- The paper introduces the AvaMERG dataset and Empatheia system to benchmark multimodal empathetic response generation.
- It employs a Chain-of-Empathy reasoning mechanism with synchronized text, speech, and visual modules to enhance emotion alignment.
- Empirical results demonstrate significant improvements in emotion accuracy, dialogue diversity, and modality consistency over prior models.
Towards Multimodal Empathetic Response Generation: An Expert Analysis of AvaMERG and Empatheia
Introduction
The pursuit of Empathetic Response Generation (ERG) has traditionally centered on text-only interfaces, a limitation that fails to capture the inherently multimodal nature of human emotion. The paper "Towards Multimodal Empathetic Response Generation: A Rich Text-Speech-Vision Avatar-based Benchmark" (2502.04976) presents the first benchmark and system for Multimodal Empathetic Response Generation (MERG), introducing both the AvaMERG dataset and the Empatheia system. These contributions systematically address the semantic alignment, emotional congruence, and style consistency required for high-quality multimodal empathetic interactions.
A succinct example of the proposed scenario demonstrates the depth and necessity of multimodal grounding for empathy:

Figure 1: A snippet of avatar-based Multimodal Empathetic Response Generation (MERG) with rich multimodal signals: text (dialogue), audio (acoustic speech) and vision (dynamic talking-head avatar).
