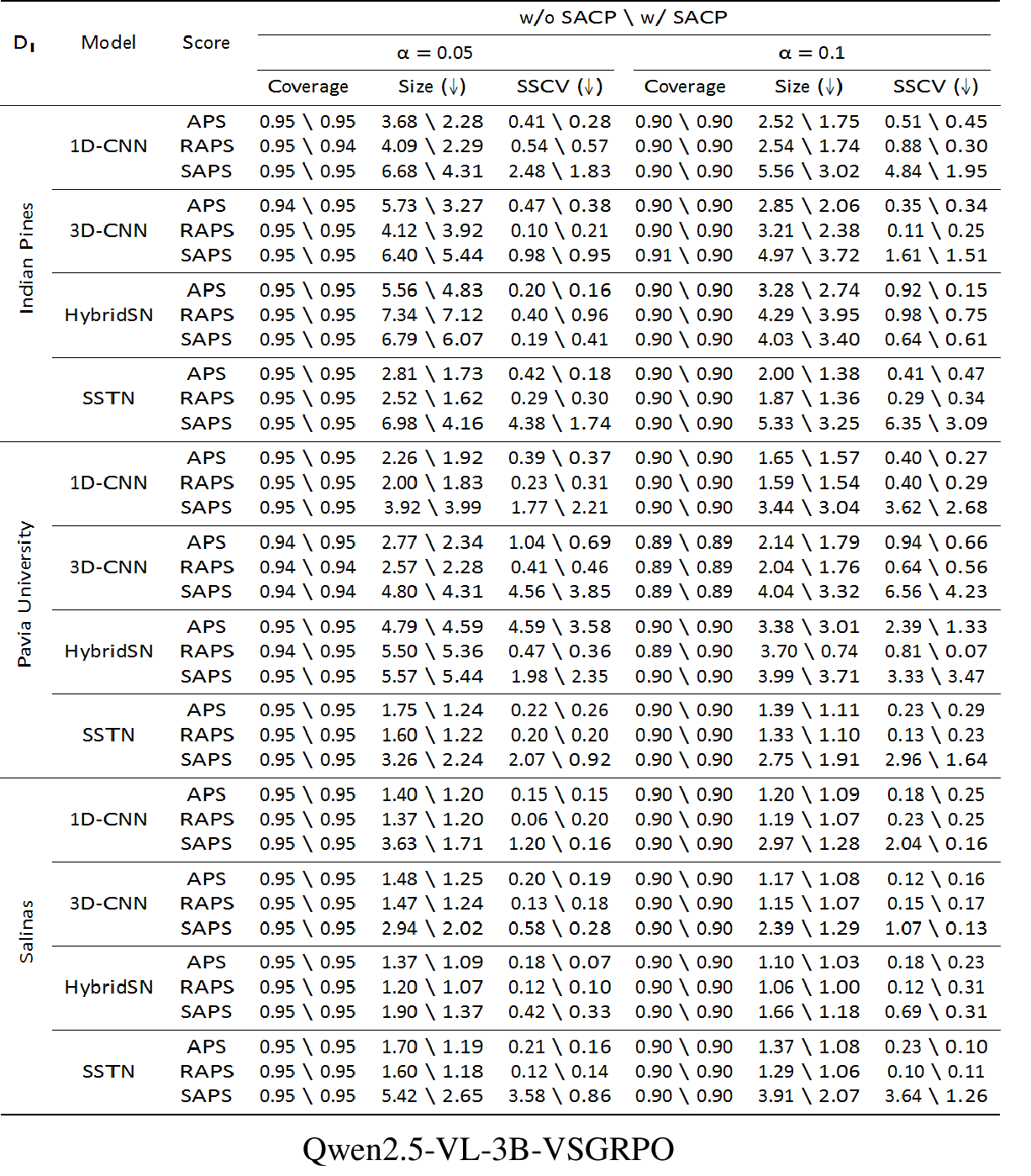
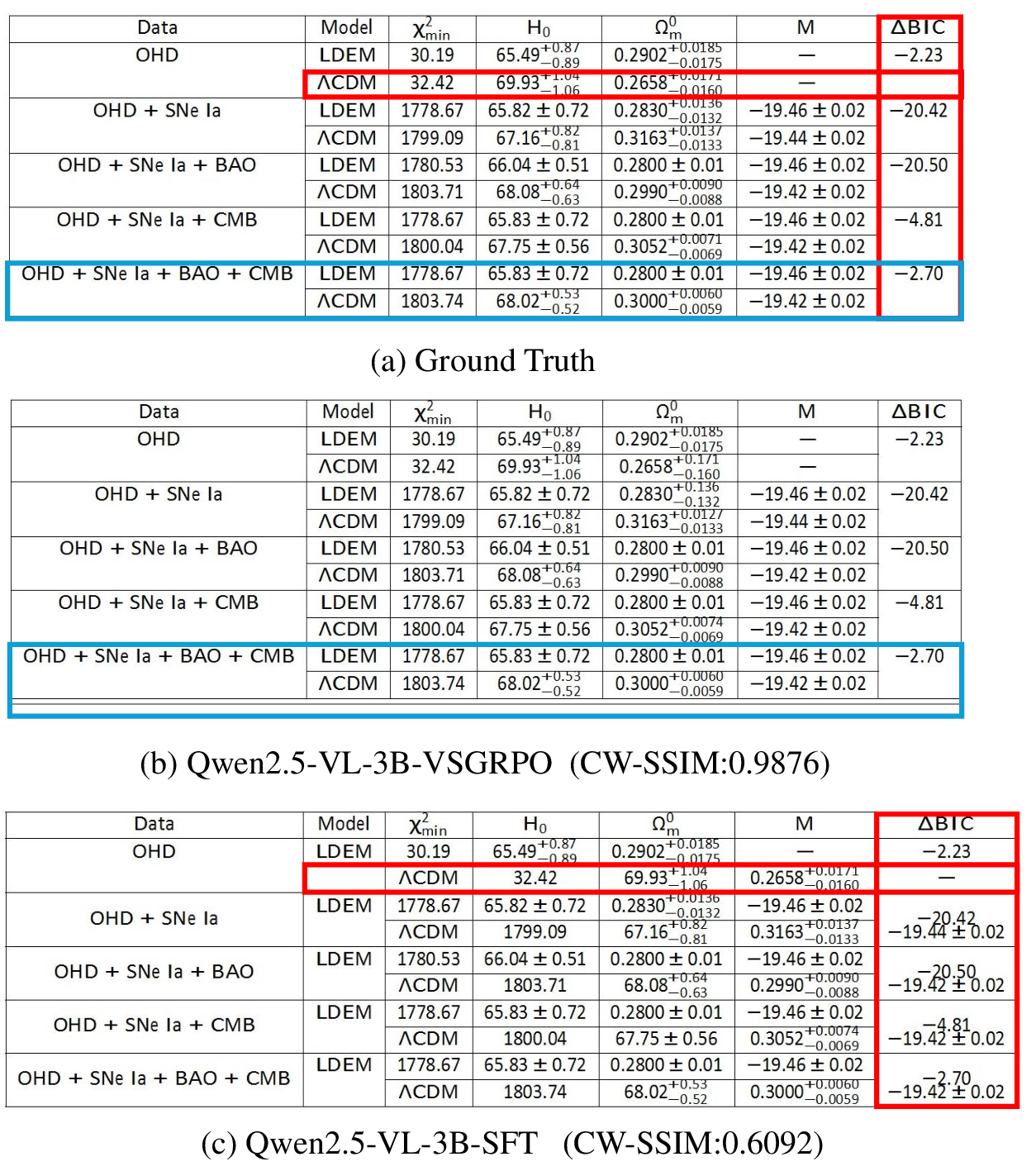
- CW-SSIM: Complex Wavelet Structural Similarity; a perceptual metric that assesses structural similarity between images in the wavelet domain, robust to small geometric distortions. "we render the generated LaTeX code into images and directly evaluate visual fidelity using CW-SSIM."
- DPO (Direct Preference Optimization): A reinforcement learning method that optimizes policies from preference data without a separate value network. "Compared to earlier reinforcement methods such as RLHF\cite{Sun2023AligningLM} and DPO\cite{Yu2023RLHFVTT}, GRPO eliminates the need for a value network"
- Edit (column-wise normalized edit distance): A pixel-level metric measuring differences by normalized edit distance computed column-wise in rendered table images. "Alternative pixel-level metrics, such as Edit (column-wise normalized edit distance) and Match (binary pixel-wise agreement), also fall short in capturing higher-level structural or semantic similarity."
- GNNs (Graph Neural Networks): Neural architectures operating on graph-structured data, used here to infer relationships among detected table cells. "using GNNs to infer row/column associations."
- GRPO (Group Relative Policy Optimization): A PPO-style reinforcement learning algorithm that uses group-relative advantages and removes the need for a value network. "we introduce a dual-reward reinforcement learning strategy based on Group Relative Policy Optimization (GRPO)."
