STABLE: Gated Continual Learning for Large Language Models
Abstract: LLMs increasingly require mechanisms for continual adaptation without full retraining. However, sequential updates can lead to catastrophic forgetting, where new edits degrade previously acquired knowledge. This work presents STABLE, a gated continual self editing framework that constrains forgetting during sequential updates using parameter efficient fine tuning via Low Rank Adaptation (LoRA; see arXiv:2106.09685). Each candidate edit is evaluated against a stability budget using one of three metrics: (i) Exact Match (EM) drop, capturing factual accuracy loss; (ii) bits increase, reflecting reduced model confidence; and (iii) KL divergence, quantifying distributional drift between the base and adapted models. If a threshold is exceeded, the LoRA update is rescaled through a clipping procedure or rejected. Experiments on the Qwen-2.5-7B model show that gating effectively mitigates forgetting while preserving adaptability. EM based gating achieved the highest cumulative performance in short continual learning sequences. Our results show that different gating strategies can achieve comparable distribution shift (measured by KL divergence) while producing different accuracy outcomes, highlighting the importance of gating design in continual adaptation. This approach offers a principled method for continual model editing, enabling LLMs to integrate new knowledge while maintaining reliability. Code: https://github.com/Bhoy1/STABLE
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-English Summary of “STABLE: Gated Continual Learning for LLMs”
Overview
This paper is about helping big LLMs, like the ones used in chatbots, keep learning new information over time without forgetting what they already know. The authors introduce a method called STABLE that acts like a “gate” to check each update before it’s added, so the model stays accurate and reliable as it changes.
Key Questions the Paper Tries to Answer
- How can a LLM add new facts or rules after it’s been trained, without messing up what it already knows?
- Can we measure whether a change will cause too much “forgetting,” and stop or shrink that change if it’s risky?
- Which kind of “gate” works best to balance learning new things and remembering old things?
How the Method Works (In Simple Terms)
Think of the model as a student who keeps getting small lessons over time. Each “lesson” is a tiny add-on called a LoRA adapter (a small, efficient way to fine-tune a big model without changing all its parts). The problem is: too many new lessons can make the student forget old material. STABLE solves this with a gate that checks each lesson before the student fully accepts it.
Here’s the idea:
- A small update (LoRA adapter) is proposed to add new knowledge.
- Before it’s merged in, a gate measures if the update will cause too much forgetting.
- If the update passes the check, it’s accepted. If it’s borderline, the gate “shrinks” it (scales it down). If it’s too risky, the update is rejected.
The gate can use one of three “yardsticks” to judge updates:
- Exact Match (EM) drop: Does the model get fewer answers exactly right on important questions it already knew? If accuracy drops too much, that’s bad.
- Bits increase: Is the model less confident in its answers (it takes more “information” per token to say the same thing)? More bits means less confidence.
- KL divergence: How much do the model’s word choices shift away from the original model? Bigger KL means bigger behavioral change.
Analogy: The gate is like a careful coach. If a new drill hurts the player’s core skills, the coach either tones down the drill or cancels it.
What They Did (Approach and Experiments)
- They built STABLE on top of SEAL, a system where the model proposes its own edits to improve over time.
- STABLE adds the gate that evaluates each edit.
- They tested the approach on Qwen-2.5-7B (a large open model) using a set of question-answering tasks similar to SQuAD (a well-known dataset).
- They ran sequences of 8 updates, multiple times, and compared the three gate types (EM, bits, KL) using set thresholds for each.
Main Findings (What They Discovered)
- Gating works: It reduces “catastrophic forgetting” (losing previously learned knowledge) while still letting the model adapt.