The AvaMERG Benchmark
Design and Construction
AvaMERG establishes the task of MERG by extending textual ERG with rich speech and dynamic talking-head video, containing synchronized text, audio, and vision. The dataset construction process is methodologically robust, emphasizing diversity (age, gender, tone, race), emotional coverage (32 fine-grained textual, 7 coarse-grained multimodal emotions), and high annotation fidelity through multi-stage human validation.
The scale and annotation schema are summarized visually:
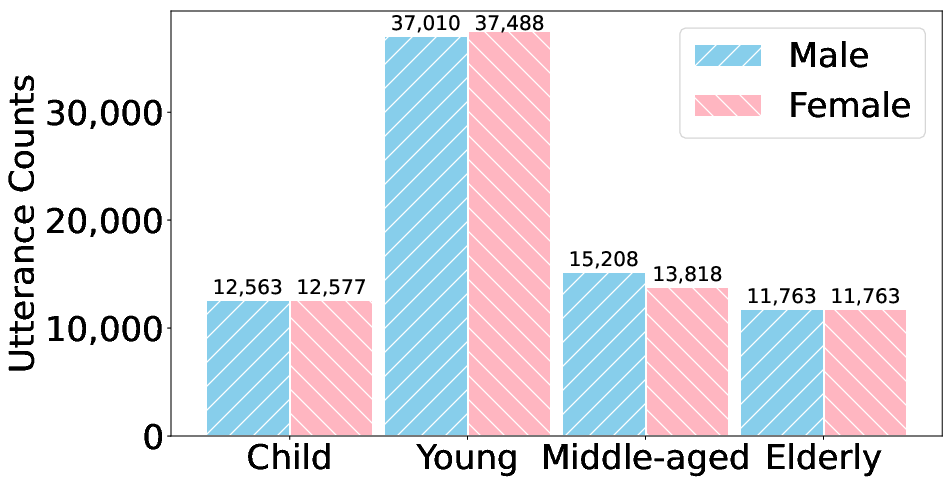
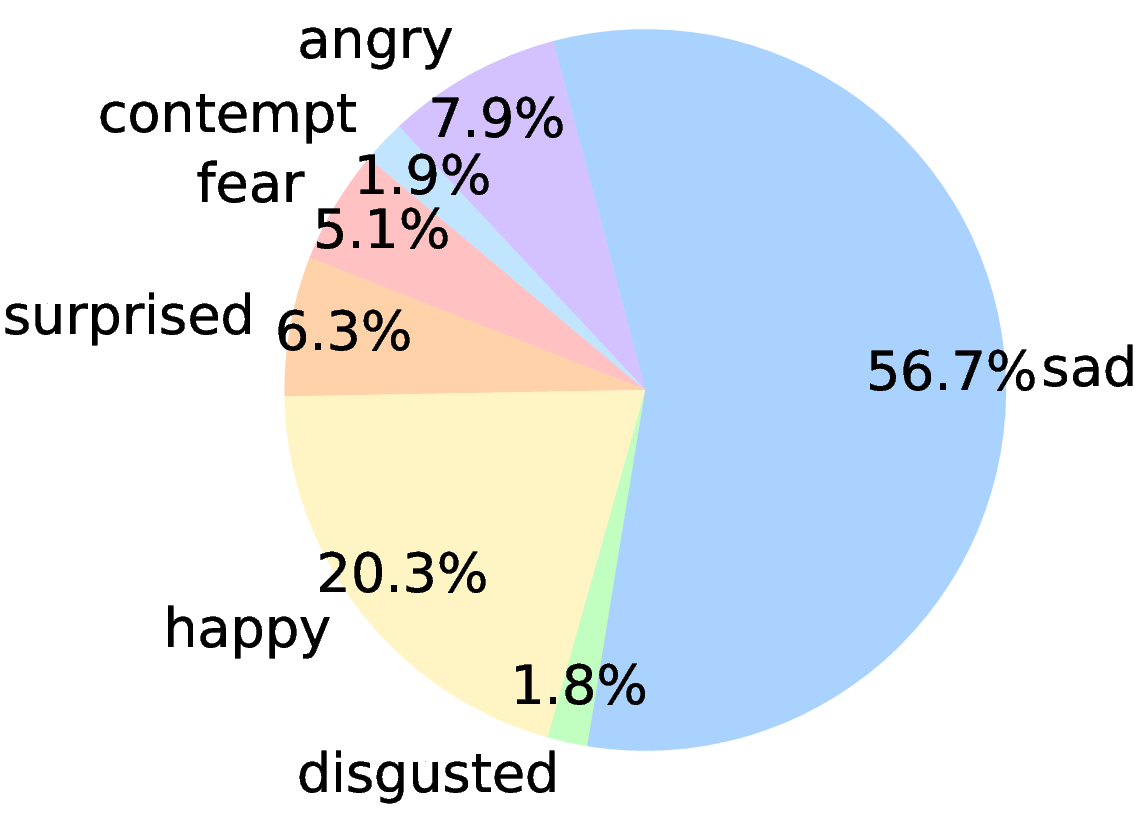
Figure 2: Visualized statistics of AvaMERG dataset.
Specific design choices, such as recruiting volunteers to capture facial and audio signals and using GPT-4 for meta-label generation and balancing, ensure real-world complexity and high inter-annotator agreement (Cohen’s κ = 0.78). The dataset comprises 33,048 dialogues and 152,021 utterances, systematically co-indexed across modalities and annotated for scenario, profile, and emotion.
Dataset Analysis
AvaMERG supports experimental validation for diverse and challenging conditions, e.g., cross-demographic dialogue alignment, fine-grained emotion classification, and topic-sensitive reasoning (Figure 3 and Figure 4):
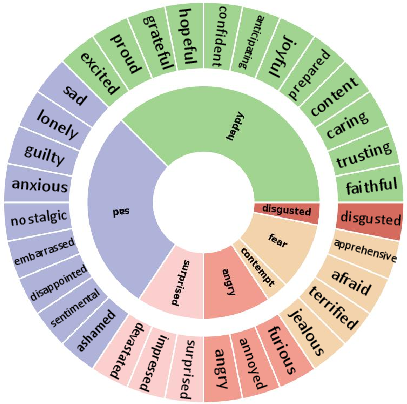
Figure 3: The mapping of fine-grained textual emotions to coarse-grained multimodal emotions.