- Haar wavelet transform: A simple wavelet transform using Haar basis functions to decompose images into frequency sub-bands for robust similarity computation. "and applies a simplified Haar wavelet transform~\cite{schmidt1907theorie} to decompose each block into four sub-bands"
- KL divergence (Kullback–Leibler divergence): An information-theoretic measure quantifying how one probability distribution differs from a reference distribution, commonly used as a regularization term in RL. "where and denote the clipping threshold in Proximal Policy Optimization (PPO) and the coefficient controlling the KullbackâLeibler (KL) divergence penalty term"
- Match (binary pixel-wise agreement): A pixel-level metric counting exact matches between binary images at each pixel. "Alternative pixel-level metrics, such as Edit (column-wise normalized edit distance) and Match (binary pixel-wise agreement), also fall short in capturing higher-level structural or semantic similarity."
- Minimum Tree Edit Distance: The minimal number of unit-cost operations required to transform one tree into another, used to quantify structural differences between table representations. "TEDS-Structure computes the Minimum Tree Edit Distance between the two trees"
- MLLM (Multimodal LLM): Large-scale models that jointly process and generate across modalities (e.g., vision and text). "we propose a reinforced multimodal LLM (MLLM) framework"
- PPO (Proximal Policy Optimization): A stable policy-gradient algorithm that constrains policy updates via clipping. "where and denote the clipping threshold in Proximal Policy Optimization (PPO) and the coefficient controlling the KullbackâLeibler (KL) divergence penalty term"
- RFT (Reinforced Fine-Tuning): A fine-tuning stage that uses reinforcement learning signals (rewards) rather than purely supervised losses. "During the RFT training process, we samples a group of generated output set for each table image "
- RLHF (Reinforcement Learning from Human Feedback): An approach that aligns model outputs with human preferences using reinforcement learning. "Compared to earlier reinforcement methods such as RLHF\cite{Sun2023AligningLM} and DPO\cite{Yu2023RLHFVTT}, GRPO eliminates the need for a value network"
- SSIM (Structural Similarity Index): An image quality metric that compares luminance, contrast, and structure between images. "For each sub-band, the algorithm calculates SSIM metrics optimized for monochrome tables"
- SFT (Supervised Fine-Tuning): A training phase where models learn from paired inputs and ground-truth outputs using supervised objectives. "we design a second-stage supervised fine-tuning (SFT) process."
- TEDS (Tree-Edit-Distance-based Similarity): A similarity metric comparing hierarchical structures (and optionally content) by tree edit distance. "TEDS~\cite{Zhong2019ImagebasedTR}, a widely used structure-based metric, lacks sensitivity to fine-grained errors and suffers from mismatches between HTML and LaTeX."
- TEDS-Structure: A variant of TEDS focused on structural fidelity at the cell and layout level, excluding content. "We adopt a hybrid evaluation strategy that combines TEDS-Structure~\cite{Huang2023ImprovingTS} for structural fidelity and CW-SSIM for robust visual similarity."
- Teacher forcing: A training technique where the ground-truth previous token is provided during next-token prediction, which can misalign with downstream objectives. "A key limitation stems from the widespread use of teacher forcing, where the model is trained to predict the next token given the prefix."
- TSR (Table Structure Recognition): Methods that recover a table’s logical and physical structure from images or documents. "Image-to-textâbased table structure recognition (TSR) decomposes the task into predicting structural layout and transcribing cell content"
- Value network: In RL, a learned critic that estimates expected returns; GRPO removes the need for it by using correctness-based rewards. "Compared to earlier reinforcement methods such as RLHF\cite{Sun2023AligningLM} and DPO\cite{Yu2023RLHFVTT}, GRPO eliminates the need for a value network"
- VLM (Vision-LLM): Models that jointly process visual inputs and text for tasks like captioning or code generation from images. "In the general-purpose VLM category, Qwen2.5-VL-72B shows consistently strong structural performance"
- Visual alignment loss: A training objective encouraging alignment between predicted structures and visual observations. "VAST~\cite{huang2023improving} frames coordinate prediction as sequence generation and adds a visual alignment loss."
- Visual-in-the-loop reinforcement design: An RL setup where rendered visual outputs are directly used as part of the reward signal. "This novel visual-in-the-loop reinforcement design significantly enhances the modelâs ability to produce faithful, high-fidelity LaTeX code for structurally rich and visually complex tables."
- VSGRPO: The paper’s dual-reward GRPO variant that jointly optimizes structural accuracy and visual fidelity. "we propose VSGRPO, a novel dual-reward reinforcement learning strategy based on GRPO"
Collections
Sign up for free to add this paper to one or more collections.