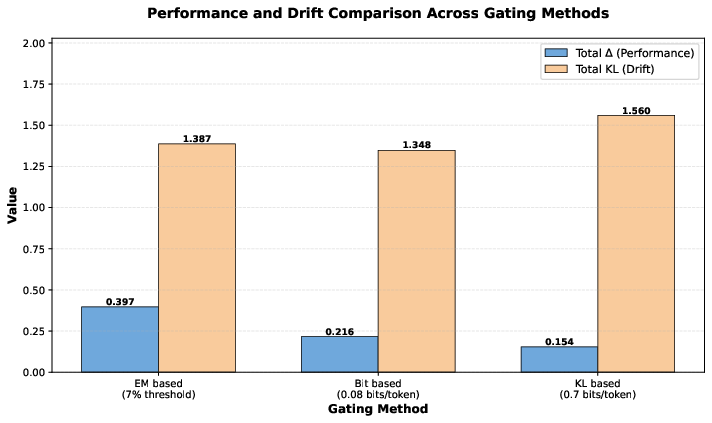
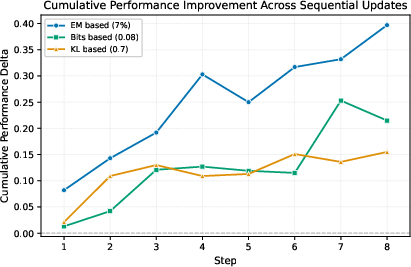
- EM-based gating (watching accuracy directly) gave the best overall performance in their short learning sequences.
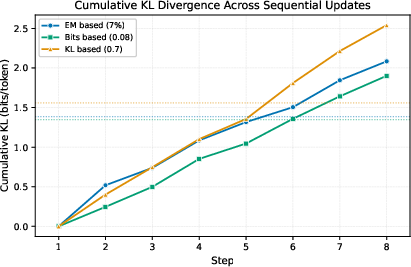
- Different gates can keep the model’s overall behavior change (KL divergence) similar, but still produce different accuracy results. In other words, controlling drift alone isn’t enough—your choice of gate matters for real-world correctness.
- The gate’s “scale down” step (shrinking risky updates) helps keep changes within safe limits, rather than just allowing risky merges.
Why It Matters (Implications and Impact)
- Real-world models need to keep up with new facts (like updated policies, definitions, or news) without being fully retrained every time. STABLE shows a practical way to do that safely.
- By checking each update, STABLE helps build more trustworthy, long-lived AI systems that don’t forget old knowledge as they learn new things.
- Choosing the right gate metric is important: if you care most about factual correctness, accuracy-based gates (EM) may be best; if you need stable behavior, KL might be helpful; if confidence matters, the bits metric can be useful.
Final Takeaway
STABLE is a smart “gatekeeper” for model updates. It helps LLMs learn continuously while protecting what they already know. This makes AI systems more dependable over time, and opens the door to future improvements like adjusting the gate’s strictness based on context or running in real-time settings.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of gaps, uncertainties, and unexplored aspects that remain after this work. Each item is framed to be actionable for future research.
- Budget selection: The forgetting budget ε (e.g., EM 7%, bits 0.08, KL 0.7) is chosen ad hoc. Develop principled, task- and model-specific methods for setting and adapting ε (e.g., via validation curves, PAC-Bayes bounds on KL, or meta-learning), and study dynamic budgets that adjust by context and anchor importance.
- Scaling monotonicity: The gate assumes a monotonic relationship between the forgetting metric f and the LoRA scale α to enable binary search clipping. Analyze and validate f(α) monotonicity; design robust scaling strategies for non-monotonic regimes (e.g., per-layer or per-parameter scaling, convex projections).
- Drift measurement design: KL is computed on adapter on-policy tokens and reported with outlier removal. Assess sensitivity to sampling strategy; compare symmetrized KL, JS divergence, KL on a shared reference corpus, logit smoothing/floors, and robust estimators that obviate post-hoc outlier trimming.
- EM grading reliability: EM depends on an unspecified LLM grader and binary match criteria. Quantify grader bias, calibration, and agreement with human labels; evaluate alternative correctness measures (e.g., F1, partial credit, reference-based grading) and their impact on gating decisions.
