- The paper introduces RLVER, a reinforcement learning framework that leverages verifiable emotion rewards to train LLMs for empathetic dialogue.
- It employs self-consistent affective user simulators and a 'Think-Then-Say' approach to improve reasoning and empathetic response quality.
- Empirical results demonstrate significant advances in empathy, insight, and dialogue capability, achieving scores comparable to proprietary models.
RLVER: Reinforcement Learning with Verifiable Emotion Rewards for Empathetic Agents
Introduction
The paper introduces RLVER, a reinforcement learning framework designed to improve the emotional intelligence of LLMs with verifiable emotion rewards. It aims to address the limitations of LLMs in empathetic dialogue by enhancing their ability to understand and respond to human emotions. The framework employs self-consistent affective user simulators to generate deterministic emotion scores that serve as reward signals for training LLMs.
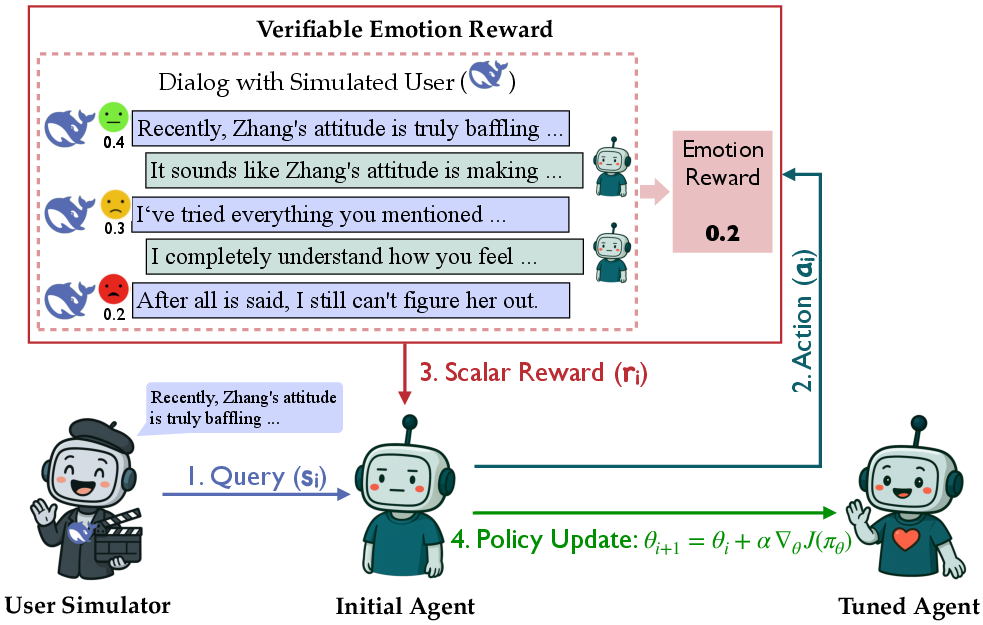
Figure 1: Framework of the reinforcement learning with verifiable emotion rewards (RLVER).
Reinforcement Learning Framework
RLVER utilizes Proximal Policy Optimization (PPO) to train LLMs within an environment powered by affective user simulators. These simulators engage in dialogue with LLMs, updating their emotional states after each interaction. The updated emotion scores provide feedback that trains the LLM to respond empathetically.
Emotion Rewards and User Simulation
At the core of RLVER is the Sentient Agent framework, which simulates human-like emotional responses and reasoning based on predefined personas and goals. The agent's responses and emotional states evolve throughout the conversation, and the process is structured to support realistic dialogue simulations. By providing deterministic and verifiable emotion scores, RLVER circumvents the problem of reward hacking often encountered in neural reward models.
Impact of Training Templates
The framework assesses LLM behavior using two distinct prompting formats: "Think-Then-Say" and direct reply templates. The "Think-Then-Say" format encourages the model to engage in explicit reasoning before generating a response, which has been shown to enhance higher-order empathetic skills.
The empirical evaluation demonstrates significant improvements in several dimensions of dialogue capability, including empathy, insight, and action orientation. Using the Sentient Benchmark, RLVER-trained models attain scores comparable to those of proprietary LLMs, showcasing a substantial improvement in emotional support dialogue tasks.
