- The paper presents the RRVF framework that leverages a closed-loop process of iterative visual reasoning, rendering, and feedback to train models without paired text.
- It employs Group Relative Policy Optimization (GRPO) to stabilize reinforcement learning, achieving superior code execution rates on chart-to-code and web-to-code tasks.
- Experimental results show that RRVF-trained models not only surpass traditional supervised approaches but can even outperform their larger teacher models in visual-to-code translation.
Visual Reinforcement Learning with Reasoning, Rendering, and Visual Feedback: A Framework for Image-Only Multimodal Model Training
Introduction
The paper "Learning Only with Images: Visual Reinforcement Learning with Reasoning, Rendering, and Visual Feedback" (2507.20766) introduces the Reasoning-Rendering-Visual-Feedback (RRVF) framework, a novel approach for training Multimodal LLMs (MLLMs) to perform complex visual reasoning using only raw images, without any paired image-text supervision. The core innovation is the closed-loop RRVF process, which leverages the "Asymmetry of Verification" principle: verifying the correctness of a rendered output against a source image is substantially easier than generating the output itself. This asymmetry is exploited to provide a dense, reliable reward signal for reinforcement learning (RL), enabling the model to learn generative logic directly from visual data.
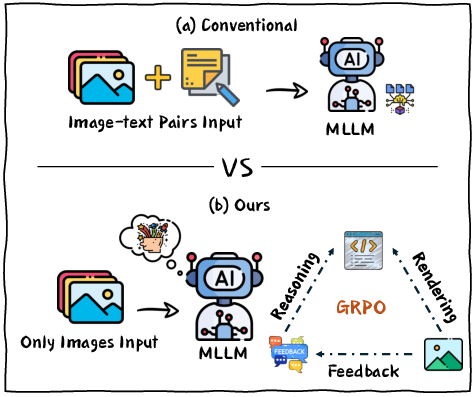
Figure 1: Comparison of training paradigms. Conventional MLLMs require paired image-text data for supervised training. The proposed RRVF framework is trained solely on raw images, utilizing a closed-loop process of reasoning, rendering, and visual feedback that is optimized with the GRPO.
RRVF Framework: Architecture and Process
The RRVF framework is structured as a closed-loop system comprising three main components: iterative visual reasoning, structured visual feedback, and a final visual judge. The process is as follows:
- Iterative Visual Reasoning: The MLLM receives an input image and iteratively generates rendering code (e.g., Python/Matplotlib for charts, HTML for web interfaces) through multi-turn interactions. Each turn may involve tool calls and internal reasoning steps.
- Rendering and Visual Feedback: The generated code is executed by an external tool to produce a rendered image. This image is compared to the original input, and discrepancies are described in structured natural language feedback, which is appended to the model's context for the next reasoning turn.
- Visual Judge and Reward Computation: Upon completion, a visual judge (a more capable MLLM) quantitatively assesses the similarity between the final rendered output and the original image. This similarity score, along with rewards for code validity and tool usage, is aggregated into a final reward signal for RL optimization.
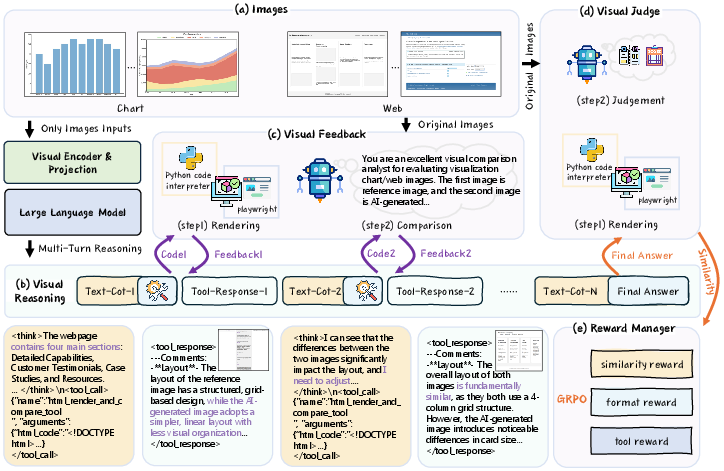
Figure 2: Overview of the RRVF framework, showing the iterative reasoning, rendering, feedback, and reward computation loop for image-only training.
