- The paper establishes the LIMO Hypothesis, positing that minimal, high-quality demonstrations can elicit advanced reasoning in pre-trained LLMs.
- It details a systematic dataset curation, fine-tuning, and evaluation framework, revealing superior performance on both in-domain and out-of-distribution benchmarks.
- Experimental results emphasize that targeted example selection outperforms larger datasets, improving efficiency in complex mathematical reasoning tasks.
LIMO: Data-Efficient Reasoning in LLMs
The paper "LIMO: Less is More for Reasoning" (2502.03387) challenges the conventional wisdom that complex reasoning in LLMs requires massive training datasets, positing that sophisticated reasoning can emerge from minimal but strategically designed demonstrations. The central argument is encapsulated in the Less-Is-More Reasoning (LIMO) Hypothesis, which emphasizes the significance of pre-trained knowledge and high-quality cognitive templates in eliciting reasoning abilities.
Key Concepts and the LIMO Hypothesis
The LIMO Hypothesis suggests that in foundation models with comprehensively encoded domain knowledge, sophisticated reasoning can be elicited through minimal but precisely orchestrated demonstrations of cognitive processes. This hypothesis rests on two key factors:
- The latent presence of prerequisite knowledge within the model's parameters, facilitated by advancements in pre-training techniques and the inclusion of extensive mathematical content.
- The quality of reasoning chains that precisely decompose complex problems into detailed, logical steps, making the cognitive process explicit and traceable, achieved via strategic curation of SFT examples.
LIMO Dataset Construction
To validate the LIMO Hypothesis, the authors construct a high-quality, minimal dataset through a systematic approach. The dataset curation process prioritizes both question and solution quality. The question selection process involves a multi-stage filtration pipeline, starting from a large pool of candidate problems from various established datasets, such as NuminaMath-CoT and DeepScaleR. The reasoning chain construction involves employing multiple state-of-the-art reasoning models and implementing a rule-based scoring system to quantify key characteristics that distinguish high-quality reasoning chains, such as elaborated reasoning, self-verification, exploratory approach, and adaptive granularity.

Figure 1: This figure illustrates the pipeline used to construct the LIMO dataset, emphasizing the multi-stage filtration and selection processes.
Training and Evaluation Framework
Based on the LIMO principle, the authors fine-tune Qwen2.5-32B-Instruct using supervised fine-tuning on the LIMO dataset. The training process employs full-parameter fine-tuning with DeepSpeed ZeRO-3 optimization and FlashAttention-2. A comprehensive evaluation framework is established to assess the models' mathematical reasoning capabilities across various dimensions, encompassing both in-domain and out-of-distribution evaluations. The primary evaluation suite includes several well-established mathematical competitions and benchmarks, such as AIME24 and MATH500. To rigorously evaluate OOD performance, the authors select benchmarks differing from the training data across three categories: diverse mathematical competitions, novel multilingual benchmarks, and multi-disciplinary benchmarks.
Experimental Results and Analysis
The experimental results demonstrate LIMO's superior performance across both in-domain and out-of-domain tasks. On in-domain tasks, LIMO achieves the best results across all benchmarks, outperforming QwQ-32B-Preview and OpenAI-o1-preview by significant margins. LIMO also demonstrates strong generalization capabilities across diverse out-of-domain tasks, maintaining competitive performance even on GPQA. The experiments reveal that despite larger scale, baseline datasets underperform compared to LIMO, highlighting that targeted selection is more crucial than data quantity for developing robust reasoning capabilities.
To further validate the effectiveness of the LIMO method, the authors conduct several analyses. The impact of reasoning chain quality is investigated through a controlled comparative study of solutions with varying quality for identical problems. The impact of question quality is examined by testing how question difficulty affects models' reasoning capabilities. The effect of pre-training data is tested by comparing two 32B-parameter models, Qwen1.5-32B-Chat and Qwen2.5-32B-Instruct, with identical architecture but different pre-training data quality. The scaling of mathematical reasoning ability with model size is explored by fine-tuning models from the Qwen2.5-Instruct series of varying sizes. Finally, the impact of dataset size on fine-tuning efficacy is examined by systematically varying the number of training samples.