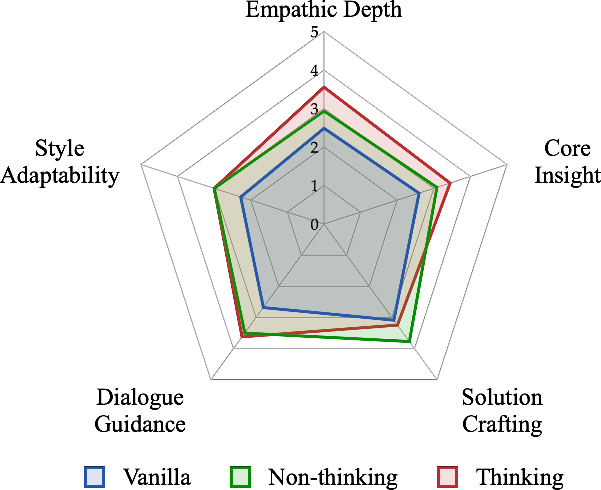
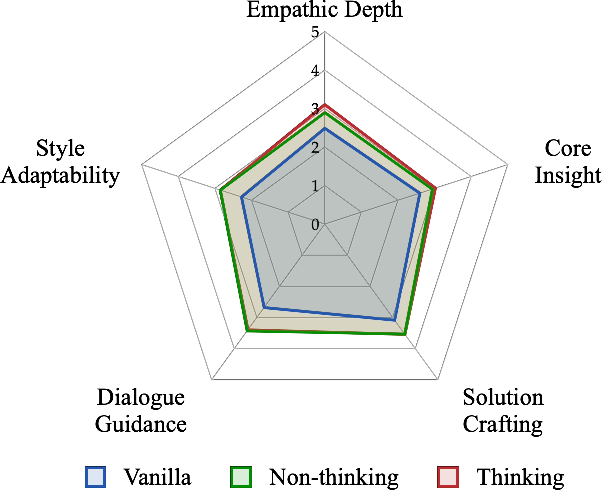
Figure 2: Qualitative analysis of five core capabilities of the trained models.
Strategy Utilization
Analyzing the frequency and contribution of empathetic strategies reveals that models trained with RLVER gradually adopt more sophisticated approaches. These strategies are crucial for achieving genuine emotional understanding and providing tailored responses.
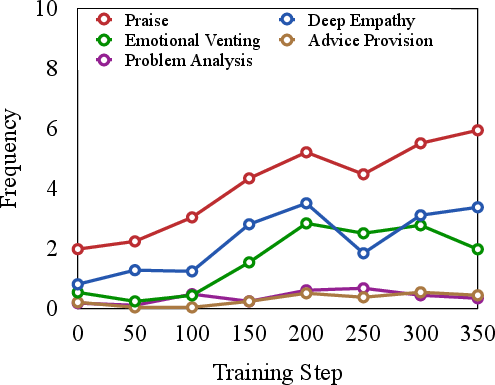
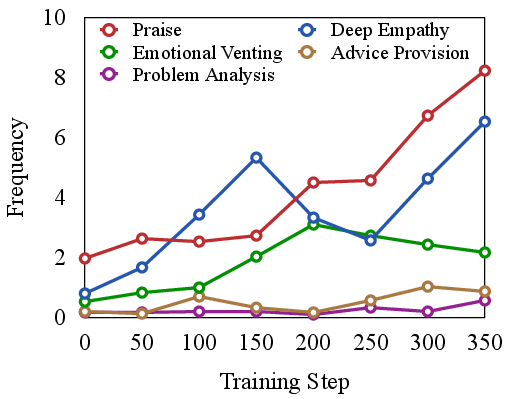
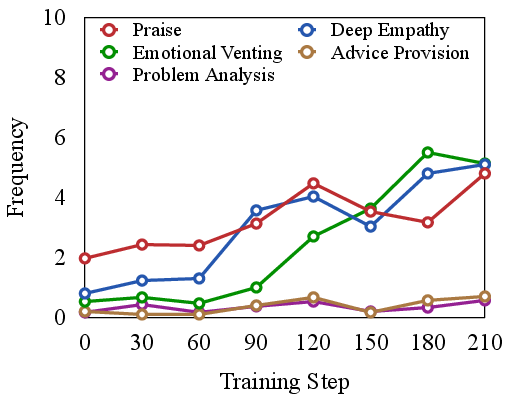
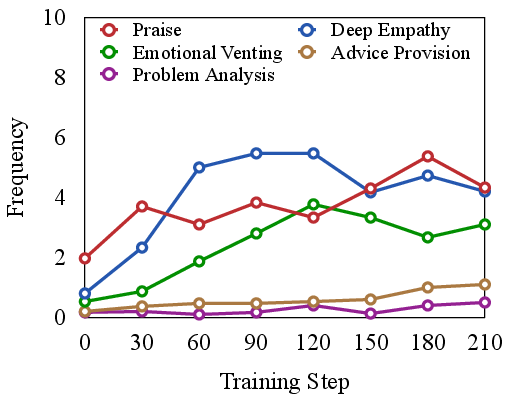
Figure 3: Frequency of empathetic strategies during the training.
Stability and Trade-offs
While PPO facilitates exploratory updates that refine capabilities over time, GRPO offers stable improvements, illustrating a trade-off between stability and performance ceiling. The framework effectively balances exploration and exploitation, ensuring the growth of complex empathetic strategies while maintaining core linguistic competencies.
Learning Dynamics in Social Interaction
RLVER models undergo a distinct shift from solution-centric to empathy-oriented interactions. This transformation in behavior is evaluated using the Social Cognition Coordinate, which provides insight into the model's style and empathy orientation after training.