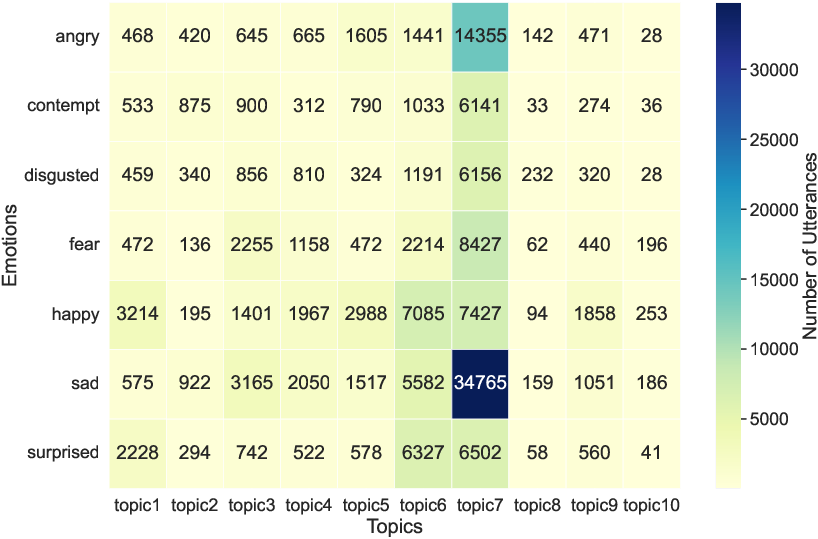
Figure 4: Emotion-topic heatmap for dialogue utterances. Topics 1–10 represent diverse real-world conversational contexts.
The dataset thus enables fine-grained error analysis along axes such as age, gender, tone, emotion, and real-world dialogue scenario.
The Empatheia MERG System
System Architecture
Empatheia is architected as a fully end-to-end Multimodal LLM (MLLM) integrating multimodal encoding, a core LLM-based empathetic reasoner, and modular generators for speech and avatar synthesis.
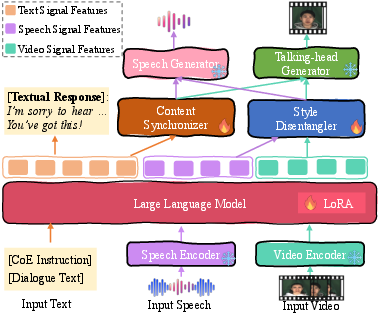
Figure 5: Architecture of our Empatheia MLLM for MERG.
Multimodal comprehension is achieved through HuBERT (audio), CLIP ViT-L/14@336px (video), and Vicuna as the LLM backbone. The front-end encoders project all signals into a language-centric semantic space via continuous embeddings, facilitating coherent and synchronized feature representations across modalities.
Chain-of-Empathy Reasoning
Empatheia incorporates a Chain-of-Empathy (CoE) mechanism to promote interpretable, multi-step empathetic reasoning, adapting the Chain-of-Thought paradigm to affective computing. CoE decomposes response generation into the event scenario, user emotion recognition, emotion causality inference, response intent, and ultimate empathetic articulation—a sequence necessary for robust multimodal empathy alignment.
Multimodal Generators and Consistency Modules
Empatheia leverages StyleTTS2 for high-fidelity, emotion-conditioned speech generation and DreamTalk for expressive, tightly synchronized talking-head avatar videos.
To combat modality drift and enforce synchrony, two modules—the Content Synchronizer (CS) and Style Disentangler (SD)—mediate the interface between core LLM representations and downstream generative modules.
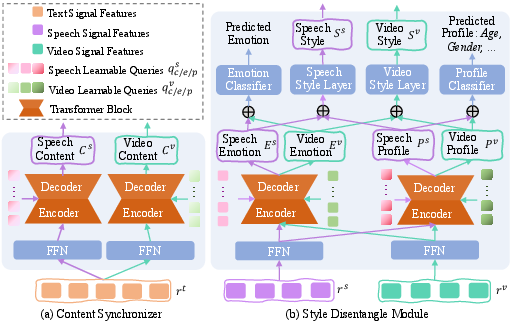
Figure 6: Illustration of the Content Synchronizer and Style Disentangle modules.
- CS ensures semantic and textual information is propagated consistently into speech and visual generators, using transformer-based VAEs with learnable queries for each modality.
- SD disentangles emotion and profile features, ensuring emotion is rendered congruently in both audio and video, while allowing for profile-conditioned style (e.g., age, gender, tone, appearance).
Empathetic-enhanced Training Strategies
A suite of staged training strategies underpins Empatheia:
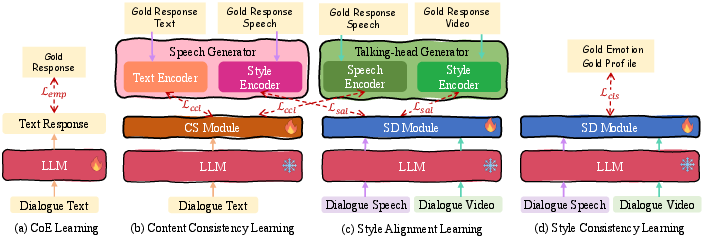
Figure 7: Illustrations of the proposed training strategies.
