- The paper introduces a holistic tokenizer that uses learnable queries to fuse global image attributes with local patches, enhancing AR synthesis quality.
- It leverages semantic features from models like DINOv2 to infuse a global context into the tokenization process for coherent image generation.
- Empirical results on ImageNet show faster convergence along with improved style transfer and inpainting performance, evidenced by superior FID and IS scores.
Holistic Tokenizer for Autoregressive Image Generation
The paper "Hita: Holistic Tokenizer for Autoregressive Image Generation" (2507.02358) presents a novel tokenizer designed to enhance autoregressive (AR) image generation models by addressing the limitations imposed by traditional tokenization approaches. It introduces a sophisticated holistic-to-local tokenization scheme, aiming to bridge the gap between local image patches and global context, thereby improving image synthesis quality and efficiency.
Introduction
Autoregressive models have profoundly impacted NLP fields, with models such as GPT yielding remarkable performance due to their robust sequential prediction capabilities. These successes have prompted exploration into applying AR methodologies in image generation tasks. Existing models, including DALL-E and LlamaGen, utilize tokenizers, often based on VQVAE, to transform images into discrete tokens suitable for AR models. However, these tokenizers typically focus on local patches and neglect holistic information crucial for global coherence, which hampers the performance of AR models in generating semantically consistent images.
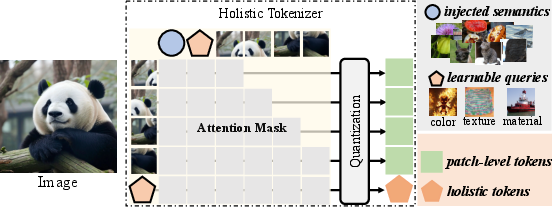
Figure 1: The concept of holistic tokenizer. A set of learnable queries that capture global properties, such as color, texture, material, etc., from pixels, with semantic-level feature injected, is utilized to reconstruct the image along with image patches.
Holistic Tokenization Methodology
The cornerstone of the Hita tokenizer is its innovative use of learnable queries to extract holistic image representations. These queries are integrated with semantic-level features from foundational models like DINOv2, ensuring the synthesis of a globally coherent latent token sequence. Subsequently, these holistic tokens are arranged sequentially before patch-level tokens, aligned to the causal nature of AR models using causal attention mechanisms. This strategic ordering controls the information flow and prioritizes holistic tokens during generation.

Figure 2: Holistic tokens capture the global style and content information, enabling style transfer and zero-shot image inpainting, while accelerating training speed.
The design involves a series of steps, starting with the encoding of input images into patch embeddings, processing through transformers, and the inclusion of pre-trained semantic features. This process culminates in a sequential structure where holistic information serves as a prefix to guide subsequent patch token generation, outlined in the flowchart presented in the paper.
Empirical Evaluation and Results
Extensive experiments validate the efficiency of Hita over traditional tokenizers in both training speed and image quality. On the ImageNet benchmark, Hita exhibits superior performance metrics including a FID score of 2.59 and an IS of 281.9. The holistic approach notably enhances zero-shot style transfer and inpainting capabilities, demonstrating transferability of global style and content features across varied image contexts without additional task-specific training.
Moreover, Hita significantly accelerates convergence during training, achieving desired FID levels twice as fast as comparable models. This efficiency stems from the streamlined tokenization process that merges holistic prompts and local details effectively, ensuring robust semantic guidance throughout the generation process.
Discussions and Implications
The ability of Hita to generate holistic tokens that encapsulate global features like shape and texture is critically assessed through qualitative and quantitative inpainting assessments. These tokens yield consistently coherent image completions even when only partial inputs are provided, outperforming baseline models that struggle with maintaining semantic consistency.
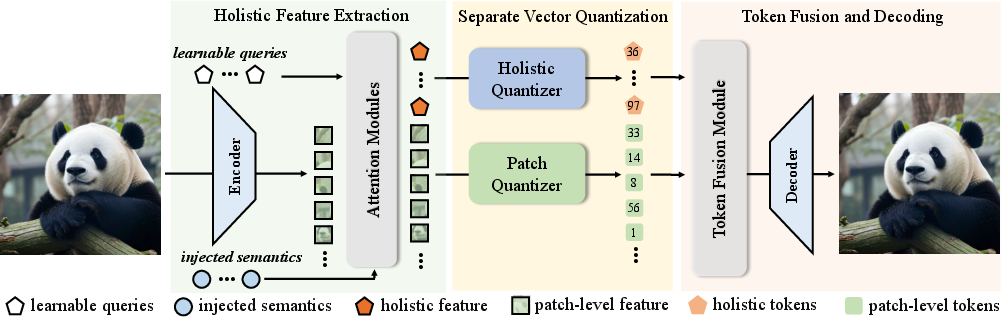
Figure 3: The flowchart of the proposed holistic image tokenizer, including holistic feature extraction, separate vector quantization, and token fusion for image reconstruction.
Looking ahead, the Hita tokenizer showcases promising potential for enhancement in AR image generation models through better alignment with the causal frameworks inherent in LLMs. Its seamless integration into existing AR architectures paves pathways for future advancements in semantic-rich image synthesis, potentially expanding into text-conditional generation formats.
Conclusion
Hita introduces a transformative approach to tokenization within AR image generation, tackling the core issue of limited holistic representation in current models. Through a blend of learnable queries and advanced semantic injections, it elevates both the efficiency and quality of image synthesis. Its demonstrated success in style transfer and inpainting further underscores the value of incorporating holistic perspectives within autoregressive frameworks. As research in AI continues to evolve, approaches like Hita offer critical insights into enriching the semantic understanding and generation capabilities of complex models.