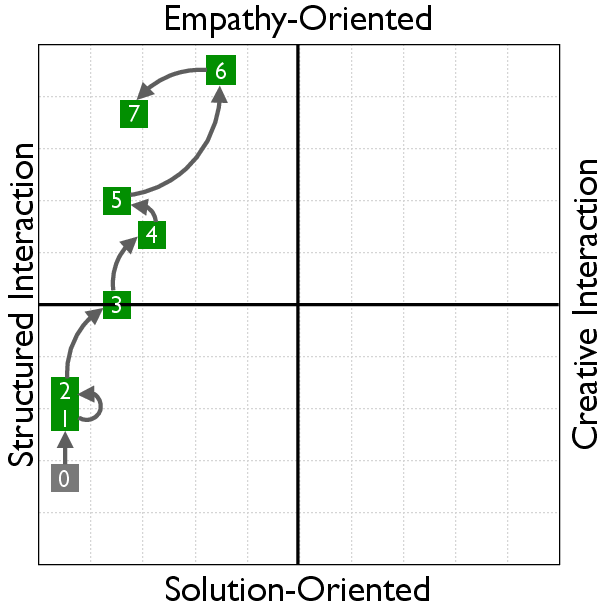
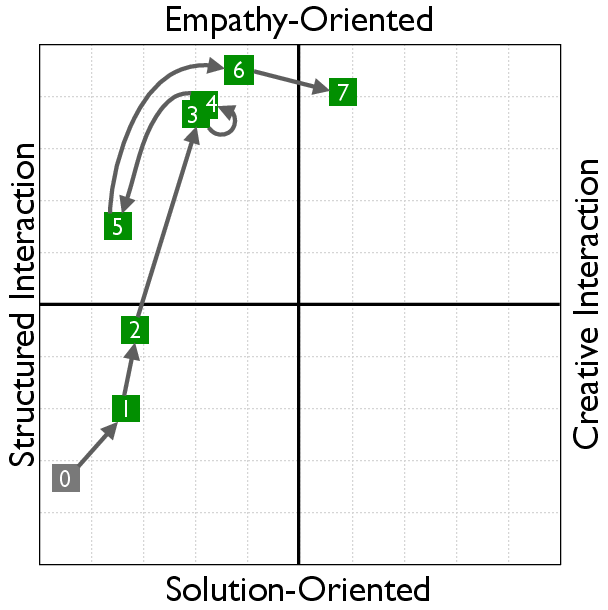
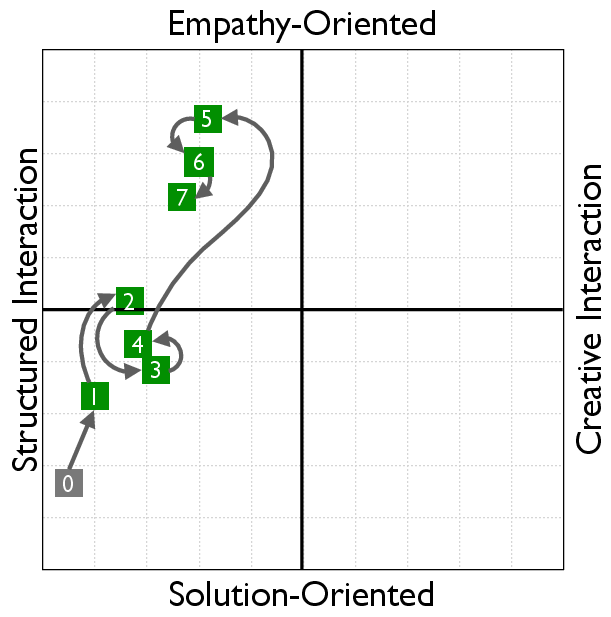
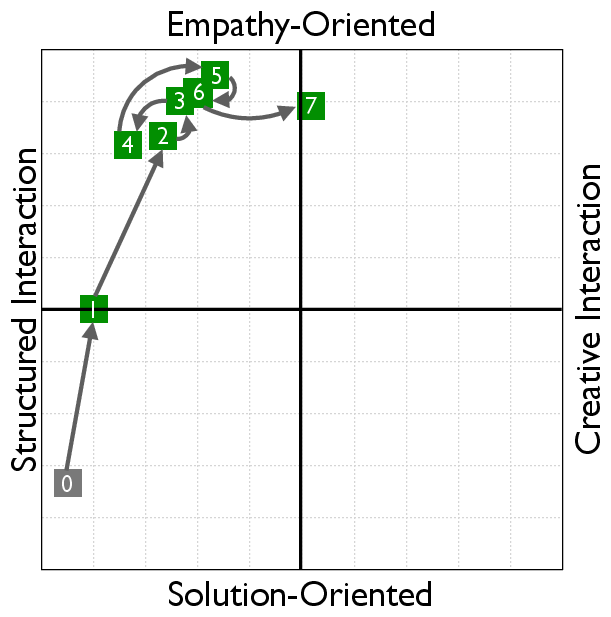
Figure 4: Learning curves in the Social Cognition Coordinate (SCC).
Conclusion
RLVER represents a practical and scalable approach for enhancing the emotional intelligence of LLMs. By grounding reward signals in verifiable emotion scores from sophisticated user simulators, the framework achieves balanced growth across empathetic competencies while still addressing practical dialogue requirements. Future research could explore further integration of multimodal affective cues and adaptive persona switching to achieve holistic conversational intelligence.