- The paper introduces the DIQ framework that selects high-impact training samples, enabling efficient fine-tuning with only 1% of the data.
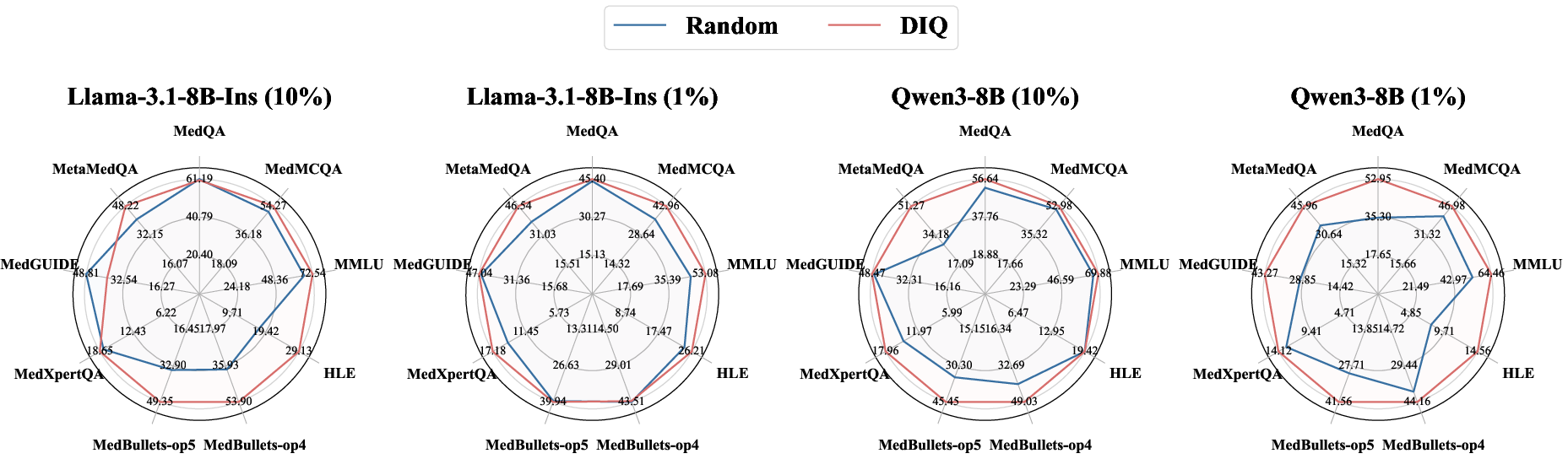
- The paper demonstrates that combining difficulty scoring with gradient influence leads to performance on par with full-dataset training.
- The paper highlights DIQ’s clinical value by improving reasoning metrics and reducing computational overhead in medical applications.
Towards Efficient Medical Reasoning with Minimal Fine-Tuning Data
The paper "Towards Efficient Medical Reasoning with Minimal Fine-Tuning Data" investigates techniques to improve the efficiency of adapting LLMs for medical reasoning tasks. It introduces a novel data selection framework called Difficulty-Influence Quadrant (DIQ) to identify minimal, high-impact subsets of training data, which enhance learning without requiring extensive computational resources.
Supervised Fine-Tuning Challenges
Supervised Fine-Tuning (SFT) is critical for adapting LLMs to specialized domains. However, traditional SFT relies heavily on large, unfiltered datasets, which often contain redundant or low-quality samples. This results in unnecessary computational load and suboptimal model performance. Previous data selection strategies have primarily focused on sample difficulty, but these approaches miss the optimization utility of each sample as indicated by its gradient influence.
Difficulty-Influence Quadrant (DIQ) Framework
The DIQ framework selects training samples by jointly considering two critical dimensions:
- Difficulty: Reflects the complexity of reasoning required for each sample, determined using a BiomedBERT-based classifier fine-tuned to score medical questions on a 5-point Likert scale.
- Influence: Measures the optimization impact of each sample, approximated through gradient dot products between training and validation samples over epochs.
This combination allows DIQ to prioritize samples in the "high-difficulty–high-influence" quadrant. This balance ensures efficient learning by emphasizing samples that support complex clinical reasoning while also providing substantial parameter shifts.