- Confidence metric validity: The bits-based gate uses self-log-prob of model-generated outputs, which can decouple from accuracy. Test confidence alternatives (log-prob of gold answers, calibration error, Brier score, expected calibration error) and analyze which best predict forgetting.
- Anchor selection coverage: Anchors are formed by previously edited datapoints, potentially missing retention of general capabilities. Study anchor selection strategies (core competency suites, diverse domain anchors, anchor refresh schedules) and their effect on global knowledge retention.
- Long-horizon behavior: Experiments cover only eight sequential edits. Evaluate stability under long sequences (hundreds/thousands of edits), tracking drift accumulation, acceptance rates, and retention over extended time horizons and non-stationary environments.
- Task and domain generality: Results are limited to SQuAD-style factual QA. Benchmark gated continual editing across diverse tasks (summarization, reasoning, coding, dialog safety, multilingual) and domain shifts to assess cross-task interference and generality.
- Model and PEFT hyperparameter sensitivity: The study uses Qwen-2.5-7B with LoRA rank 32 and fixed training settings. Perform ablations across model sizes, LoRA ranks/scales, learning rates, epochs, and adapter placements to characterize sensitivity and scaling laws.
- Baseline competitiveness: No comparisons with rehearsal, EWC/SI, parameter isolation, or adapter routing. Benchmark gating against and in combination with these continual learning methods to quantify incremental gains and hybrid synergies.
- Merge strategy variants: LoRA updates are merged uniformly into the base. Explore per-layer/per-head scaling, selective merging, maintaining multiple adapters with context routing, and late-binding composition to reduce interference without permanent merges.
- Cross-metric calibration: Thresholds differ by metric, complicating comparisons. Develop calibration procedures to equate budgets across EM, bits, and KL (e.g., matching global KL, acceptance rate, or controlled retention), and map metric changes to expected forgetting.
- Theoretical guarantees: The framework lacks formal bounds relating gated metrics to retained performance on auxiliary tasks. Derive conditions under which bounded KL/EM implies bounded forgetting, and connect to trust-region theory to justify guarantees.
- Training-time regularization: Gating is post-merge only. Compare with training-time regularization (e.g., KL penalties, EM-weighted losses) and evaluate hybrid strategies that combine gated acceptance with trust-region constraints during adapter training.
- Outlier robustness: KL outliers are excluded in reporting; the gate does not explicitly handle heavy-tailed token events. Design gating and estimation procedures robust to rare near-zero probability events (e.g., logits clipping, probability floors, robust loss functions).
- Computational overhead: Gate evaluation adds latency and compute. Quantify cost–accuracy trade-offs, and develop efficient proxies (mini-batch evaluation, cached logits, influence functions, low-cost drift estimators) with fidelity analysis.
- Acceptance policy design: The current accept/scale/reject policy uses a fixed α_min and per-edit decisions. Investigate adaptive policies (e.g., staged integration, edit queueing and scheduling, compound merges, rollback/retry mechanisms) and criteria for recovery from rejection.
- Closed-loop interaction with SEAL: The impact of gating on SEAL’s RL edit generation (exploration, reward shaping, proposal diversity) is not analyzed. Run closed-loop experiments to measure how gating alters proposal distributions, acceptance rates, and cumulative performance.
- Statistical robustness: Results are based on 12 runs with a single seed and limited data. Perform broader significance testing (confidence intervals, bootstrapping), multi-seed evaluations, and cross-dataset replication to establish reliability.
- Safety and alignment: Gating’s ability to block harmful or policy-violating edits is untested. Create adversarial and safety benchmarks; define safety-specific gating metrics and budgets; evaluate resilience to malicious proposals and distributional attacks.
- Evaluation clarity: “Cumulative performance” and per-step metrics are insufficiently specified relative to new-knowledge acquisition versus retention. Standardize protocols to separately measure adaptation on new edits, retention on anchors, and general capability drift.