- Supervised CoE reasoning for step-wise empathy induction
- Content consistency learning via embedding alignment
- Style alignment and consistency learning with discriminative emotion/profile losses
- End-to-end joint optimization balancing all objectives
This multi-phase regime is crucial for mitigating modality mismatch, error propagation, and profile-style divergence, all of which are acute in multimodal generative cascades.
Experimental Results
State-of-the-art baselines are surpassed across all metrics—emotion accuracy, response diversity (Dist-1, Dist-2), and modality-specific fidelity for both text-only and multimodal tasks. For textual ERG:
| Model |
Acc |
Dis-1 |
Dis-2 |
| KEMP |
35.87 |
0.41 |
1.78 |
| CEM |
37.32 |
0.50 |
2.07 |
| CASE |
40.96 |
0.54 |
2.14 |
| Empatheia |
48.51 |
2.69 |
14.76 |
Empatheia yields substantial improvements, demonstrating that synchronizing modalities and reasoning steps produces measurably more empathetic and diverse dialogue.
In multimodal domains, Empatheia achieves higher MOS/SMOS, CPBD, SSIM, and SyncNet confidence than both pipeline and ablation baselines, demonstrating its superiority in both generative quality and modality alignment.
Human Evaluation
Empatheia sustains its lead in manual evaluation (Empathy, Coherence, Informativity, Fluency for text; Content and Style Accuracy, Consistency for multimodal), with ablated models and pipelines trailing consistently—highlighting the necessity of full-system integration.
In-depth Analysis and Ablations
Fine-grained analysis reveals strong emotion, age, and gender-classification accuracy, with model sensitivity highest for sadness and ablation studies confirming the necessity of the SD and CS modules (Figure 8, Figure 9):
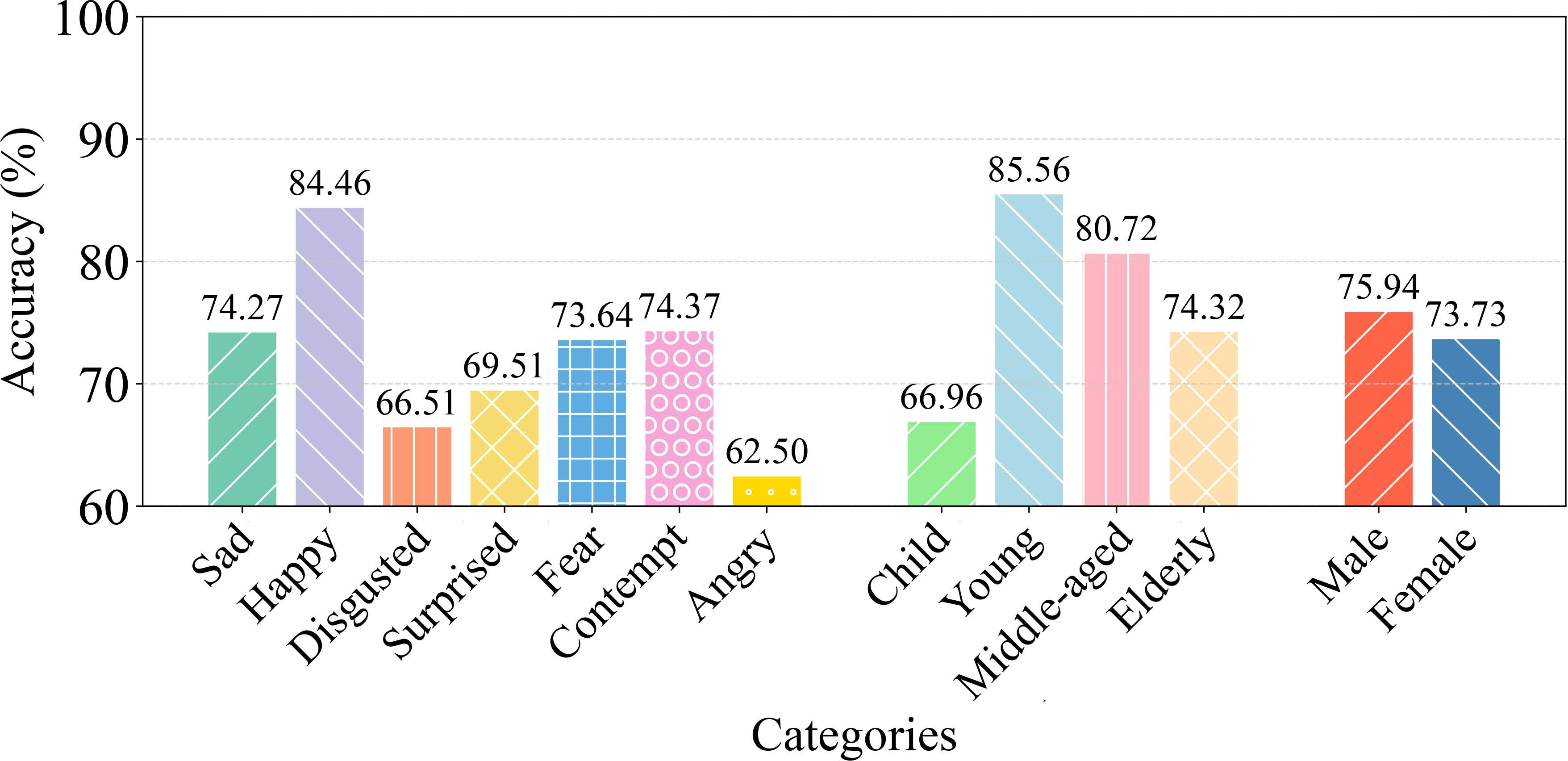
Figure 8: Results on various emotions, ages, and genders.

Figure 9: T-SNE visualization of emotion and profile features.
Further experiments explore the sensitivity to model capacity, special token design, and dataset volume (Figure 10 through Figure 11), and establish robust benefits for the CoE strategy at all intermediate stages (Figure 12).