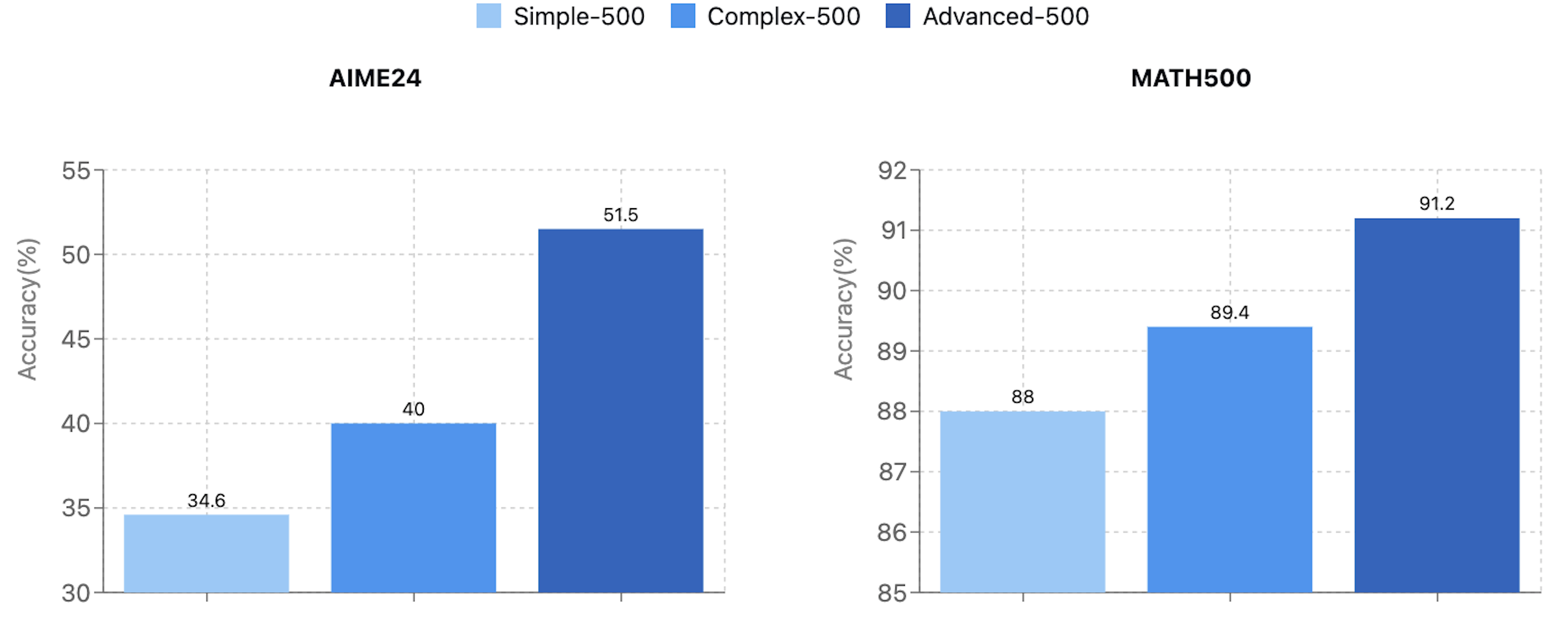
Figure 2: This plot compares performance on MATH and AIME benchmarks between models trained on different question quality levels, showcasing the impact of question difficulty on model performance.