- Streaming and online settings: Real-time, streaming updates and non-stationary inputs are identified as future directions but not evaluated. Develop online gating algorithms with latency constraints, drift alarms, and robustness under continuous input.
- Generalization to other PEFT and SFT: The approach is demonstrated only with LoRA. Test applicability to other PEFT methods (prefix-tuning, adapters) and to full fine-tuning; determine whether clipping/gating strategies need modification.
- Representation-level drift: Token-level KL may miss internal representational shifts. Incorporate hidden-state similarity metrics (e.g., cosine similarity, CKA) and study their correlation with forgetting and gating effectiveness.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage STABLE’s gated LoRA editing and acceptance-control (EM drop, bits, KL) to reduce catastrophic forgetting during continual updates.
- Software and MLOps (software)
- What to do now: Insert a “Gated LoRA Merge” stage in model CI/CD to accept/scale/reject adapters before merging into production models. Use EM-based gates on domain unit tests; fallback to KL/bits where labels are scarce.
- Tools/workflows: Adapter Registry with versioning; Edit Gate Dashboard (accept/scale/reject logs and thresholds); Anchor Set Builder (task-specific QA packs); Rollback-on-gate-fail; Canary deployment with per-step KL monitoring.
- Assumptions/dependencies: Curated anchor questions/tests per task; compute to run gates; LoRA-compatible model weights; threshold tuning per domain.
- Enterprise Knowledge and Customer Support Bots (software, e-commerce, telecom)
- What to do now: Update product catalogs, FAQs, and policy changes via LoRA; gate merges to avoid forgetting older SKUs, terms, or workflows. Keep per-tenant “anchor packs” to protect contractual nuances.
- Tools/workflows: Knowledge Update Pipeline with gating; Per-tenant Adapter Manager; EM-gated regression tests for top intents and high-traffic answers.
- Assumptions/dependencies: Reliable EM grading (LLM or human-in-the-loop); coverage of high-value questions; schedule updates off-peak due to gating overhead.
- Regulatory/Compliance Change Management (finance, legal, healthcare)
- What to do now: Encode new regulations (e.g., KYC updates, privacy policies, coding standards) as LoRA edits; apply strict EM or KL budgets to ensure pre-existing compliance answers do not degrade.
- Tools/workflows: “Compliance Gatekeeper” pipeline with budgeted trust region; audit-ready gate logs; exception queue for expert review when edits slightly exceed budget.
- Assumptions/dependencies: High-quality compliance anchor sets; auditor-approved thresholds; traceability and rollback procedures.
- Clinical and Operational Assistants (healthcare)
- What to do now: For non-critical advisory tasks (e.g., care navigation, documentation assistance), integrate new guidelines and local protocols with gated merges to preserve validated instructions.
- Tools/workflows: EHR assistant “gate-before-merge” workflow; physician-curated anchors for critical protocol steps; EM-based gating prioritized, with KL supplementary for drift tracking.
- Assumptions/dependencies: Clinician-vetted anchor packs; governance for change approval; stronger safety thresholds than general domains.
- Education and Training Content (education)
- What to do now: Update course materials, program policies, and exam rubrics; gate merges to preserve previously validated facts and grading criteria.
- Tools/workflows: “Curriculum Anchor Pack” per course; EM gate tied to canonical answer keys; scheduled adaptation cycles per semester.
- Assumptions/dependencies: Access to authoritative answer keys; reliable LLM grader or human checks for EM; institutional approval processes.
- Personalized Assistants and On-Device Adapters (consumer software)
- What to do now: Apply user-preference LoRA patches on-device; gate merges so new preferences don’t overwrite long-standing habits or safety boundaries.
- Tools/workflows: On-device Gate with minimum scale α; local anchor sets (e.g., calendar rules, smart-home routines); privacy-preserving logs of gate outcomes.
