- The paper demonstrates that RLKD, via a Generative Structure Reward Model, effectively transfers implicit multi-branch reasoning from teacher to student LLMs.
- It employs a two-stage reward system to distinctly optimize meta-reasoning and solving phases, overcoming the limitations of traditional supervised fine-tuning.
- Experiments on AIME and GPQA tasks show that RLKD significantly enhances reasoning performance using only 0.1% of the training data compared to conventional methods.
Distilling the Implicit Multi-Branch Structure in LLMs' Reasoning via Reinforcement Learning
The paper "Distilling the Implicit Multi-Branch Structure in LLMs' Reasoning via Reinforcement Learning" presents a novel method to enhance the reasoning capabilities of student LLMs by transferring the implicit multi-branch structure of reasoning from teacher LLMs through a reinforcement learning-based knowledge distillation framework named RLKD.
Introduction
LLMs have made significant strides in mastering complex reasoning tasks by generating extended reasoning paths. Supervised fine-tuning (SFT) is a popular approach to distill reasoning capabilities from larger, powerful models to smaller ones. However, research has shown that SFT-based distillation often leads to rote imitation rather than genuine comprehension. This paper revisits the cognitive neuroscience foundations of reasoning to propose a new framework, identifying that authentic reasoning involves an implicit multi-branch structure characterized by meta-reasoning and solving phases. To address the limitations of token-level SFT, the paper introduces RLKD, a reinforcement learning-based knowledge distillation framework coupled with a Generative Structure Reward Model (GSRM). The GSRM evaluates the alignment between student and teacher models' reasoning paths regarding their inherent structure.
Methodology
The core of the RLKD framework is the GSRM, which scores the alignment between teacher and student LLM reasoning paths in terms of multi-branch structures. Authentic reasoning is decomposed into sequences of meta-reasoning and solving steps. The GSRM uses these decompositions to compute a structured reward reflecting the quality of alignment between reasoning paths of student and teacher LLMs.
Generative Structure Reward Model
The paper introduces a two-stage GSRM to reward LLMs based on the degree of alignment between the reasoning structures of student and teacher. The GSRM maps generated paths into sequences of meta-reasoning and solving pairs, scored on alignment through the structured reward mechanism as shown in (Figure 1).
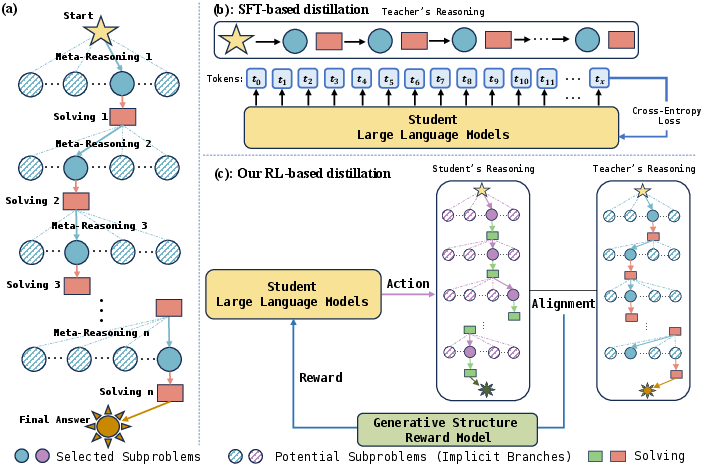
Figure 1: (a) The generated reasoning path has implicit multi-branch structure. (b) Distillation only based on SFT collapses the rich structure into a flat sequence of token prediction to memorize only the teacher's generated path. (c) Our proposed RL-based distillation can teach the student LLM to learn this structure by using a Generative Structure Reward Model to measure the alignment between the reasoning structure of the student and teacher, serving as the reward in RL.
The GSRM is designed through a structured fine-grained training method that treats meta-reasoning and solving task optimizations distinctly, with dynamic adjustments to optimization weights based on task difficulty and includes two main parts: (i) a generative reward model for semantic understanding, and (ii) a rule-based reward model for interpretability and control.
Figure 1: (a) The generated reasoning path has implicit multi-branch structure. (b) Distillation only based on SFT collapses the rich structure into a flat sequence of token prediction to memorize only the teacher's generated path. (c) Proposed RL-based distillation can teach the student LLM to learn this structure by using a Generative Structure Reward Model.

