- The paper introduces a novel curiosity-driven replay mechanism that prioritizes rarely seen experiences to enhance adaptation in model-based RL.
- It integrates count-based and adversarial replay techniques to efficiently update world models in dynamic, non-stationary environments.
- Experimental results on benchmarks like Crafter demonstrate state-of-the-art performance compared to traditional Dreamer agents.
Curious Replay for Model-Based Adaptation
Curious Replay introduces a novel framework to enhance the adaptability of model-based reinforcement learning (RL) agents in dynamic environments. By utilizing a curiosity-guided prioritized experience replay mechanism, Curious Replay aims to improve the training efficiency of world models, enabling agents to perform better in tasks requiring rapid adaptation to changes. The paper presents a methodology inspired by animal behavior and validates it across various benchmarks, including the Crafter environment, achieving state-of-the-art performance.
Introduction
In dynamic environments, AI agents must swiftly adapt to new stimuli to maintain robust performance. Conventional model-based RL agents, such as Dreamer, often struggle with adaptation due to reliance on uniform sampling from the experience replay buffer, which can result in inadequate model updates when environments change. This paper introduces Curious Replay, a method that prioritizes training on experiences that are least familiar to the model, thereby enhancing the agent's adaptability.
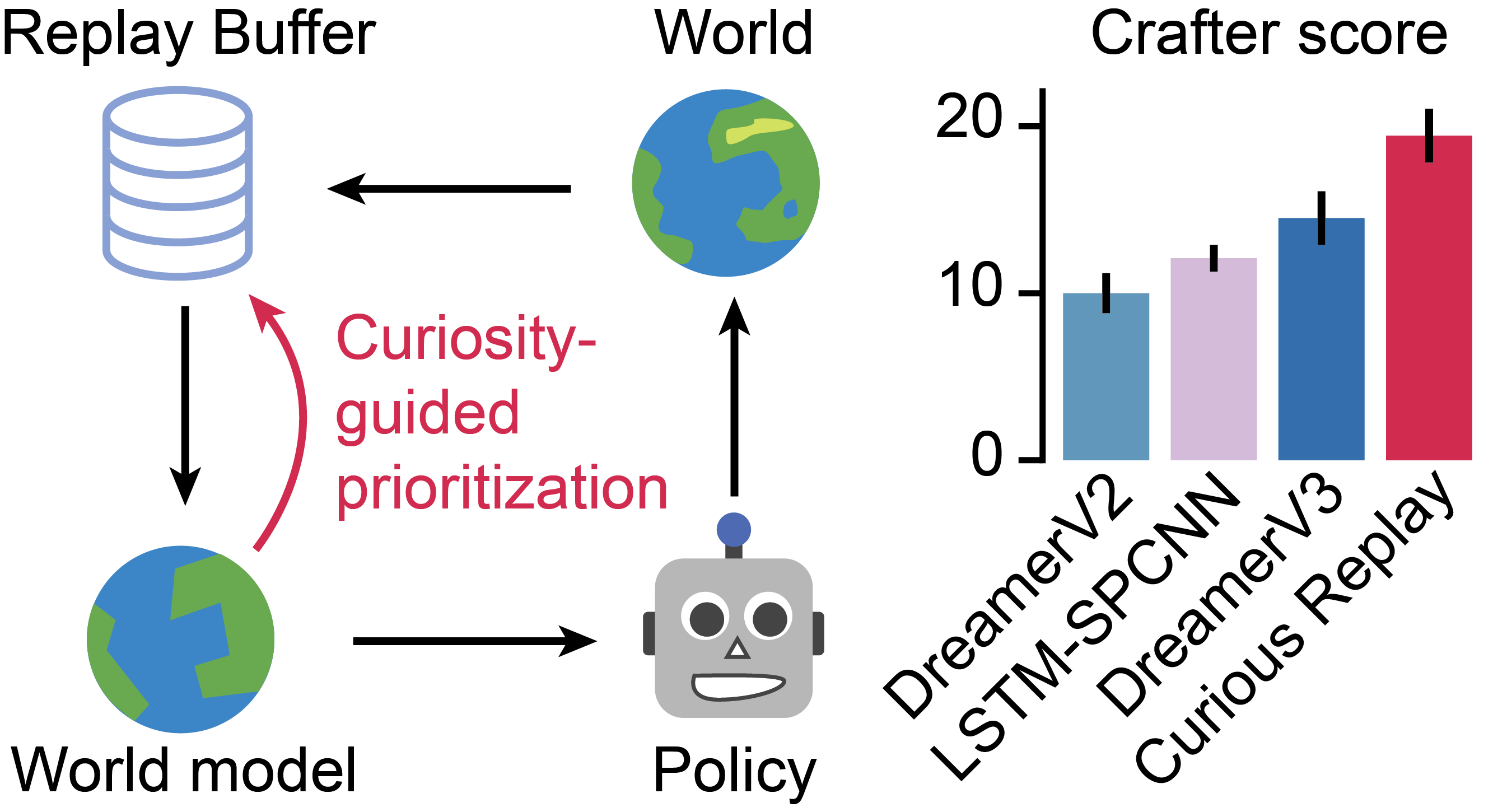
Figure 1: Curious Replay closes the loop between experience replay and world model performance by using curiosity-guided prioritization to promote training on experiences the model is least familiar with.