- Assumptions/dependencies: Sufficient edge compute for gating; small, high-signal anchors; careful battery/latency budgeting.
- Security and Abuse Resistance (software, security)
- What to do now: Use gates as a defensive layer to reject malicious or prompt-injection-induced LoRA updates in collaborative or automated “self-edit” environments.
- Tools/workflows: “Edit Reputation Scorer” combining KL spikes and EM regression tests on safety anchors; quarantine for human triage when gates trip.
- Assumptions/dependencies: Strong safety anchor suites; drift alerting thresholds; secure signing and provenance on LoRA artifacts.
- Academic and Industrial Research on Forgetting (academia)
- What to do now: Use STABLE to benchmark forgetting vs. adaptability tradeoffs across EM/bits/KL metrics and thresholds; study per-step vs. global KL drift.
- Tools/workflows: Reproducible gates for ablation studies; public datasets (SQuAD-style); code at the provided repository.
- Assumptions/dependencies: Access to compute and open models; standardized anchor sets per task for comparability.
- Multi-tenant SaaS Personalization (software)
- What to do now: Maintain per-customer adapters; gate merges before integrating shared updates to protect tenant-specific knowledge from regressions.
- Tools/workflows: “Tenant Adapter Manager” with per-tenant budgets; automatic scale-to-fit merges; differential anchors per customer.
- Assumptions/dependencies: Good multi-tenant isolation; per-tenant anchors; cost control for many gates in parallel.
Long-Term Applications
These opportunities require further R&D, scaling, or standardization (e.g., dynamic budgets, streaming inference, regulatory frameworks).
- Real-time and Streaming Continual Learning (software, telecom)
- Vision: Online gating that adjusts budgets dynamically based on risk, traffic, or drift signals; continuous SEAL-style self-edits with guardrails.
- Tools/workflows: “Budget Scheduler” with risk-based ε; streaming KL/bits telemetry; queueing and backpressure for gate evaluations.
- Dependencies: Low-latency gate computation; robust dynamic-threshold tuning; failure-safe fallbacks during spikes.
- Safety-Critical Decision Support (healthcare, aviation, energy)
- Vision: Near-real-time updates to clinical pathways or operational protocols with hard gates enforcing zero or near-zero forgetting on critical anchors.
- Tools/workflows: Composite gates combining EM, KL, and human approval; safety cases and change-impact reports auto-generated from gate logs.
- Dependencies: Regulatory clearance; gold-standard anchors; continuous validation and post-deployment monitoring.
- Federated Continual Adaptation with Trust Regions (healthcare, finance)
- Vision: Sites train local LoRA edits and propose merges to a shared model; central gate enforces organization-wide drift and accuracy budgets.
- Tools/workflows: “Federated Gate” orchestrator; privacy-preserving anchor evaluation; per-site audit trails.
- Dependencies: Secure aggregation; cross-site anchor standardization; privacy and compliance constraints.
- Multi-objective and Policy-Aware Gating (policy, responsible AI)
- Vision: Gates that jointly control factual accuracy, safety, fairness, and consistency; policy-defined ε per objective with Pareto-aware scaling/rejection.
- Tools/workflows: “Composite Gate” with policy DSL; risk scoring per edit; explainable rejection reasons tied to policy clauses.
- Dependencies: Measurable proxies for safety/fairness; governance for policy updates; alignment with emerging AI standards.
- Robotics and Language-Conditioned Control (robotics)
- Vision: Apply trust-region-like gates to updates in language-to-control policies, ensuring new tasks don’t erase safe behaviors.
- Tools/workflows: KL-based gates for policy updates; simulation-to-real anchors; “Policy Trust Region Manager.”
- Dependencies: Stable interfaces between language and control stacks; high-fidelity anchors; safety validation.