Figure 2: One sequence generation example for math task in in-context learning prompts for GPT-4o.
RL-based Knowledge Distillation
The authors propose RLKD, a novel reinforcement learning-based framework for distilling knowledge from teacher to student LLMs. Central to this approach is the Generative Structure Reward Model (GSRM), designed to provide structured rewards, thereby allowing the student model to capture the implicit multi-branch structure inherent in effective reasoning.
Generative Structure Reward Model (GSRM)
The GSRM distinguishes between meta-reasoning and solving components at each reasoning step by generating a structured sequence of meta-reasoning and solving pairs. The generations from the teacher and student models are then scored for alignment to ensure the student mimics the teacher's implicit multi-branch reasoning structure, rather than superficially reproducing output paths.
Figure 1: (a) The generated reasoning path has implicit multi-branch structure. (b) Distillation only based on SFT collapses the rich structure into a flat sequence of token prediction to memorize only the teacher's generated path. (c) Our proposed RL-based distillation can teach the student LLM to learn this structure by using a Generative Structure Reward Model to measure the alignment between the reasoning structure of the student and teacher, serving as the reward in RL.
Experimental Results
Experiments were conducted using math tasks from datasets such as AIME and MATH-500, alongside graduate-level GPQA tasks, to evaluate the effectiveness of RLKD against existing baselines.
The results on AIME24 and GPQA-Diamond demonstrate that RLKD outperforms the standard SFT-RL pipelines and existing RL baselines (Table 1). Notably, RLKD exhibits superior performance using just 0.1\% of the training data needed for SFT-RL. This underlines the efficacy of RLKD in efficiently utilizing limited data while achieving significant improvements in LLM reasoning capabilities.
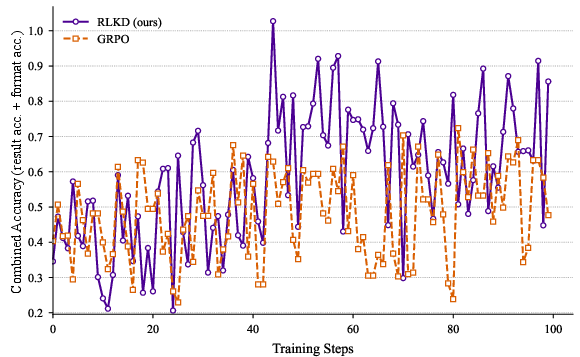
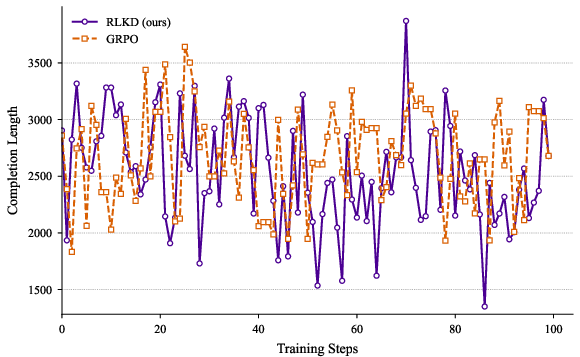
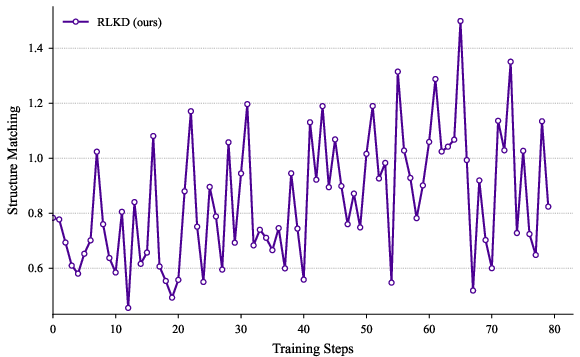
Figure 3: The variations of metrics during the RL training process.
Figure 2: One sequence generation example for math task in in-context learning prompts for GPT-4o.
The ablation studies in (Figure 4) and (Figure 5) underscore the efficacy of Structured Fine-grained Training and the impact of reward weights on the RLKD mechanism.
