- The paper introduces a novel training-free, document-centric pipeline that synthesizes diverse QA pairs from text segments.
- The methodology employs prompt engineering, semantic role transformations, and counterfactual reasoning to enhance QA pair quality and diversity.
- Experimental results demonstrate improved SFT performance over traditional and human-curated datasets across multiple domains.
D-SCoRE: Document-Centric Segmentation and CoT Reasoning with Structured Export for QA-CoT Data Generation
Introduction
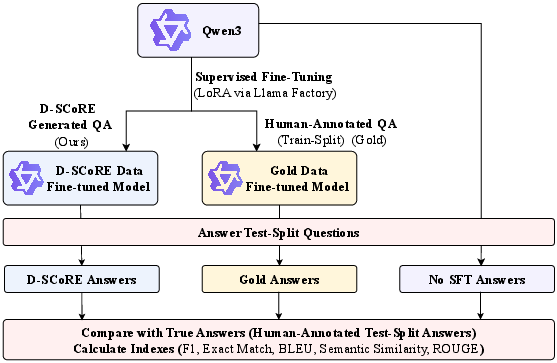
The paper "D-SCoRE: Document-Centric Segmentation and CoT Reasoning with Structured Export for QA-CoT Data Generation" presents a novel approach aimed at generating high-quality, diverse question-answering (QA) datasets without reliance on annotated corpora. Question-answering datasets are crucial for the supervised fine-tuning (SFT) of LLMs across various domains such as healthcare and education. The manual annotation process required to generate these datasets, however, is labor-intensive and expensive, which hinders scalability.
Existing automated approaches for QA data generation are classified into non-synthetic and semi-synthetic methods. Non-synthetic methods rely heavily on previously annotated sources and lack scalability, while semi-synthetic methods are hampered by complex preprocessing and limitations in controlling question diversity and complexity. The proposed D-SCoRE pipeline overcomes these limitations by employing prompt engineering strategies with LLMs to produce diverse, high-quality datasets directly from textual sources. This pipeline integrates multiple-dimensional control mechanisms such as semantic role transformations and counterfactual reasoning to enhance the generated datasets' relevance and diversity, thereby enabling effective domain-aware SFT.

Figure 1: Overview of D-SCoRE.
Methodology
D-SCoRE comprises a training-free, three-stage core pipeline engineered for simplicity, scalability, and adaptability across domains. This pipeline is reinforced with multi-dimensional control mechanisms to assure the variety, precision, and domain-relevance of the generated datasets while mitigating common issues like hallucinations.
Core Pipeline
- Stage 1: QA Generation - This stage uses LLMs to synthesize diverse QA pairs from individual text segments. Prompt engineering techniques guide the LLM to create explicit questions from retrievable factual elements and implicit questions that require inferential reasoning.
- Stage 2: QA Quality Control - Rigorous quality control ensures the generated QA pairs maintain fidelity to the source text and are correctly categorized as explicit or implicit. Prompt-engineered LLMs cross-validate these attributes against the source material.
- Stage 3: Counterfactual Material Generation - Counterfactual alternatives are created for each QA pair to further dataset sophistication. Each question is accompanied by distractor alternatives generated from the source text to simulate realistic but incorrect answers.
Multi-Dimensional Control Mechanisms
- Question Type Control - This dimension enforces balanced explicit and implicit question distributions to maintain variation in interrogative depth.
- Diversity Enhancement - Incorporates semantic role transmutations and counterfactual distractor generation to introduce linguistic and semantic variety, optimizing the dataset's effectiveness.
- Quality Assurance - Ensures all QA pairs emanate from the input text and are accurately classified, maintaining the dataset's fidelity and reducing anomalies.
Experiments
Empirical evaluations examined the D-SCoRE pipeline using SQuAD and Covid-QA datasets, benchmarking its performance against traditional methodologies. The primary research questions address:
D-SCoRE demonstrated improved SFT outcomes across various domains over conventional and human-curated QA datasets. Notably, configurations with implicit question predominance yielded performance improvements across diverse datasets such as Amazon reviews, NYT articles, and Reddit posts. However, domain-specific complexity, as observed in scientific prose like Covid-QA, revealed areas for optimization regarding reasoning trace integration and extended context windows.
Conclusion
D-SCoRE systematically addresses inadequacies in current QA dataset generation methods through an innovative pipeline that produces high-quality, diverse, and multi-domain relevant datasets. The empirical validation demonstrated its practicality and superiority over traditional methods, facilitating model refinement across multiple domains. Future explorations may enhance D-SCoRE by investigating various model architectures, dataset compositions, and extending its applicability to new domains, thus advancing automated QA generation in NLP.