- Automated API and Library Knowledge Evolution for Code Assistants (software)
- Vision: Detect API diffs and auto-generate LoRA “patches” gated by regression tests to keep code assistants current without forgetting older versions.
- Tools/workflows: “API Diff-to-Adapter” pipeline; unit-test anchors; semantic versioning-aware gating.
- Dependencies: Comprehensive test suites; mapping diffs to training exemplars; managing model context across versions.
- Regulatory Frameworks and Standards for Continual Learning (policy, compliance)
- Vision: Industry standards for anchor coverage, gate thresholds, logging, and auditability; model update “change control” mirroring quality systems.
- Tools/workflows: “Continual Learning Audit Standard” checklists; third-party certification; gate-compliance badges.
- Dependencies: Cross-industry consensus; regulator buy-in; third-party tooling.
- Edit Marketplaces and Community Patches (open-source, software)
- Vision: Curated marketplaces for community LoRA edits; platform-side gates verify edits against public anchors before distribution.
- Tools/workflows: Provenance and signature verification; reputation systems based on gate pass rates; sandboxed evaluation.
- Dependencies: Security hardening; IP/licensing; scalable evaluation infrastructure.
- RAG + Gated Editing Orchestration (software, knowledge management)
- Vision: A “Memory Orchestrator” that decides when to store knowledge externally (RAG) vs. integrate via LoRA, with gates ensuring stable internalization.
- Tools/workflows: Cost–risk controller routing between retrieval and gated edit; drift-aware memory compaction.
- Dependencies: Strong retrieval baselines; decision policies for store-vs-edit; longitudinal monitoring.
- Edge and IoT Continual Learning (energy, manufacturing)
- Vision: Field devices receive LoRA updates with device-local gates safeguarding safety-critical routines from drift.
- Tools/workflows: Lightweight on-device gating; “over-the-air” adapter delivery with staged rollout and rollbacks.
- Dependencies: Edge compute constraints; intermittent connectivity; device-specific anchor suites.
Metric-to-Use-Case Guidance (assumptions/trade-offs)
- EM-based gating: Best for fact-heavy tasks where gold answers or reliable LLM graders exist; higher cumulative performance in experiments but requires labeled anchors and grading reliability.
- Bits-based gating: Label-free confidence proxy; useful when EM labels are scarce; sensitive to generation variance.
- KL-based gating: General-purpose drift control; aligns with trust-region intuition; may require domain-specific tuning to translate drift into task performance guarantees.
Across all applications, feasibility hinges on having representative, high-coverage anchor sets; carefully tuned budgets; sufficient compute for gate evaluation; robust logging and rollback; and, in regulated domains, human oversight and auditability.
Glossary
- Adapter merge: combining a LoRA adapter into the base model’s parameters to apply an edit. "Each adapter merge is treated as a candidate update that must pass through a gate"
- Anchor questions: a fixed set of reference questions used to measure forgetting or performance retention. "The EM metric quantifies task level forgetting as the reduction in factual accuracy on anchor questions after adaptation."
- Bits increase: a gating metric measuring how much the model’s confidence (via bits per token) worsens after an edit. "(ii) Bits increase, reflecting reduced model confidence;"
- Bits per token: the average information in bits needed to encode model-generated tokens; lower means higher confidence. "expressed in bits per token."
- Catastrophic forgetting: loss of previously learned knowledge due to sequential updates on new data. "catastrophic forgetting, where new edits degrade previously acquired knowledge."
- Constrained optimization: optimizing updates under explicit constraints to maintain stability or safety. "The gating framework can be interpreted through the lens of constrained optimization."
- Distributional drift: change in the model’s output distribution relative to a reference model after adaptation. "KL divergence, quantifying distributional drift between the base and adapted models."
- Distributional shift: a broader change in data/model behavior distributions across updates or tasks. "successive updates can introduce unconstrained distributional shifts."