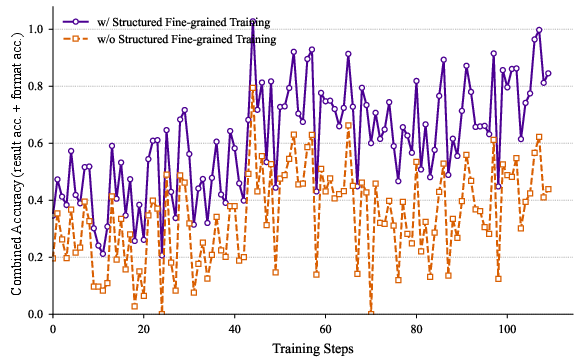
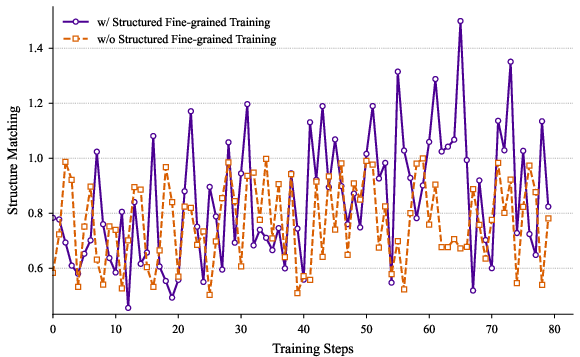
Figure 4: Ablation study about our Structured Fine-grained Training method.
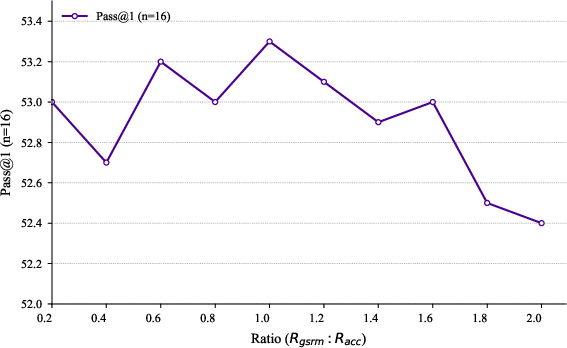
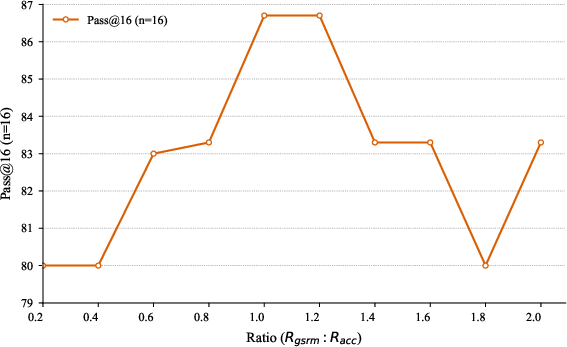
Figure 5: Ablation study about reward weights. Performance of pass@$1$ (n=16) and pass@$16$ (n=16) on AIME24 varying with Rgsrm.
Figure 4: Ablation study about our Structured Fine-grained Training method.
Figure 5: Ablation study about reward weights. Performance of pass@1 (n=16) and pass@16 (n=16) on AIME24 varying with (RaccRgsrm).
The diversity analysis presented in (Figure 6) highlights that RLKD aligns student models' reasoning paths closely with that of teacher models over multiple training steps, showcasing improvement in the student's ability to explore implicit problem-solving avenues.