Methodology
Curious Replay combines principles from prioritized experience replay and curiosity-driven exploration. In contrast to traditional prioritized replay, which often utilizes TD-error-based prioritization, Curious Replay employs a curiosity-based signal to determine replay priorities:
- Count-Based Replay: Prioritizes experiences based on their replay count, biasing towards less frequently replayed experiences, hence encouraging exploration of newer data.
- Adversarial Replay: Utilizes model prediction errors as a prioritization signal, selectively focusing on experiences that the model finds most challenging.
These elements are integrated into the replay buffer to dynamically adjust training priorities in response to observed environmental changes. The prioritization formula is defined as:
pi=cβvi+(∣Li∣+ϵ)α
where pi is the priority of experience i, vi is its replay count, Li is the model loss, and c,β,α,ϵ are hyperparameters controlling prioritization weighting.
Figure 2: Inspired by animal behavior, we investigate adaptation using an object interaction assay...
Experimental Evaluation
Curious Replay was rigorously tested on several benchmarks to assess its efficacy:
Object Interaction Assay
In this test inspired by animal behavior, a model-based agent interacts with a novel object in an environment. Baseline Plan2Explore agents show slow adaptation, while Curious Replay demonstrates a significantly faster interaction time.
Constrained Control Suite
The Constrained Control Suite provides environments with altered dynamics requiring adaptation. Curious Replay augmented agents showed superior performance in adapting to these constraints compared to baseline Dreamer agents.
Figure 3: DreamerV2 w/ Curious Replay outperforms DreamerV2 and DreamerV2 w/ TD in the Constrained Control Suite.
Crafter Benchmark
Crafter, an environment requiring complex, hierarchical achievement unlocks, was used to validate Curious Replay’s sustained adaptability. Curious Replay achieved new state-of-the-art scores, surpassing previous iterations of Dreamer models.
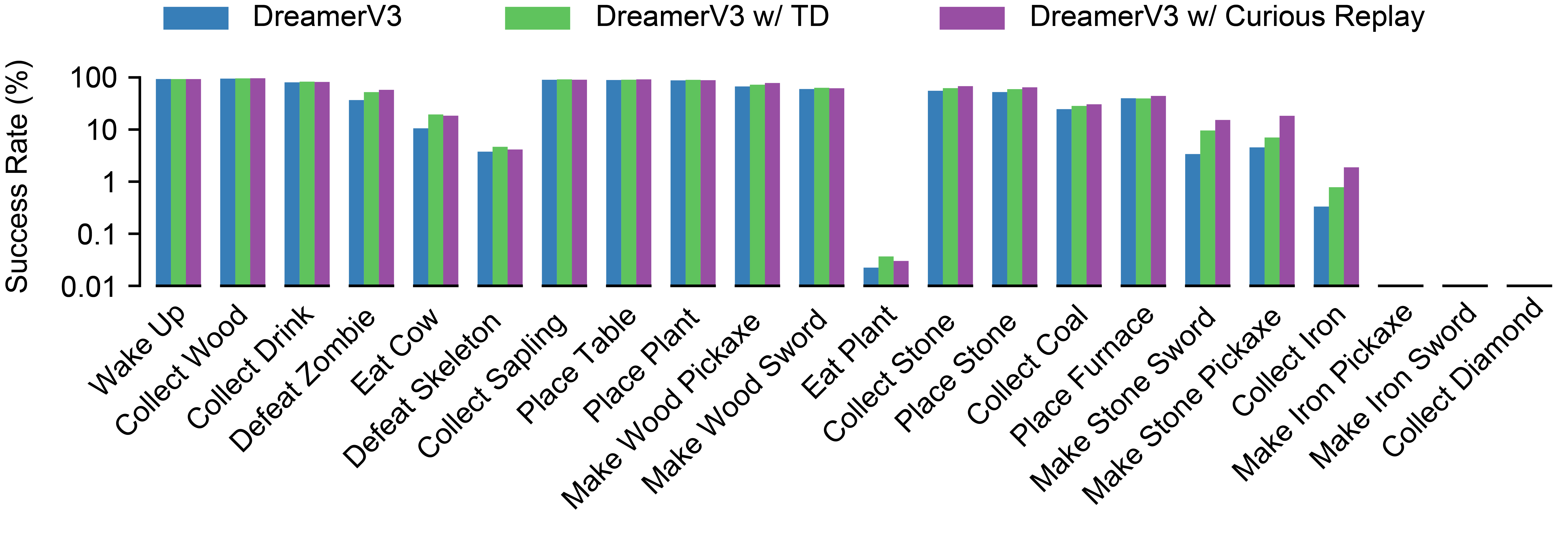
Figure 4: Agent ability spectrum for Crafter, ordered left to right by number of prerequisites for an achievement.
Discussion
Curious Replay's innovative prioritization uniquely positions it for environments with non-stationary dynamics, promoting more effective model updates and policy learning. This adaptability aligns closely with strategic exploration behaviors observed in animals, offering potential insights into biological learning systems.
Implications and Future Work
The Curious Replay framework provides a robust methodology for enhancing adaptive capabilities in RL agents, potentially informing developments in robotics and autonomous systems where environmental changes are frequent. Future work could extend this framework to other model architectures and explore integration with robust learning techniques against distracting stimuli.
Conclusion
Curious Replay elevates model-based RL by incorporating curiosity-driven prioritization into experience replay. Its success in varied, challenging environments points to broader applications and further explorations in adaptation-centric AI research.