- Elastic Weight Consolidation (EWC): a regularization method that penalizes changes to parameters important for past tasks. "regularization based methods such as Elastic Weight Consolidation (EWC)"
- Exact Match (EM): an accuracy metric indicating whether a generated answer exactly matches the gold answer. "Exact Match (EM) drop, capturing factual accuracy loss;"
- Gated continual self editing: a framework that filters or scales self-proposed edits using a gate to prevent forgetting. "We present a gated continual self editing framework that constrains the updates during sequential LoRA merges."
- Gating: the mechanism that accepts, scales, or rejects edits based on a defined budget/metric. "Experiments on the Qwen-2.5-7B model show that gating effectively mitigates forgetting while preserving adaptability."
- KL divergence: a measure of how one probability distribution diverges from another; used here to quantify model drift. "KL divergence, quantifying distributional drift between the base and adapted models."
- KL regularization: adding a penalty proportional to KL divergence to keep updates close to a reference policy/model. "KL regularization, which penalizes divergence between updated and reference policies, is a central mechanism for enforcing such constraints."
- LoRA adapter: a set of low-rank trainable matrices inserted into a model to enable efficient fine-tuning. "when these LoRA adapters are merged sequentially, earlier knowledge may degrade"
- LoRA clip: a procedure that scales LoRA updates to satisfy a forgetting/drift budget before merging. "Safety mode: LoRA clip with minimum scale factor 0.1."
- Low Rank Adaptation (LoRA): a PEFT method that adapts models via low-rank updates instead of full parameter tuning. "parameter efficient fine tuning (PEFT) via Low Rank Adaptation (LoRA)"
- Nats: a unit of information based on natural logarithms; often converted to bits for reporting. "where the division by converts from nats to bits per token."
- Parameter efficient fine tuning (PEFT): techniques that adapt large models by training small added modules while freezing most weights. "Parameter efficient fine tuning (PEFT) methods such as Low Rank Adaptation (LoRA)"
- Parameter isolation: allocating distinct parameters or subnetworks to different tasks to prevent interference. "parameter isolation \cite{rusu2016progressive,fernando2017pathnet}"
- Projection operator: an operator that maps an update back into a feasible set defined by constraints. "The gate functions as a projection operator:"
- Proximal Policy Optimization (PPO): a policy-gradient RL algorithm that constrains updates (often via KL) for stability. "Proximal Policy Optimization (PPO) \cite{schulman2017ppo}"
- Qwen-2.5-7B: a 7B-parameter LLM used as the base model in experiments. "Experiments on the Qwen-2.5-7B model show that gating effectively mitigates forgetting while preserving adaptability."
- Rank decomposed matrices: low-rank factorized matrices inserted into layers to enable efficient adaptation. "inserts trainable rank decomposed matrices into transformer layers"
- Rehearsal based replay: continual learning method that revisits stored past examples to mitigate forgetting. "Classical strategies include rehearsal based replay \cite{rebuffi2017icarl,rolnick2019experience}"
- SEAL: a self-editing framework where models propose and apply edits using reinforcement learning. "The SEAL framework \cite{zweiger2025seal} treats editing as a reinforcement learning problem"
- SQuAD: Stanford Question Answering Dataset; a benchmark for question answering tasks. "main SQuAD style dataset."
- Stability budget: a user-defined threshold limiting acceptable forgetting or drift during updates. "Each candidate edit is evaluated against a stability budget"
- Synaptic Intelligence (SI): a regularization-based continual learning method that tracks parameter importance over time. "Synaptic Intelligence (SI) \cite{zenke2017continual}"
- Trust Region Policy Optimization (TRPO): an RL algorithm that restricts policy updates to a trust region measured by KL. "Trust Region Policy Optimization (TRPO) \cite{schulman2015trpo}"
- Trust region methods: optimization approaches that limit step sizes using a divergence constraint to ensure stability. "Trust region methods operationalize this principle by gating policy updates"
Collections
Sign up for free to add this paper to one or more collections.