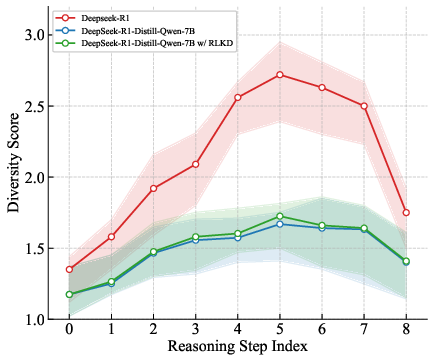
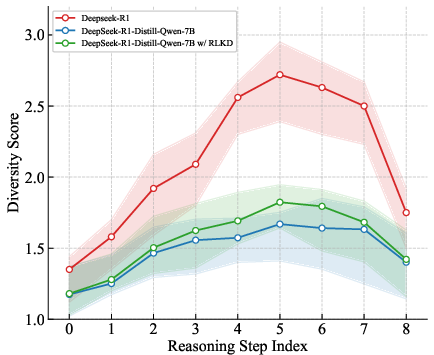
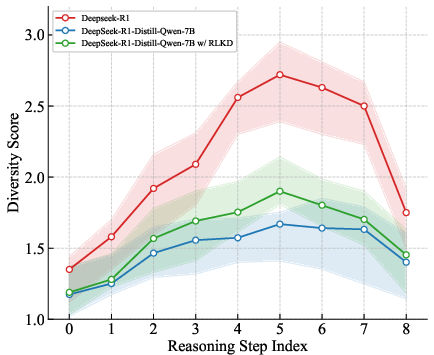
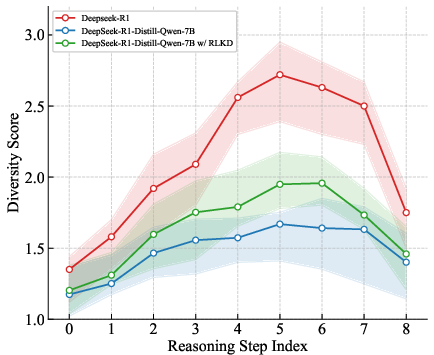
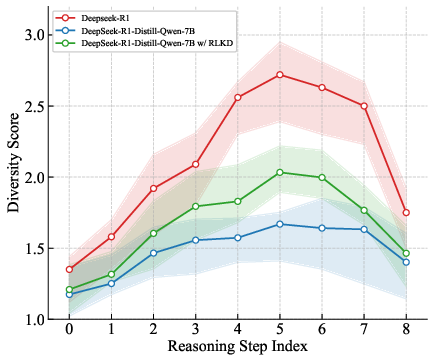
Figure 6: Diversity among different reasoning paths at each meta-reasoning step varying with training.
Comparative Analysis and Implications
Experimental findings reveal that RLKD surpasses Supervised Fine-Tuning (SFT) in transferring the reasoning capabilities of LLMs in domain-shift and out-of-domain settings, as illustrated through detailed comparisons (Figure 7). Notably, RLKD demonstrated substantial capability, outperforming existing reinforcement learning strategies such as PPO and GRPO.
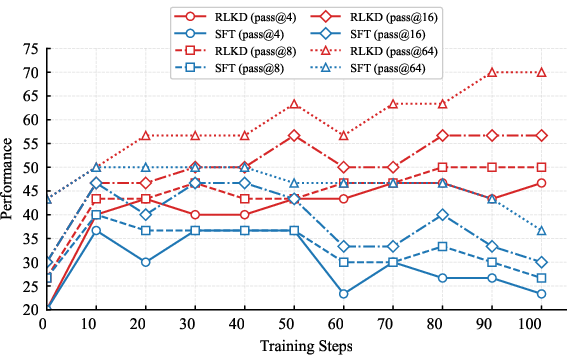
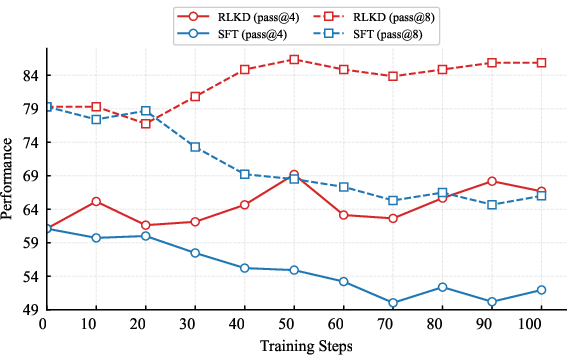
Figure 7: Comparison between SFT-based distillation and our RL-based distillation (RLKD) in domain shift and out-of-domain setting. SFT and RLKD see the same data (32 samples) at each step.
Figure 6: Diversity among different reasoning paths at each meta-reasoning step varying with training.
By leveraging GSRM to provide structured rewards, RLKD encourages LLMs to explore and learn the authentic multi-branch structure in reasoning, thereby enhancing their potential to solve complex tasks across varied domains and datasets.
Conclusion
This research introduces RLKD, the inaugural RL-based framework for LLM reasoning path distillation, addressing SFT's shortfall in teaching students about the intricate multi-branch reasoning structure. The method's exploitation of GSRM establishes a foundation for insightful learning signals. Experimental results corroborate that RLKD enhances LLM's reasoning capacity beyond the capabilities of classical distillation methods. While RLKD presents promising advances, further exploration is necessary to affirm its scalability to larger LLMs. Future research may look to refine structural reward strategies and incorporate human cognitive insights to foster more robust and efficient LLMs.