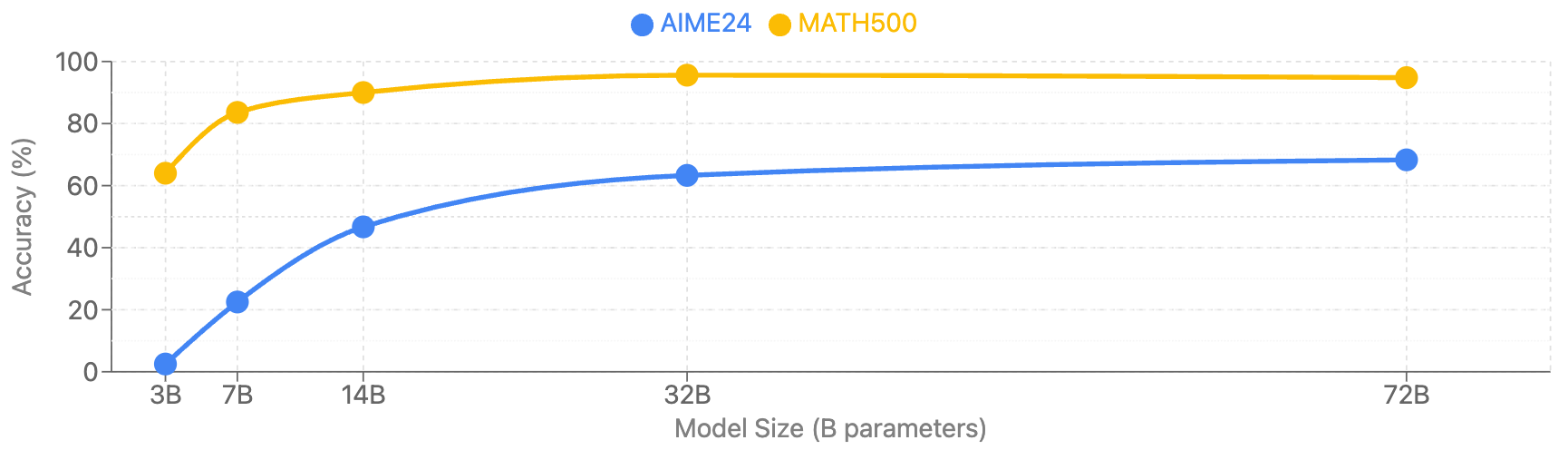
Figure 3: This figure illustrates how mathematical reasoning ability scales with model size across different benchmarks, revealing the performance gains from increasing model parameters.
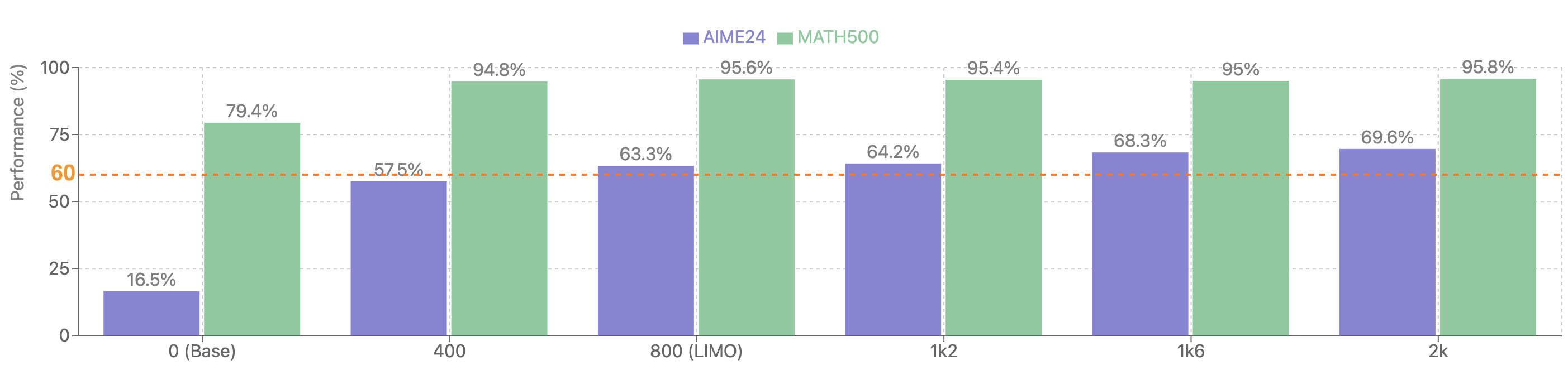
Figure 4: This graph shows the impact of dataset size on model performance, demonstrating diminishing returns beyond a certain number of high-quality samples.
Implications and Future Directions
This work has significant implications for the development and deployment of LLMs, suggesting that focusing on data quality and strategic example selection can lead to more efficient and effective reasoning capabilities. The LIMO Hypothesis provides a valuable framework for understanding how to elicit complex reasoning from LLMs, paving the way for future research in data-efficient learning and the development of more capable and resource-efficient AI systems. Future work could explore active learning strategies to further optimize sample efficiency and investigate the applicability of LIMO principles across different tasks and domains.
Conclusion
The paper demonstrates that complex mathematical reasoning in LLMs can be achieved with surprisingly few examples by confirming the LIMO Hypothesis: in knowledge-rich foundation models, sophisticated reasoning emerges through minimal but precisely orchestrated demonstrations that effectively utilize inference-time computation.