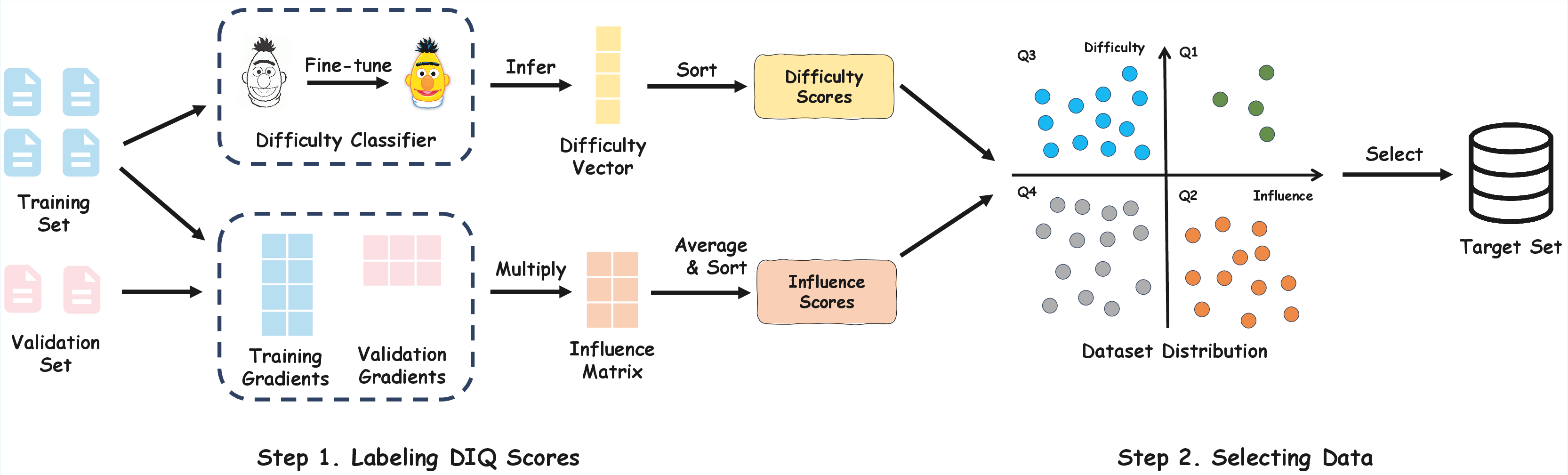
Figure 1: Overview of the DIQ framework. The method operates by first mapping each sample into a two-dimensional space defined by difficulty and influence, creating four distinct data quadrants for strategic selection.
Dataset and Model Details
The study utilizes several datasets, such as Huatuo and FineMed, comprising up to 32k medical reasoning samples. Models like Llama3.1-8B-Instruct and Qwen3-8B serve as the primary LLMs for experimentation, fine-tuned via LoRA with specific hyperparameters to adapt them efficiently to medical tasks.
Results
DIQ-enabled strategies show that fine-tuning on just 1% of selected data achieves equivalent performance to traditional full-dataset training, and using 10% consistently surpasses the baseline:
Efficiency Analysis
A core advantage of DIQ is computational efficiency. The framework's overhead in computing difficulty and influence scores is minimal compared to full model fine-tuning procedures. This upfront cost is mitigated by the potential to reuse computed scores across multiple experiments, emphasizing DIQ's suitability for frequent model fine-tuning cycles.
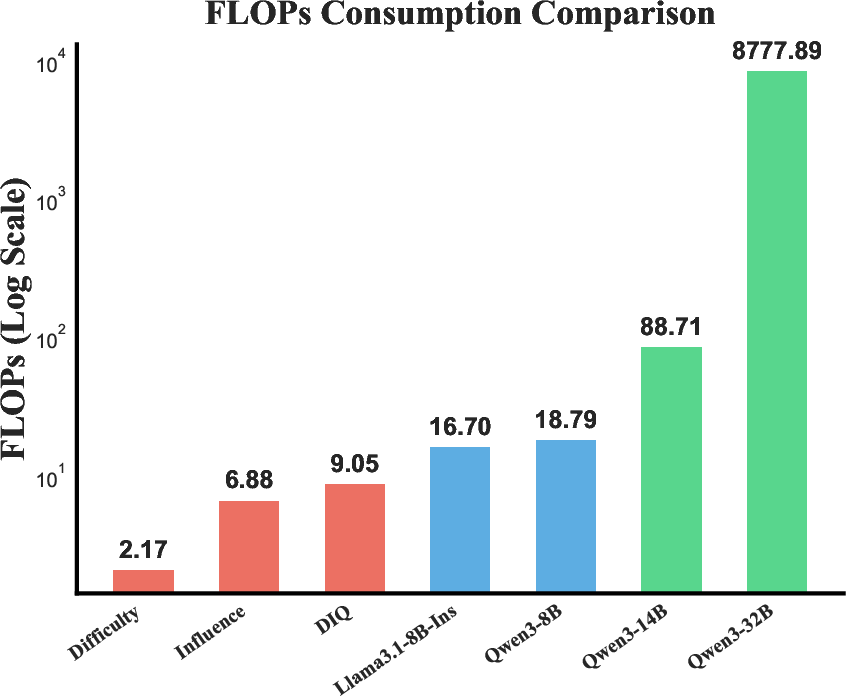
Figure 3: The FLOPs consumption (1014) comparison of computing DIQ scores, fine-tuning Llama3.1 and Qwen3 series models. The y-axis is log scale for better presentation.
Clinical Value Assessment
Expert evaluations highlight improvements in clinical reasoning quality, with DIQ-selected subsets enhancing standard clinical reasoning metrics such as Differential Diagnosis, Safety Checks, and Evidence Citation. Models trained on DIQ data produce reasoning processes that are more closely aligned with expert judgments, indicative of their higher clinical value.
Conclusion
The Difficulty-Influence Quadrant framework stands out as a methodologically sound approach to optimizing medical LLM fine-tuning with minimal data. By strategically selecting high-impact training samples, DIQ reduces resource needs without sacrificing model performance and offers a robust, scalable solution for specialized domain adaptation in LLMs. Future work may explore extensions to larger model architectures and additional domains to further validate and expand the utility of DIQ.