This paper, "LLMs Can Easily Learn to Reason from Demonstrations Structure, not content, is what matters!" (Li et al., 11 Feb 2025 ), investigates how LLMs can acquire complex reasoning abilities, specifically generating "Long Chain-of-Thoughts" (Long CoTs) which involve reflection, backtracking, and self-validation. The core findings are that this capability can be instilled efficiently with a small amount of data and parameter-efficient fine-tuning (like LoRA), and crucially, that the logical structure of the reasoning process in the training data is far more important than the correctness or specific content of individual steps.
Methodology and Implementation:
The authors demonstrate this by distilling reasoning capabilities from powerful teacher models (DeepSeek-R1 and QwQ-32B-Preview) into a student model (Qwen2.5-32B-Instruct) using supervised fine-tuning (SFT) and Low-Rank Adaptation (LoRA).
- Data Curation: They curated a dataset of approximately 17,000 examples (12k math, 5k coding) by selecting difficult problems from various benchmarks (Numina-Math subsets like AMC/AIME, Math, Olympiad, and coding datasets like APPS, TACO). Prompts were classified by difficulty (using GPT-4o-mini). Critically, the selected teacher-generated responses included Long CoTs that reached the correct final answer. For structural analysis experiments, a subset of 4618 correct math responses from QwQ was used.
- Training Details: Fine-tuning was performed using the Llama-Factory framework. The base model was Qwen2.5-32B-Instruct.
- SFT and LoRA were applied using standard next token prediction loss.
- Hyperparameters included a batch size of 96, learning rates of 1e-5 (SFT) and 1e-4 (LoRA), a warm-up ratio of 0.1, and linear learning rate decay.
- Long CoT Format: The fine-tuning data structured the responses using specific tags, as shown in the system prompt provided in Appendix C. The thinking process was enclosed in
<| begin_of_thought | >and<| end_of_thought | >, with steps separated by\n\n. The final solution was presented separately in<| begin_of_solution | >and<| end_of_solution | >. This explicit structure is likely key to the model learning the Long CoT pattern. - Evaluation: Models were evaluated on five reasoning benchmarks: Math-500, OlympiadBench, AIME 2024, AMC 2023, and LiveCodeBench. Performance on non-reasoning tasks (MMLU, ARC-C, IEval, MGSM) was also assessed to check for catastrophic forgetting.
Key Insights for Implementation:
- Efficiency: The paper shows that competitive reasoning performance can be achieved with remarkably little data (17k samples) and computational resources. LoRA fine-tuning, updating fewer than 5% of parameters, achieved performance similar to or better than full SFT. This implies that deploying and updating reasoning capabilities can be significantly cheaper in terms of data collection, compute, and memory (LoRA adapters are much smaller than full models).
- Structure is Paramount: This is the most significant finding. The model learns the pattern of Long CoT (reflection, backtracking, self-validation) by imitating the structural flow of the demonstrations, rather than the specific numerical correctness or presence of reasoning keywords.
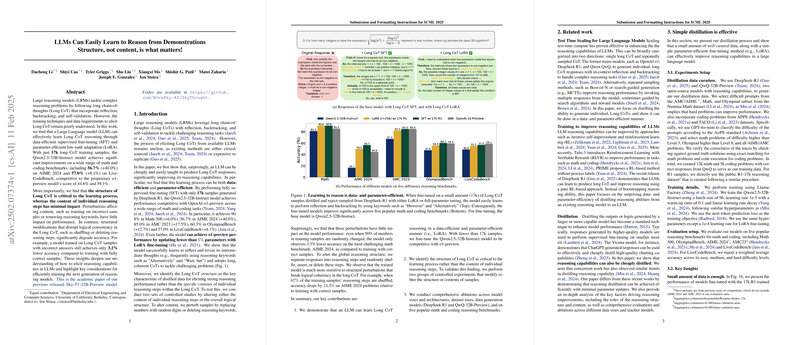
- Content Perturbations: Experiments showed that altering local content, such as using samples with wrong final answers (only 3.2% accuracy drop) or corrupting a large percentage of digits (up to 70% with only 4.3% accuracy drop), had minimal impact on performance. Removing reasoning keywords also had little effect.
- Structural Perturbations: Conversely, disrupting the logical flow by deleting, inserting random, or shuffling reasoning steps severely degraded accuracy. For example, shuffling 67% of steps caused a 13.3% accuracy drop on AIME 2024. This indicates that the coherence and dependency between steps are what the model learns, not just generating verbose outputs or using specific phrases.
- Implication: When curating data for training reasoning models, focus on demonstrations that exhibit a clear, albeit potentially flawed, logical progression, reflection points, and error handling, rather than solely on perfectly correct intermediate steps.
- Retaining Base Capabilities: Unlike some powerful teacher models (like QwQ), the fine-tuned student model (Qwen2.5-32B-Instruct) retained strong performance on general language understanding and instruction-following tasks, avoiding catastrophic forgetting. This is crucial for building models that are both good reasoners and general-purpose assistants.
- Generalizability: The Long CoT fine-tuning method showed improvements across a range of student models of different sizes and architectures, although the degree of improvement varied. This suggests the approach is broadly applicable.
- Efficiency over Best-of-N: The fine-tuned Long CoT model achieved performance comparable to Best-of-N sampling (a technique that involves generating multiple responses and selecting the best one) with N between 2 and 16. This indicates that learning to produce a single high-quality Long CoT is significantly more inference-efficient than repeatedly sampling shorter, less structured responses.
Practical Applications:
- Training Specialized Reasoning Models: Developers can take general-purpose LLMs and efficiently fine-tune them on domain-specific reasoning tasks (e.g., physics, chemistry, law) using a relatively small dataset of structured Long CoT examples.
- Improving Code Generation: Distilling Long CoTs from powerful coding models can enhance the ability of smaller models to break down complex problems and produce more accurate code, potentially involving simulated debugging steps within the thought process.
- Developing Interactive Reasoning Assistants: Models trained with Long CoT can generate more transparent and interpretable step-by-step reasoning processes, making them suitable for applications where users need to understand how a solution was reached, not just the final answer. The structured output format (
begin_of_thought,end_of_thought, etc.) facilitates parsing and presentation of the reasoning trace. - Data Augmentation Strategies: The finding that corrupted content has minimal impact suggests potential data augmentation techniques where correctness of intermediate steps might be relaxed, as long as the overall reasoning structure is maintained, potentially reducing the cost of data verification.
Implementation Considerations:
- Structured Data: The success hinges on training data formatted to clearly delineate thought steps, reflection, and the final solution. Implementing the
begin_of_thought/end_of_thoughtandbegin_of_solution/end_of_solutionstructure during data preparation is crucial. - Teacher Model Selection: While the structure is key, the quality of the teacher model still matters for generating some logically consistent structure to begin with.
- Computational Requirements: While LoRA reduces VRAM compared to full SFT, training 32B parameter models still requires substantial GPU resources. Inference with Long CoT will also generate longer responses compared to direct answers or short CoT, increasing latency and token generation costs.
- Code Availability: The authors have open-sourced their code base at https://github.com/NovaSky-AI/SkyThought, which provides a practical starting point for implementing the fine-tuning process.
In summary, this research provides a practical blueprint for efficiently improving LLMs' reasoning capabilities by focusing on distilling the structure of long, reflective thinking processes through data- and parameter-efficient fine-tuning. This opens up avenues for creating more capable and efficient reasoning models for various real-world applications.