This closed-loop enables the model to self-correct and refine its outputs, learning to generate semantically correct code that reproduces the visual input, all without explicit textual supervision.
Reinforcement Learning Optimization with GRPO
The RRVF framework is optimized using Group Relative Policy Optimization (GRPO), a variant of PPO that eliminates the need for a value function and instead uses group-based advantage estimation. For each input, a group of candidate outputs is sampled from the current policy, and their rewards are normalized within the group. The objective function incorporates a clipped surrogate loss and a KL regularization term to ensure stable policy updates.
The reward function is hybrid, consisting of:
- Visual Similarity Reward: The primary signal, computed by the visual judge, quantifies the fidelity between the rendered and original images.
- Format Correctness Reward: A binary signal for code validity and executability.
- Tool-Use Reward: Encourages effective use of the feedback loop, capped to prevent degenerate long conversations.
The total reward is a weighted sum of these components, with hyperparameters tuned to balance exploration, convergence, and code correctness.
Experimental Results and Analysis
The RRVF framework is evaluated on two structurally distinct image-to-code tasks: chart-to-code (ChartMimic, Plot2Code) and web-to-code (WebSight). The model is trained from a Qwen2.5-VL-Instruct-7B base and compared against both open-source and proprietary MLLMs.
Key empirical findings:
- On ChartMimic, the RRVF-trained model achieves a code execution rate of 97.83%, surpassing all other models, including larger proprietary systems. The overall score (64.36) is the highest among open-source models.
- On Plot2Code, the execution rate remains at 96.21%, with strong performance on text and GPT-4o-based metrics, indicating robust generalization.
- On WebSight, the RRVF model attains a CLIP score of 88.29 and a GPT score of 91.50, outperforming all similar-sized open-source models.
Ablation studies reveal that RRVF-trained models not only outperform supervised fine-tuning (SFT) baselines (which have access to ground-truth code) but also generalize significantly better to unseen domains. Notably, the 7B RRVF model outperforms its own 72B teacher model (used for feedback and judgment) in overall score, demonstrating that the RL-based closed-loop enables the student to surpass the teacher.
Theoretical and Practical Implications
The RRVF framework demonstrates that it is possible to train MLLMs for complex visual reasoning tasks using only raw images, without any paired textual supervision. The "Asymmetry of Verification" principle is operationalized to provide a dense, reliable reward signal, circumventing the need for expensive and brittle image-text datasets. This approach naturally resolves the "semantic equivalence" problem in code generation: any program that produces the correct visual output is rewarded, regardless of its syntactic form.
Practically, this paradigm enables scalable, domain-agnostic training of MLLMs in settings where textual supervision is unavailable or infeasible. The framework is robust to overfitting and demonstrates strong generalization, making it suitable for deployment in real-world applications requiring visual-to-code translation, such as automated chart digitization, web UI generation, and document understanding.
Theoretically, the results suggest that RL with dense, verifiable reward signals can drive models to discover compositional, transferable reasoning strategies, even in the absence of explicit supervision. The finding that a student model can surpass its teacher in this setting is particularly notable, challenging conventional wisdom in knowledge distillation and RLHF.
Limitations and Future Directions
The current instantiation of RRVF is limited to code reconstruction tasks where the verification of outputs is tractable. Extending the framework to more abstract visual reasoning tasks, or domains where verification is non-trivial, remains an open challenge. Additionally, the reliance on a powerful visual judge for reward computation introduces computational overhead and potential bias.
Future research directions include:
- Generalizing RRVF to broader classes of visual reasoning and planning tasks.
- Developing more efficient or self-improving visual judges to reduce reliance on external oracles.
- Exploring curriculum learning and hierarchical RL to further enhance compositional reasoning.
Conclusion
The RRVF framework establishes a new paradigm for training MLLMs using only images, leveraging closed-loop reasoning, rendering, and visual feedback optimized via RL. The approach achieves state-of-the-art results among open-source models, demonstrates strong generalization, and enables student models to surpass their teachers. These findings have significant implications for scalable, supervision-free multimodal learning and open new avenues for research in visual reasoning and RL-based model training.

