- The paper introduces SciDQA, a dataset featuring 2,937 expert-curated QA pairs extracted from peer reviews to assess LLM comprehension of scientific literature.
- It employs a meticulous curation process combining LLM-based extraction with expert annotation to handle multi-modal content and reasoning challenges.
- Experimental results indicate that even advanced LLMs like GPT-4o face difficulties with multi-document and multi-modal reasoning tasks presented by the dataset.
SciDQA: A Deep Reading Comprehension Dataset over Scientific Papers
Introduction
The paper introduces SciDQA, a dataset designed to challenge LLMs with deep reading comprehension tasks, specifically within the domain of scientific literature. This dataset consists of 2,937 high-quality question-answer (QA) pairs. It stands out from existing QA datasets by sourcing questions from peer reviews authored by domain experts and answers provided by paper authors, ensuring a thorough engagement with scientific texts.
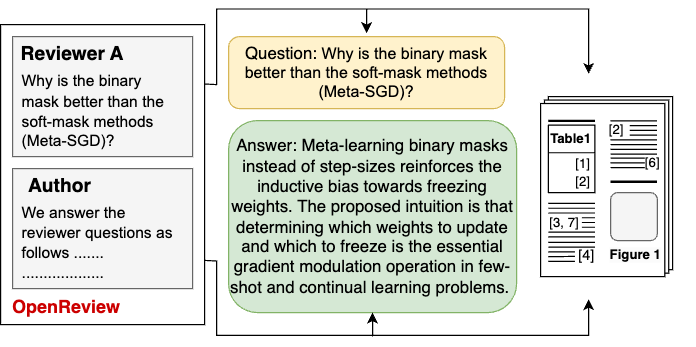
Figure 1: An instance in the SciDQA dataset. The question and answer corresponding to the paper are extracted from the reviewer-author discussion on OpenReview.
Dataset Creation and Curation
SciDQA's dataset curation involves capturing QA pairs from reviewer-author discussions available on OpenReview. A significant feature of this dataset is its focus on ML-domain articles. Questions extracted from peer reviews reflect the reviewers' need for clarity or further explanation, marking them as an excellent source for probing comprehensive understanding of research papers. An extensive manual annotation process is employed to maintain high relevance and quality, consisting of human expert annotation and editing.
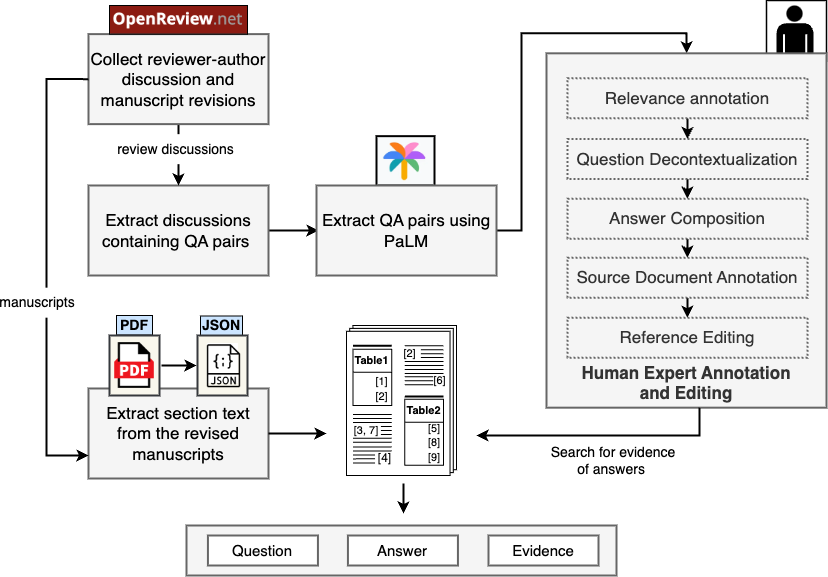
Figure 2: Dataset curation pipeline for SciDQA. LLM-based QA extraction from peer reviews is followed by a comprehensive human expert annotation and editing.
Challenges Presented by SciDQA
The questions in this dataset necessitate reasoning across multi-modal content within papers, such as figures, tables, and equations. Approximately 11% of the questions require reasoning over references to multiple documents. This dataset presents a considerable challenge for LLMs, pushing the boundaries of current capabilities by requiring the generation of factual and relevant responses.
Experimental Evaluation
Performance evaluation of several open-source and proprietary LLMs has been conducted using this dataset across different configurations, including closed-book settings and retrieval-augmented generation (RAG). The results highlight discrepancies in LLM performance, with proprietary models like GPT-4o showing notably robust performance compared to open-source counterparts. This suggests a potential gap in handling nuanced scientific inquiry when context is provided.
Implementation Challenges
Implementing the SciDQA dataset in practical applications requires handling computational resources effectively, especially given the multi-modal nature and context length associated with full-text scientific literature. Moreover, ensuring that models can perform inferential reasoning across multiple documents is critical. The RAG approach implemented for this dataset provides a baseline strategy to selectively focus on the most relevant sections of a document, enhancing comprehension.
Limitations and Future Directions
A major limitation of SciDQA is the potential exclusion of certain documents necessary for answering multi-document questions, affecting the dataset's completeness in challenging LLMs in real-world scenarios. Future work would entail expanding the dataset to encompass multi-disciplinary scientific fields beyond ML, as well as improving multimodal analysis capabilities in LLMs.
Conclusion
SciDQA provides an effective testbed for evaluating deep comprehension capabilities of LLMs on scientific texts. By utilizing peer review-derived questions and answers, it ensures engagement with complex and domain-specific content, promoting advancements in the understanding of scientific materials by AI systems.