Qualitative Case Studies
Representative case analyses manifest the importance of coordinated step-wise empathy and cross-modal style consistency. In challenging scenarios—ambiguous textual cues but clear emotional audio-visual content—Empatheia infers latent sentiment, maintains consistent affect across modalities, and correctly conditions profile attributes.
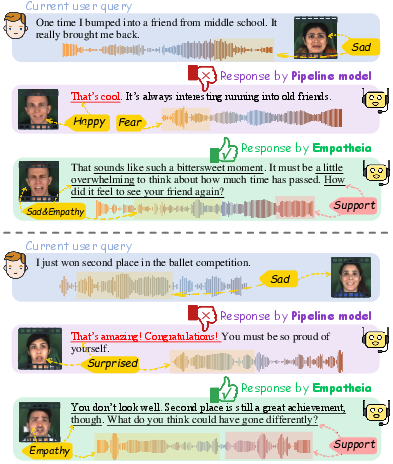
Figure 13: Qualitative results of two testing instances.
Additional studies (Figures 17–24) generalize these findings across diverse dialogue configurations and demonstrate the system's stability and controllability.
Implications and Future Directions
The introduction of AvaMERG and Empatheia operationalizes and benchmarks the MERG task at a granular, technically rigorous level. Practically, this accelerates progress toward conversational agents suitable for domains necessitating precise affective alignment, e.g., psychological counseling, elder care, and emotionally sensitive HCI.
Theoretically, this work motivates future studies on:
- Unifying additional modalities (e.g., gesture, gaze)
- Cross-cultural and cross-lingual empathy
- Generalization to long-horizon, multi-turn discourse
- Efficient co-training strategies or efficient self-supervised learning for high-dimensional modalities
as well as rigorous, multidimensional evaluation protocols sensitive to both surface and latent empathetic constructs.
Conclusion
Through the AvaMERG dataset and the Empatheia system, this paper establishes a rigorous methodology, evaluation platform, and suite of algorithmic techniques for Multimodal Empathetic Response Generation. The analysis demonstrates that end-to-end training, step-wise empathetic reasoning, and explicit cross-modal synchronization are necessary for robust, high-fidelity multimodal empathetic interaction. As research in affective computing and multimodal dialogue advances, this benchmark and methodology will remain central for the development and evaluation of genuinely emotionally-aligned AI systems.