- The paper introduces Group Relative Policy Optimization (GRPO) for tuning RLVR, demonstrating that model-based filtering outperforms random sampling in the medical domain.
- It compares four data sampling strategies with the MedQA-USMLE dataset, highlighting significant improvements on benchmarks like MMLU and CMMLU.
- The study reveals that while filtered data enhances domain-specific outcomes, it may reduce robustness across diverse applications.
Open-Medical-R1: Data Selection for RLVR in the Medical Domain
Introduction
The paper "Open-Medical-R1: How to Choose Data for RLVR Training at Medicine Domain" (2504.13950) investigates the optimal data selection strategies for Reinforcement Learning with Verified Rewards (RLVR) within the medical domain. RLVR is recognized for enhancing reasoning capabilities in LLMs, particularly in fields like mathematics and logical puzzles. However, its potential has not been extensively explored in the medical domain. This study examines four data sampling strategies from the MedQA-USMLE dataset: random sampling, and filtering based on the models Phi-4, Gemma-3-27b-it, and Gemma-3-12b-it. Using Gemma-3-12b-it as the base model and implementing Group Relative Policy Optimization (GRPO), the paper evaluates performance across benchmarks including MMLU, GSM8K, MMLU-Pro, and CMMLU.
Methodology
Group Relative Policy Optimization (GRPO)
GRPO is an innovative algorithm in reinforcement learning that leverages relative performance metrics within action groups to optimize policy parameters. It differs from traditional policy gradient methods, like PPO, by eliminating the need for a separate value function. GRPO computes advantages by comparing individual action rewards to the group's mean reward, updating policies to favor actions exceeding the average performance.
Data Sampling Strategies
The focus of the study is on the effectiveness of different data sampling strategies. The strategies involve filtering samples based on model predictions to identify "easy" and "hard" samples, thereby constructing a challenging training set. The prompt templates used for filtering and training are shown in Figures 1 and 2, respectively.

Figure 1: The prompt used to make a response for a sample.

Figure 2: Template of the prompt during the training.
Experiments and Results
Implementation Details
Training was conducted using the Unsloth framework on an NVIDIA GeForce RTX 4090 GPU. The training incorporated a mix of format, accuracy, and XML count rewards, with a learning rate of 2×10−5. A cosine annealing scheduler was employed, and batch size and rollout settings were adjusted to maximize efficiency.
The evaluation across benchmarks demonstrated that models trained on filtered data generally outperformed those trained on randomly selected samples. The detailed results indicate that self-filtered data (using Gemma-3-12b-it) led to superior performance in medical domains (Figure 3), albeit with reduced robustness across varied benchmarks.
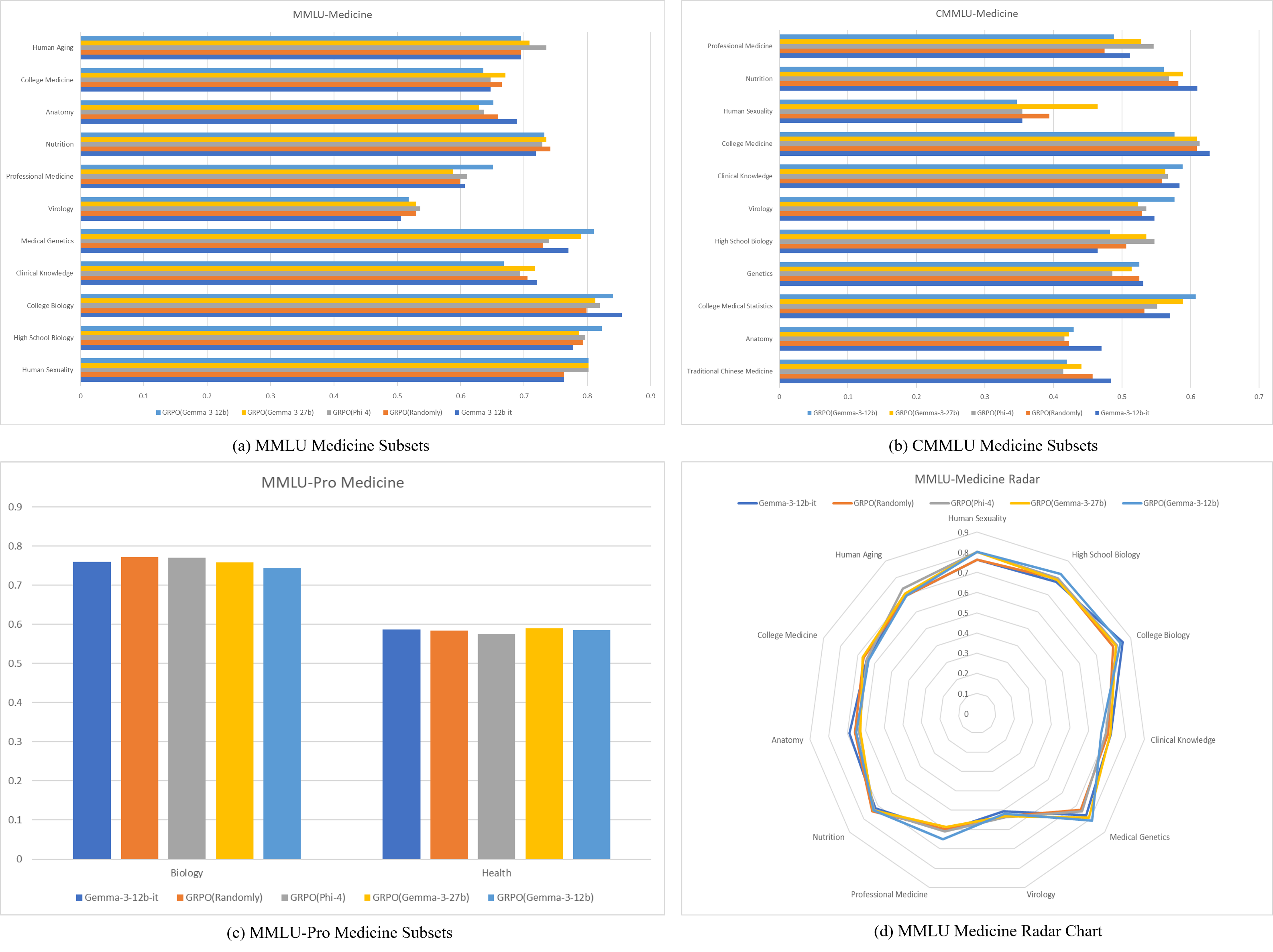
Figure 3: Results on medicine domain. (a) Results of medicine domain-related subsets from MMLU. (b) Results of medicine domain-related subsets from CMMLU. (c) Results of medicine domain-related subsets from MMLU-Pro. (d) Radar chart of the results.
Models trained on larger models within the same series showed greater overall robustness, suggesting that strategic data filtering can enhance learning outcomes beyond random sampling approaches.
Medical Domain Results
Significant improvements were observed in medical-related fields when utilizing model-based filtering, particularly in areas like high school biology and medical genetics. While GRPO enhanced performance, it highlighted the importance of a sophisticated sampling strategy to maintain robustness across disciplines.
Conclusion
This study underscores the critical role of data selection in leveraging RLVR for domain-specific applications like medicine. While self-filtered samples offer substantial benefits in targeted domains, they may sacrifice robustness in broader applications. Future directions include refining sampling strategies and exploring the integration of search tools to enhance model reasoning and performance capabilities. The insights from this research provide valuable guidance for future RLVR applications in specialized fields.

